测试管理 缺陷增长模型
Gompertz 增长模型,有没有数学上,证明下该模型有效性或者思路的?
y=a*bcT
项目中哪些因素对结果有影响,如 加班因素、人员变更
# coding: UTF-8
import numpy as np
from scipy.optimize import leastsq
###采样点
ti=np.array(xrange(1,23))
#yi=np.array([7,10,21,23,24,50,91,120.140,154,171,201,220,224,239.247,256,274,295,325,346,353,369,386,424,484,534,
# 582,621,636,708,736,800,863,932,965,1001,1042,1082])
#3,4,12,13,14,23,42,62,72,76,87,107,117,118,127
yi=np.array([152,168,194,206,213,225,242,280,336,382,429,466,479,548,
572,626,683,748,778,813,847,885])
def func(p,t):
a,b,c=p
return a*b**(c**t)
def error(p,t,y,s):
print s
return func(p,t)-y
p0=[1500,0.078,0.874]
s="Test the number of iteration"
para=leastsq(error,p0,args=(ti,yi,s))
a,b,c=para[0]
print 'a=',a,'b=',b,'c=',c
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
plt.scatter(ti,yi,color='red',label='Sample Point',linewidth=3)
t=np.linspace(0,80,1000)
y=a*b**(c**t)
plt.plot(t,y,color='orange',label='fitting Point',linewidth=2)
plt.legend()
plt.show()
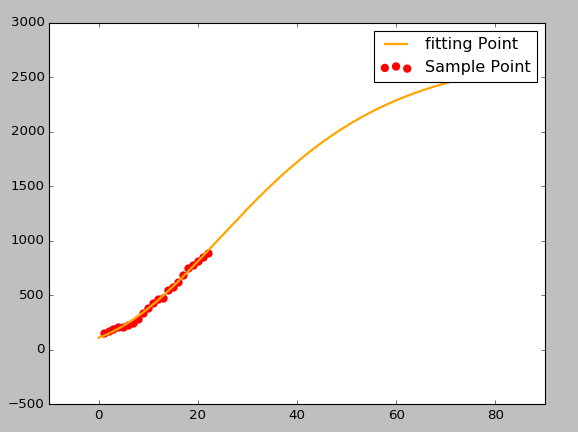
您好,看到这篇文章真是幸运,请问一下,这个模型对测试活动确实适用吗?有公司或者团队实践过证明可行吗?例子中测试周期长达 28 周,如果把周改为天,还适用吗?感谢!
#3 楼 @Lihuazhang 我拟合效果非常好。不过中间有加班,对结果有些影响。当前缺陷量 900,拟合最大 2700。
直观感觉不太对。
—— 来自 TesterHome 官方 安卓客户端
- 肯定可用,而且具备参考价值
- 这个公式的每个参数,是需要拿既往数据来调整之后才能去拟合的,并非每个团队都能通用
我之前在平安科技做这个工作比较久,不过计算用存储过程搞的,推算出预期之后再来观察每天工作是否到位,我们的版本周期只有 15~30 天,所以周期上不会有太大差别
除了这个 Gompertz 之外,还有个 Rayleigh 模型,更精细,用于分阶段预测甚至推算线上 bug 数,至于效果么,我说两条:
- 不见得每次都那么好,因为维护性、补丁性的变更版本和大项目不一样,大项目从头来过,没有历史数据好参考
- 最好把这个计算用规则引擎实现一下,各个参数可以动态调整才是王道,这伴随团队成熟度和管理水平而动态改变,并非一成不变
图例:
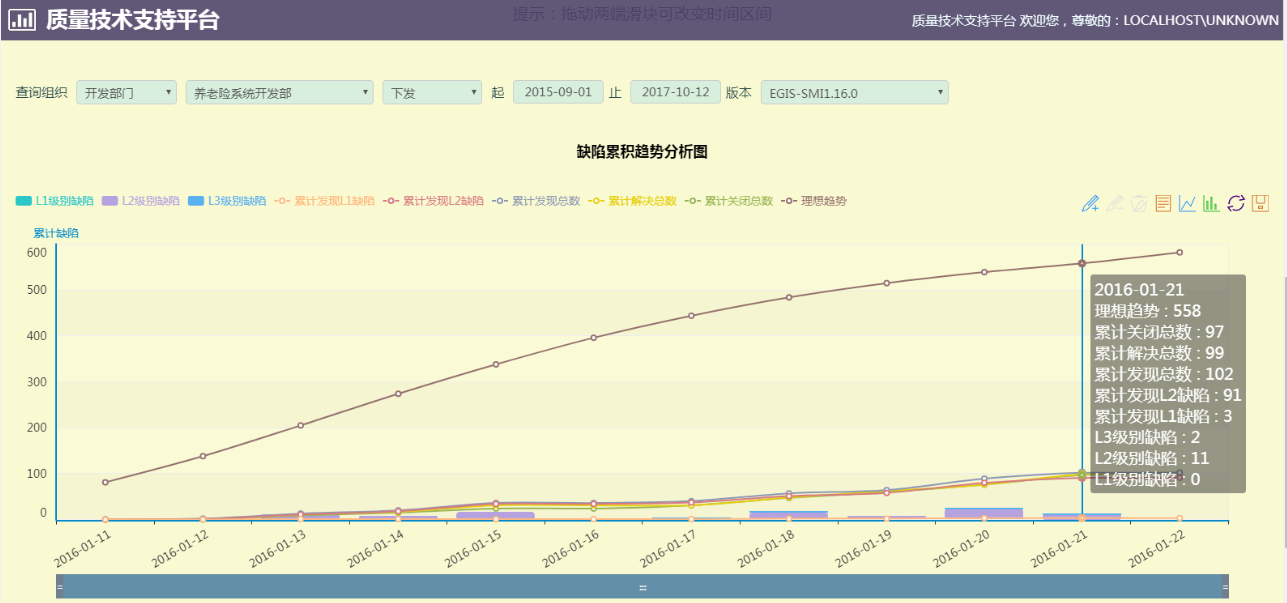
再看下,到年底了,发生了什么
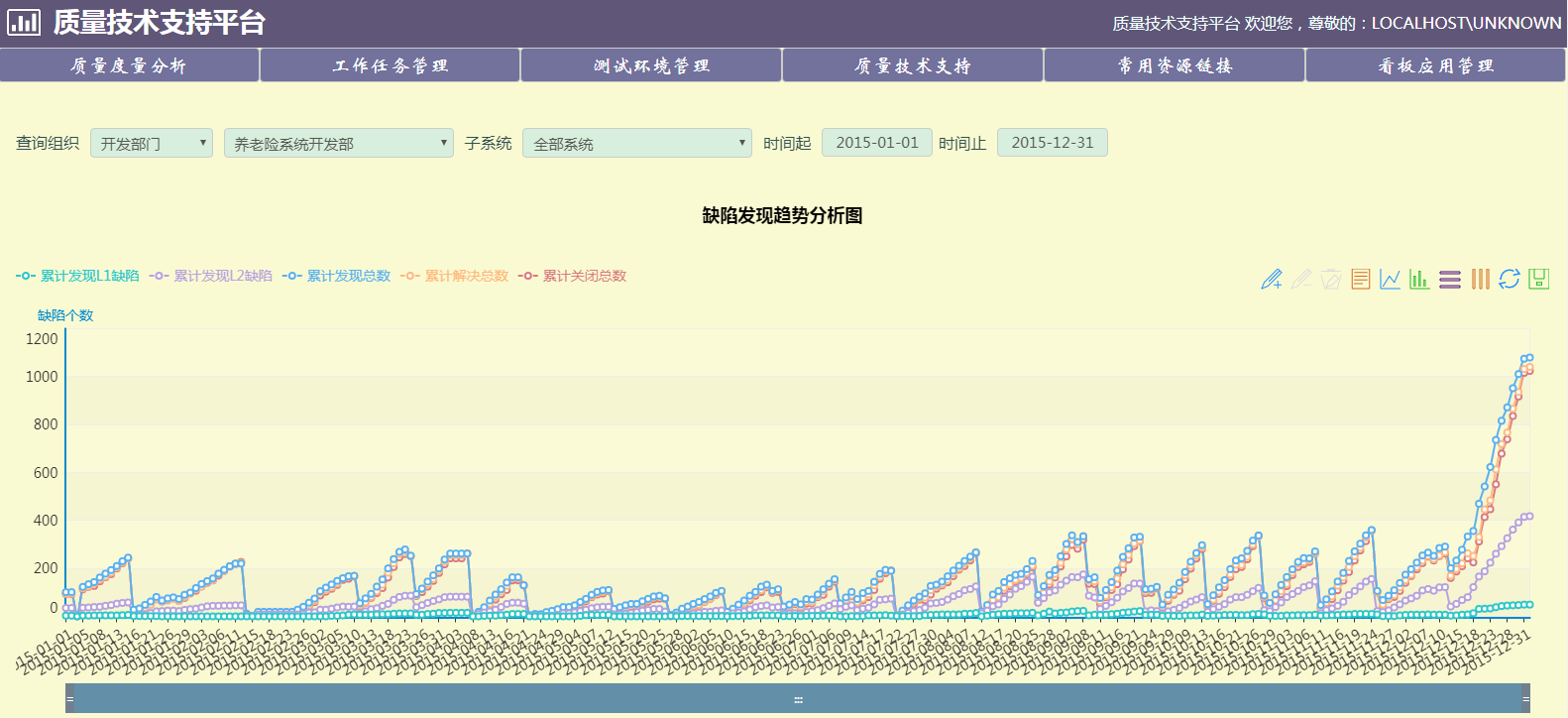
一个比较初级的版本供参考,说明:
- 基础配置数据需要自己灌(劝你别费劲了)
- 存储过程居然都在 mysql 里面(这个锅我不抗)
- 前后端分离没做干净,所以有些页面无法访问
- 地址:https://github.com/fudax/sqcs
丑便丑了,我再晒一图,我一直引以为傲的:
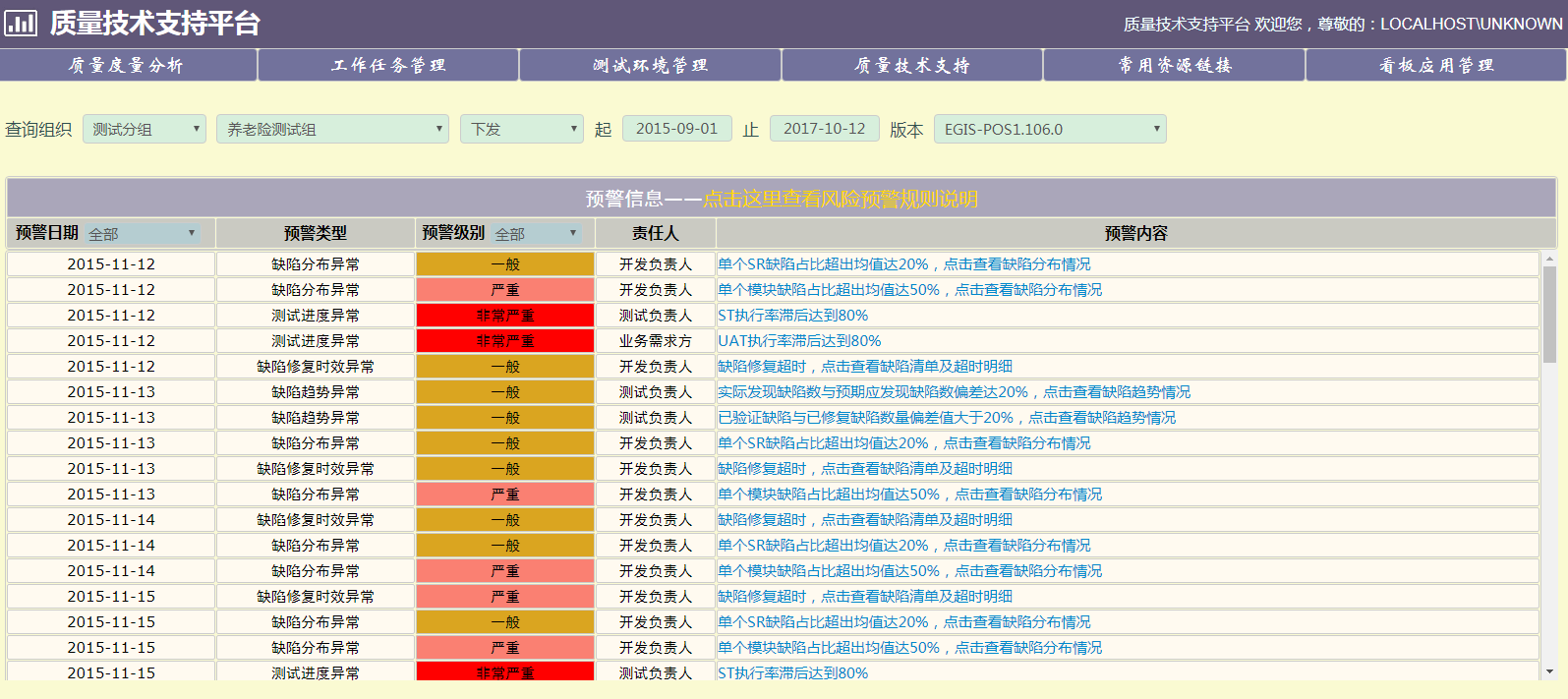
忍不住加精了!
@fudax 这个预测需要多少历史数据?
按照我的经验三五个 release 是要的,然后开始预测,然后分析、优化参数,拍拍脑袋瞎估算一下,稳定下来至少要:
- 团队人数、任务量稳定
- 扣腚的团队人数 8 人以上为佳,SRS 至少每个 release 要达到 5 个以上吧
- 但是新项目、产品研发,我一般第一个迭代上线之后就会立刻开始下一个迭代的计算,拿整个测试团队的平均参数水平来拟合,所以偏差难免会大点,但是越早开始,后面越早贴近真实情况
每个团队的业务类型、复杂度不一样,即便是同样的开发量,缺陷密度也不一样,所以,参数要具体到每个产品或者业务系统,分析的维度也可以多元化:按产品、按产品的 release、按开发团队、按测试团队……最后在一维分析的基础上再做二维、三维的分析,比如加上时间周期来看整体的趋势,这样在全年工作衡量乃至考核打分的时候都有点参考价值(这是大 M 的事)。
我再说一次我去蚂蚁面试的事情,第二次去蚂蚁面试的时候面试题就有一张累积缺陷趋势图,让我来说一下这个项目有什么问题,当时我惊叹于这帮互联网屌丝居然也懂我传统业务的管理办法……那时候开始我以为阿里在这块有一整套的评估和监控体系在实行,现在看你的描述,应该也只是某些团队才会有吧。
这个东西不错!
链接: https://pan.baidu.com/s/1i5qwsVN
密码: ddf8


没玩过,我们只有每周发布的缺陷统计以及每周功能性缺陷总和以及非功能性缺陷总和的统计
太六了。。。
那可不可以换个思路,根据目前的经验,开发出 bug 的概率都是有一定规律可行的,那么可以通过每个开发过往的 bug 数量,然后来预测项目的 bug 数量?
只是管理效率、便利性和准确性的提升,对于一线帮助不大,你可以那这个数据透视的结果要求他们(包括开发、产品、测试)在哪里加强测试、在什么阶段要抓紧投入等等,而想要他们自己理解这些,估计就比较难了,除非是精英团队……而精英团队才不会用这个咧~
最后还是要鸣谢一下,当年 marvell 测试经理张昊翔,现在去哪里也不知道了
做这些还是来自他 chinatest2012 的演讲,可惜现在 TID 大会演讲的水平已经不复当年了,说明测试真的就那么点事可说,技术发展都是被动的,而非领跑 IT 行业~
计算里面 P0 的初始值是如何取的呀?
非常感谢,受益不少