移动性能测试 机器学习技术在 App 启动测试中的一次尝试
背景
app 启动时间是一个常规的性能测试指标,通常在 app 启动过程中研发会加入一些耗时的数据预处理过程。但优化不好的情况下可能严重影响着 app 的用户体验。
常规的测试方法通常有
- adb shell am start -W [packageName]/[packageName.MainActivity] 获取各种启动时间,通过这种方式可以完全自动化执行,不需要人工干预,但这种方法的结果准确性一直被质疑。
- 最权威也是最蛋疼的测试方法是用摄像头录制应用启动的完整过程,然后分析视频文件计算时间差来获取应用启动时间。但这种测试方法极不优美,操作步骤繁琐,费时又费力。
基于此我参考了前人的经验后利用机器学习领域的图像识别技术自动识别出来首页的那一帧,代替人眼识别。
思路
- 训练图像识别模型,并固化
- 编写脚本启动 app 并录制启动过程存储视频文件
- 解析视频文件,使用训练好的模型识别出每一帧的标签。直到识别到首页标签。
- 计算首页帧在总帧数的位置计算出相应时间。
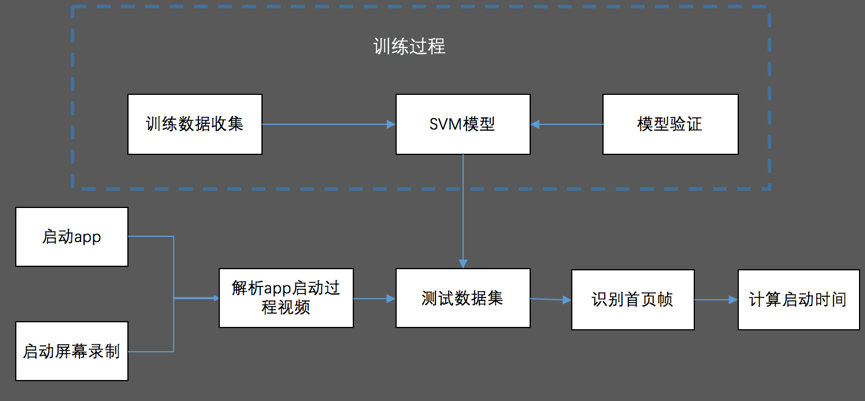
图 1:app 启动测试框架图
模型训练
目前比较流行的机器学习框架有 TensorFlow 和 Scikit-learn,由于不涉及到深度学习,所以就选择了简单强大的 Scikit-learn。
Scikit-learn 配置很简单直接使用 python 的 pip 命令安装所需的依赖包即可。
训练数据的组成
通常的 app 启动过程为:桌面-applogo 页 - 内容加载页(通常为白色)- 首屏页面。因此需要分别获取这几个过程的截图信息存放到对应的文件夹下,文件夹命名为对应的 labal 名称。在这三个分类中首页的变化是最大的,因此此类的训练图片最多。最终三个分类总共 200 张训练图片。补充一点:标签分类的越细致,对分类识别结果更有帮助。
模型的选择
本质上这是一个典型的图像识别问题,因此选择了 SVM 模型训练数据,通过有监督学习,建立图像和 labal 之间的对应关系。但对于 SVM 中几种常用的模型究竟如何选择我们还需要看最终的测试结果
训练图像处理
在本次测试中使用的手机分辨率为 1080*1920,因此截取的图像都为该尺寸的彩色 RGB 图。当训练数据非常多时训练时间会非常长,因此对图像进行 1/8 的裁剪。从结果看裁剪后的图像并未影响分类结果,但可以大幅缩减训练时间。
模型训练的代码如下:
from sklearn.externals import joblib
from PIL import Image
import numpy as np
import os
from sklearn import svm
def get_train_image_datas():
label_list = []
image_list = []
image_classes = os.listdir("image_training")
for classes in image_classes:
if classes == ".DS_Store":
continue
image_dir = os.getcwd() + '/image_training/' + classes
for image_path in os.listdir(image_dir)[:-1]:
if image_path.endswith(".jpg"):
img = Image.open(image_dir+"/"+image_path)
# 获得图像尺寸:
w, h = img.size
# 缩放到1/8:
img.thumbnail((w // 8, h // 8))
image_list.append(np.asarray(img).flatten())
label_list.append(classes)
return image_list, label_list
def training_model():
tr_img, tr_label = get_train_image_datas()
linear_svcClf = svm.LinearSVC()
linear_svcClf.fit(tr_img, tr_label)
joblib.dump(linear_svcClf, "model/linear_svcClf_train_model.m")
svcClf = svm.SVC()
svcClf.fit(tr_img, tr_label)
joblib.dump(svcClf, "model/svcClf_train_model.m")
至此模型就完全训练好了,但我们还要针对模型的正确性进行测试。
我们对 SVM 的 SVC 和 LinearSVC 进行了对比,在测试的过程中发现 LinearSVC 训练的准确率要明显高于 SVC,LinearSVC 的正确率可以在 95% 以上,SVC 模型无法区别出这几种类别的图像,把所有测试图像都识别为了首页图。
如图所示:

图 2:LinearSVC 和 SVC 结果比较
万事俱备开始测试
屏幕录制
android 屏幕录制大家可能会首选
adb shell screenrecord --verbose --time-limit 10 /sdcard/demo.mp4
screenrecord 是 adb 自带录制命令,使用简单便捷经常被用于录制 bug 复现过程。
但我在使用 screenrecord 命令录制视频时发现一个奇怪的问题,视频的 fps 总是变动的,并且当屏幕处于静止状态时只能录制每秒 10 帧的视频。这样就会导致视频的帧率是起伏不定的,按照视频显示的 fps 算出来的首页帧时间总是与视频的实际时间对不上。
于是我不死心,想到既然有这么多录屏的 android 软件,也许效果会更好,还好在 Android 5.0,Google 开放了视频录制的接口,利用 MediaProjection 和 MediaProjectionManager 可以进行实时的屏幕采集。 详细的实现可见这里Android 录屏 app 代码实现。但事与愿违,录制的静止桌面依然只有每秒 10 帧。
查看视频信息可以用这个命令
ffprobe -show_streams demo.mp4
在试过调整各种视频录制参数,仍然不能满足要求,感觉要绝望了。就在这时柳暗花明又一村,同事介绍了一种神奇的方法:
ffmpeg -i demo.mp4 -r 30 -t 100 %d.jpeg
这条命令可以让你的视频文件按照一个固定的帧率重新排列,并以图片的形式保存到一个文件夹。这样直接解决了我的问题。经过测试重排后的首页帧计算的时间与实际视频中完全吻合。
这里有一个思想误区
在实际录制视频前自己的认知一直认为使用 adb 命令的录制方法就好像我们拿着摄像头录制一样,是不会被其他因素干扰的,可以保持稳定的帧率。但实际以上方法录制的视频帧率是与 android 手机屏幕刷新率一致的。
考虑到这点,其实还可以用AutomatorX [atx 系列] Android 屏幕同步和录制工具文章中提供的方法,利用 openstf 的 minicap 以固定帧率截图保存成视频。实验证实这样也可以规避上面的帧率问题。
还需考虑的事情
- app 的启动方式可以采用模拟点击或者 adb shell am start 命令,这里不得不先忽略手指按压 app 图标后的硬件处理时间。
- app 的启动与屏幕录制要做到协调同步,保证开始录制的同时启动 app,这里可以用多线程的方式处理。
- 对于需要登录和特别操作的需要使用 UI 自动化先进行处理再测试启动时间。
首页帧识别
在这里有一个不得不说的小坑,python 在读取文件夹中以数字排列的图片时顺序是乱的,并不是按照自然数的顺序,结果读取图片后的预测结果全部都是错乱的。让我一直以为是训练模型的问题。这里要做一个小处理
def numerical_sort(value):
numbers = re.compile(r"(\d+)")
parts = numbers.split(value)
parts[1::2] = map(int, parts[1::2])
return parts
def get_test_image():
image_list = []
image_dir = os.getcwd() + '/image_test/'
file_names = sorted((fn for fn in os.listdir(image_dir) if fn.endswith(".jpg")), key=numerical_sort)
file_names = [image_dir + fn for fn in file_names]
def learning_by_modle(model):
clf = joblib.load(model)
tst_img = get_test_image()
predicts = clf.predict(tst_img)
for index, result in enumerate(predicts):
print index+1, result
return predicts
到此预测的过程就结束了,那么无图无真相。
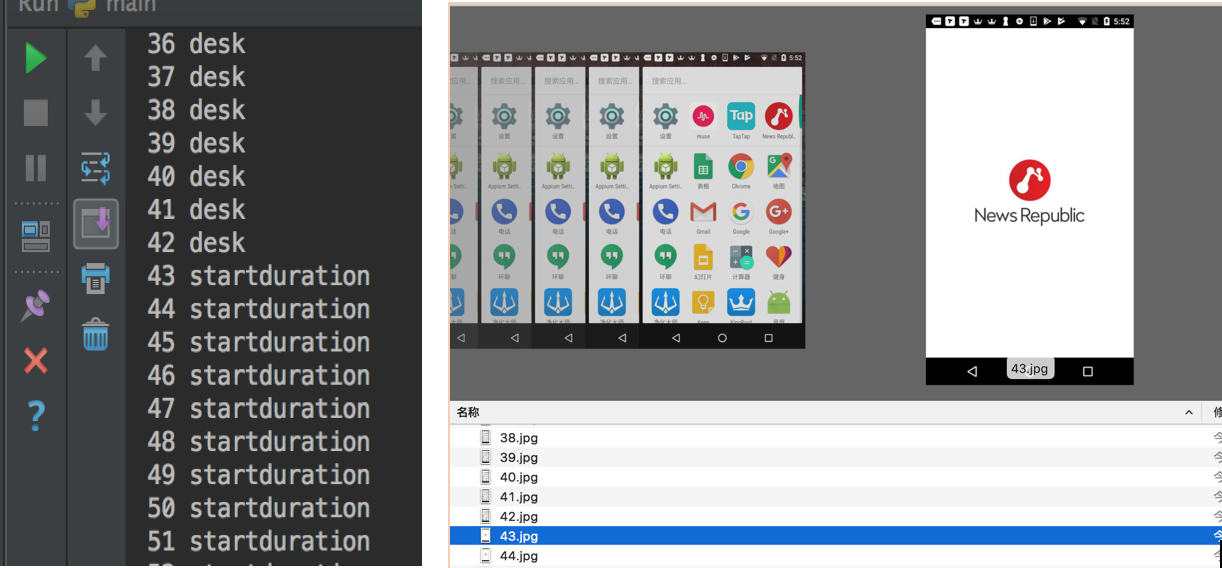
图 3:从桌面到开屏 logo 的识别过程
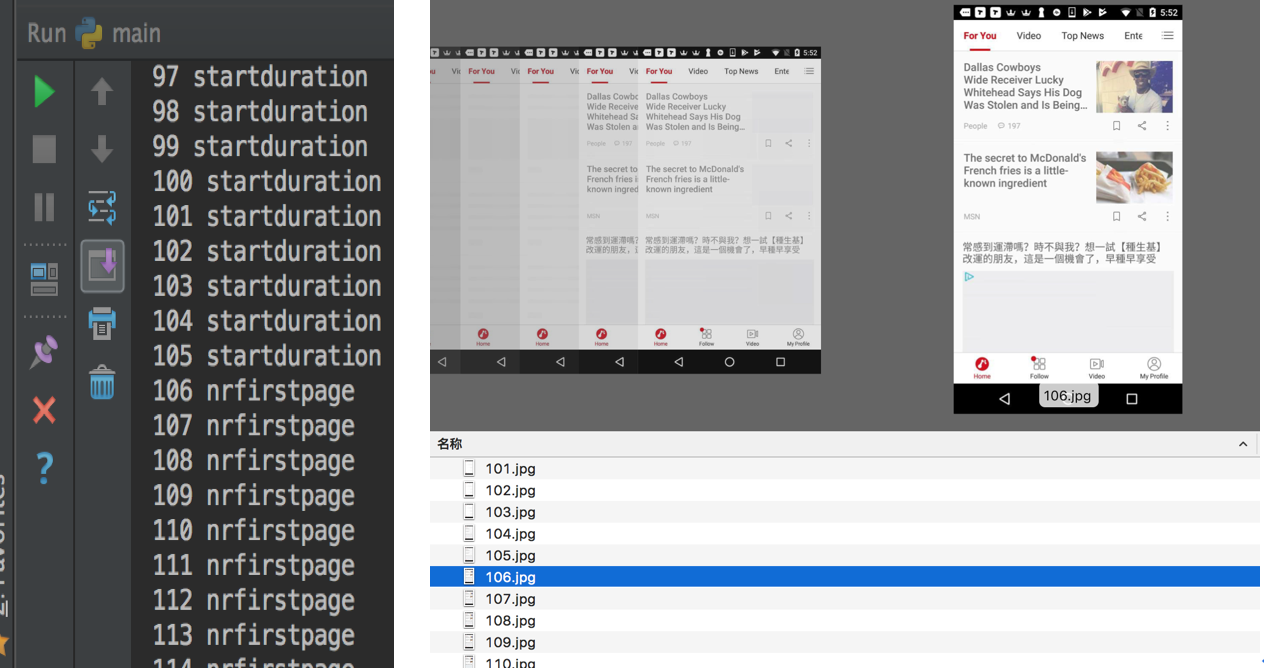
图 4:首页帧识别过程
找到首页帧后计算时间就很简单了,用
FPS = ffprobe -show_streams demo.mp4
total_time = firstpage_index/FPS
就可以计算出该帧的具体时间。
后记
使用机器学习的方法识别首页帧可以完全忽略 APP 首页内容变化对识别准确度带来的影响(除非首页进行大改版),这样就可以替换图像严格匹配这个方法。这只是一次简单的将机器学习使用到测试过程中的尝试,也许还有很多不完善的地方。希望可以给看过文章的各位一些启发。