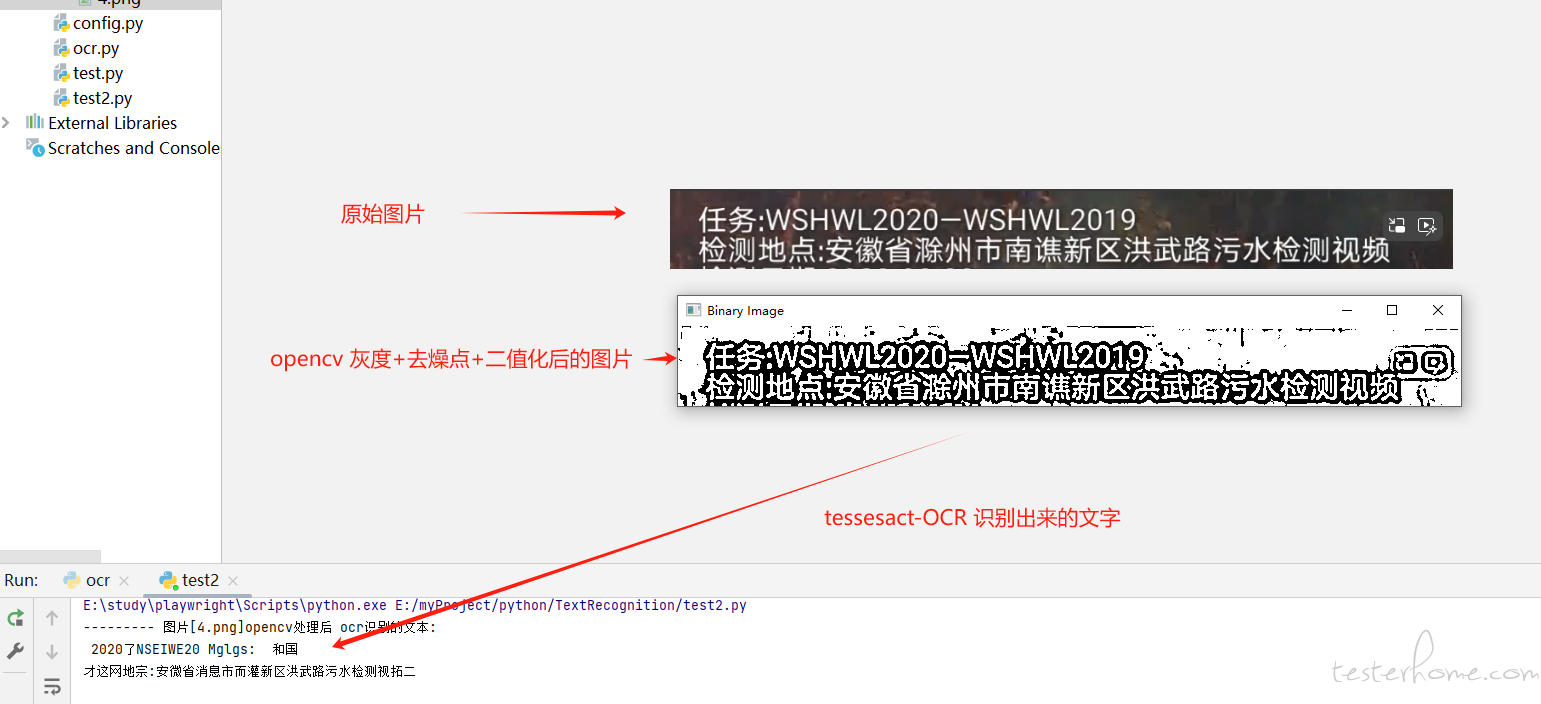
识别率惨不忍睹, 可能是特殊字体不容易识别。
目前的处理方法:opencv(灰度 + 高斯模糊去噪 + 二值法)+tessesact-OCR 识别。
但把同样的图片放到微信里识别,识别准确率很高。
是要针对字体做模型训练?有人相关的经验吗?
如果你是学,那当我没说,如果你是用,可以直接集成微信识别

百度飞浆有开源的离线包
百度飞浆试试呢?
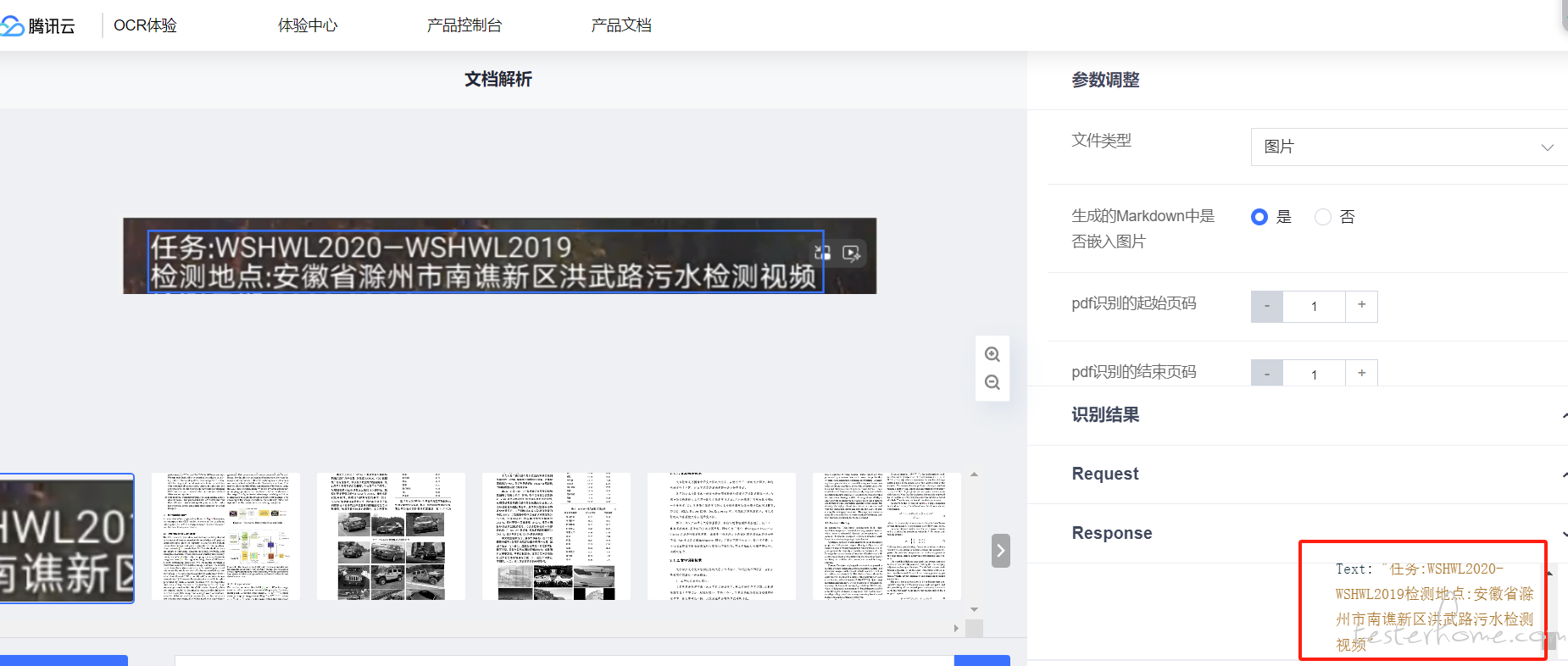
如果你是仅仅是要使用 OCR,那么我建议你直接调腾讯 or 百度的 OCR 接口,每个月都有免费额度,拿你这个图片来看效果很好,如果你要研究 OCR 技术就当我没说。
试试 trwebocr;直接 docker 部署,唯一缺点就是 cpu 慢
https://www.cnblogs.com/Im-Victor/p/17754051.html
中文支持最好的 6 款 OCR,推荐用前两种就可以,亲测好用
除了 tesseract、PaddleOCR、EasyOCR 等,还可以直接调用 LLM~