-
开源项目 WHartTest-AI 驱动的智能测试用例生成平台交流群 at 2026年01月12日
这种问题发帖子问也太不效率了。。。
-
开源项目:WHartTest - AI 驱动的智能测试用例生成平台 - v1.3.0 升级重构 at 2025年12月26日
-
我这里招一个测试开发工程师 at 2025年09月28日
熟悉至少一门面向对象编程语言,如 Java、Python、C/C++ 等。
职业病:C 不是面对对象编程
-
测试兼职 - 测试内推 at 2025年09月28日
-
求支招,外包做了 2 个多月告诉月底离职 at 2025年09月03日
上海招人,也是外包但稳定,有需要的话可以看看:https://testerhome.com/topics/38483
-
我,又毕业了 at 2025年06月30日
我觉得可行性的方案是,n+1 大概率就这样了,但是每个月应该是多少,你可以主张按年收入/12,这样会稍微多点
-
划水:团队引入了 metersphere,后面遇到了各种问题 at 2025年06月04日
感谢
-
划水:团队引入了 metersphere,后面遇到了各种问题 at 2025年06月04日
那相较于从无到有开发一个呢?
-
请教下使用 Airtest 工具在游戏测试中的使用前景 at 2025年02月10日
所有 UI 自动化都是模拟人在点点点,照你这么理解都不如你,那么你能否同时点几十台设备?自动化的亮点最核心我认为只有一条,就是提高效率,替代重复性劳动。测试体量上去了才有价值。
-
「我的 2024 年终总结」一个小小工程师的不知道第几次回首 at 2024年12月30日
小小的建议,不要操闲心,不要扣帽子,女王大人== 矮化自己就离谱
-
接口不响应可能是什么问题? at 2024年12月13日
从描述看,有一种情况非常符合,就是代理,如果代理对请求放行,但是对服务端响应劫持了不放行,那么对于服务端来说已经正常处理并返回了,你从服务端是排查不到问题的,而客户端又收不到响应
-
又到年底了,该如何优雅的提涨薪 at 2024年11月25日
又到年底了,该如何优雅的拒绝小伙伴们的涨薪需求,实在是没办法,又挺了一年部门没裁员
-
docker 无法拉取镜像? at 2024年11月25日
上周遇到过同样问题,我是换了很多的源才解决,猜测常见的国内源暂时出现了些问题,导致 docker 最终还是用默认的然后报错,不是配置或者要重启啥的这么常见的问题
-
在这个平台看到过很多大佬的帖子,感受颇深,心里有一个疑问,盼大佬们回复 at 2024年11月12日
长期要看,短期也要看,四个月还没过试用期,合同是三年及以上?合同上有没有约定试用期?
如果试用期被开,大概率是没有赔偿的,那就要看试用期约定是否合法
除了向前辈学习外,我认为当前最重要的事情是转正,小公司可能没有人关注你的转正时间 -
关于移动 App 的自动化测试疑问 at 2024年10月18日
我理解问题 1 和 3,都可以通过接口测出来,3 这类问题比较多的话,需要定规范,让前后端开发都应该有这种意识,接口返回数据过多应该分页或做其他处理
-
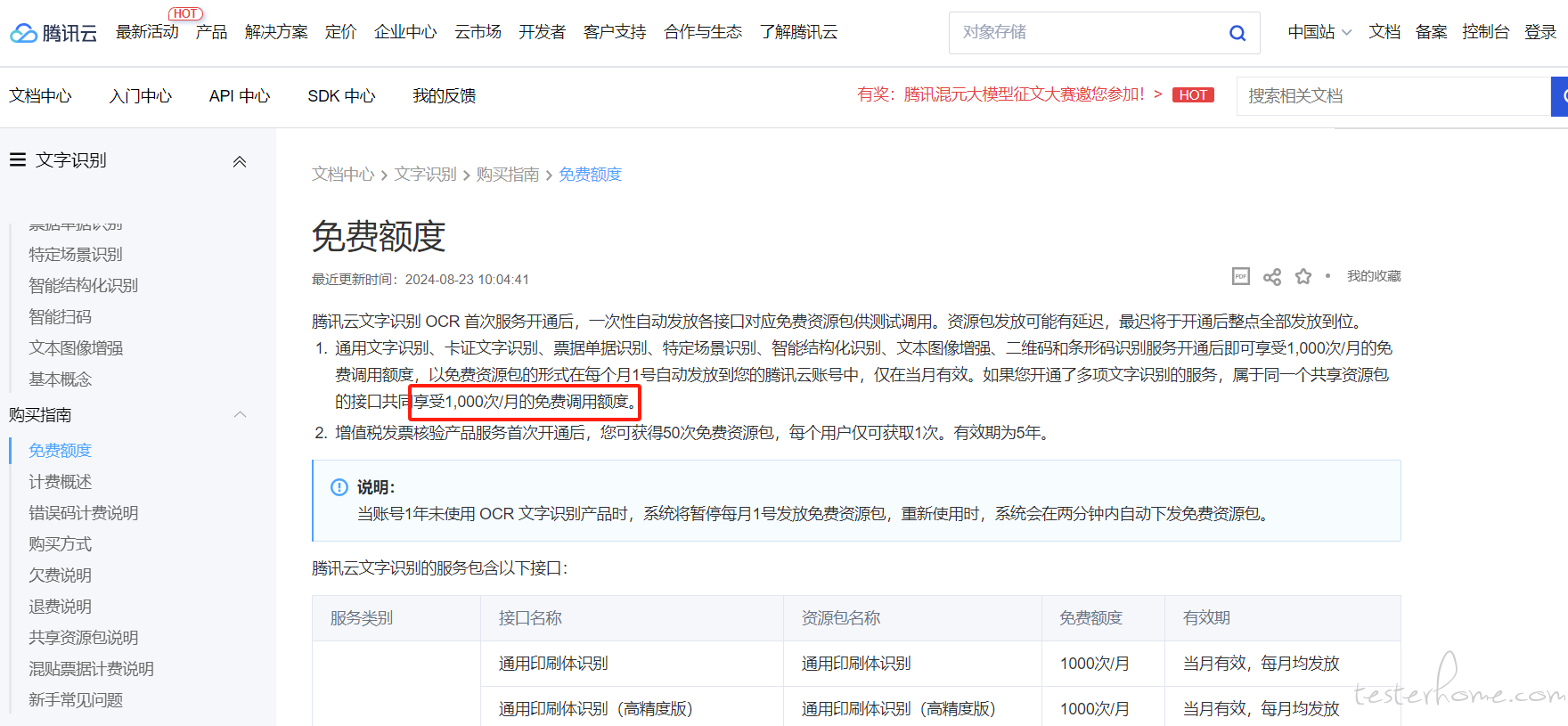
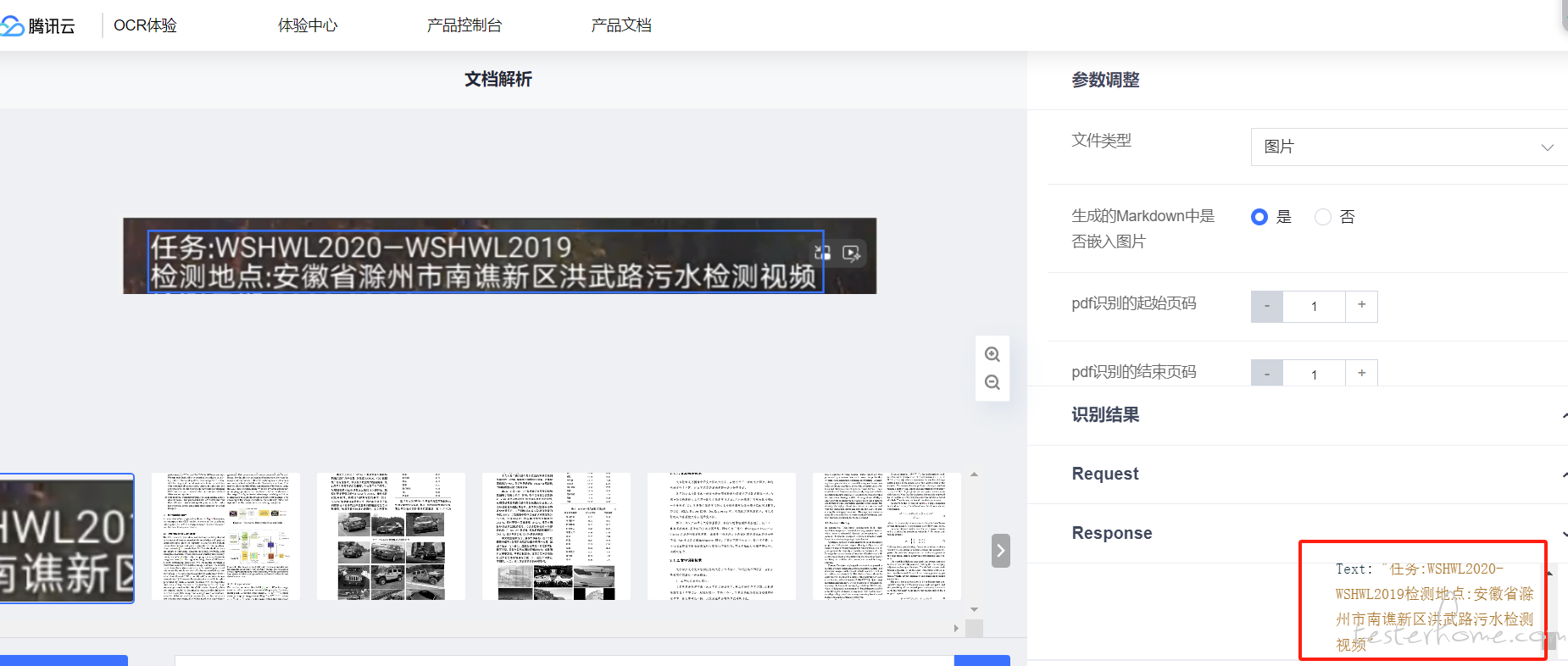
请问下有人 搞过 提取图片里的文字吗? at 2024年10月09日
如果你是仅仅是要使用 OCR,那么我建议你直接调腾讯 or 百度的 OCR 接口,每个月都有免费额度,拿你这个图片来看效果很好,如果你要研究 OCR 技术就当我没说。
-
应届 7.5K 入职第三天被要求搭自动化测试框架 at 2024年09月29日
应届,7.5k,入职三天,buff 都拉满了,就要求搭自动化框架,要么你的 leader 不靠谱,要么就是你想的复杂化了
比如我部署一个 metersphere,也可以叫搭建了自动化框架,它确实可以做一些自动化测试
-
移动端操作同传有人搞过么 at 2024年09月23日
录制脚本,脚本进行修改,其他设备自动化执行,跟你说的没啥本质区别吧?
只不过不是实时的而已,实时同步有必要吗,只会让问题更多更复杂 -
互联网大厂服务端测试流程 at 2024年09月13日
第一步,举例的这些容易发现的问题,都可以用静态分析工具来做,会很快
-
对于性能测试的一些问题,大佬们可以帮忙解答看下 at 2024年09月03日
我觉得带宽不同,是导致接口响应不一样的主要原因,你可以两个客户端各只请求一次看一下响应时间,接口响应应该也会有差距,但没这么大;然后这种带宽要求高的接口压测,我理解应该以跑满服务端带宽为目标,因为真实的用户场景下,是非常多的客户端,客户端的带宽是不会跑满的。要跑满服务端带宽,压力机带宽应该大于等于服务端带宽(这要求较高,当然楼上也说了可以估算出来的 )
-
求职 - 测试工作,目前在深圳 at 2024年08月22日
这话说的,谁在测试行业有远大理想吗
-
可视化监控搭建过程 at 2024年08月02日
你这个太麻烦了,找个 docker-compose 方案,就只需要 从 “d.进入 grafana 官网查找模板 ID” 开始就完成搭建了,例如:
version: '2'networks:
monitor:
driver: bridgeservices:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml- ./node_down.yml:/usr/local/etc/node_down.yml:rw
ports:
- "9090:9090"
networks:
- monitoralertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
restart: alwaysvolumes:
- ./alertmanager.yml:/usr/local/etc/alertmanager.yml
ports:
- "9093:9093"
networks:
- monitorgrafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
ports:
- "3000:3000"
networks:
- monitornode-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
ports:
- "9100:9100"
networks:
- monitorcadvisor:
image: google/cadvisor:latest
container_name: cadvisor
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- "8899:8080"
networks:
- monitor -
selenium 启动 chrome 浏览器非常慢。 at 2024年07月12日
试试无头浏览器
-
MeterSphere v3.0 全新启航,让软件测试工作更简单、更高效 at 2024年07月03日
是为什么决定放弃了 UI 自动化和性能两大块呢
-
jmeter 单机可以开启多大多少线程?怎么评估? at 2024年06月24日
怎么看出来没有线程池,从 5000 这个数字举例可能不太合适,我意思是说需要监控服务端线程,当服务端线程数与发起的线程差距比较大,再去找原因嘛,这里就涉及到线程池设置、压力机问题等等。