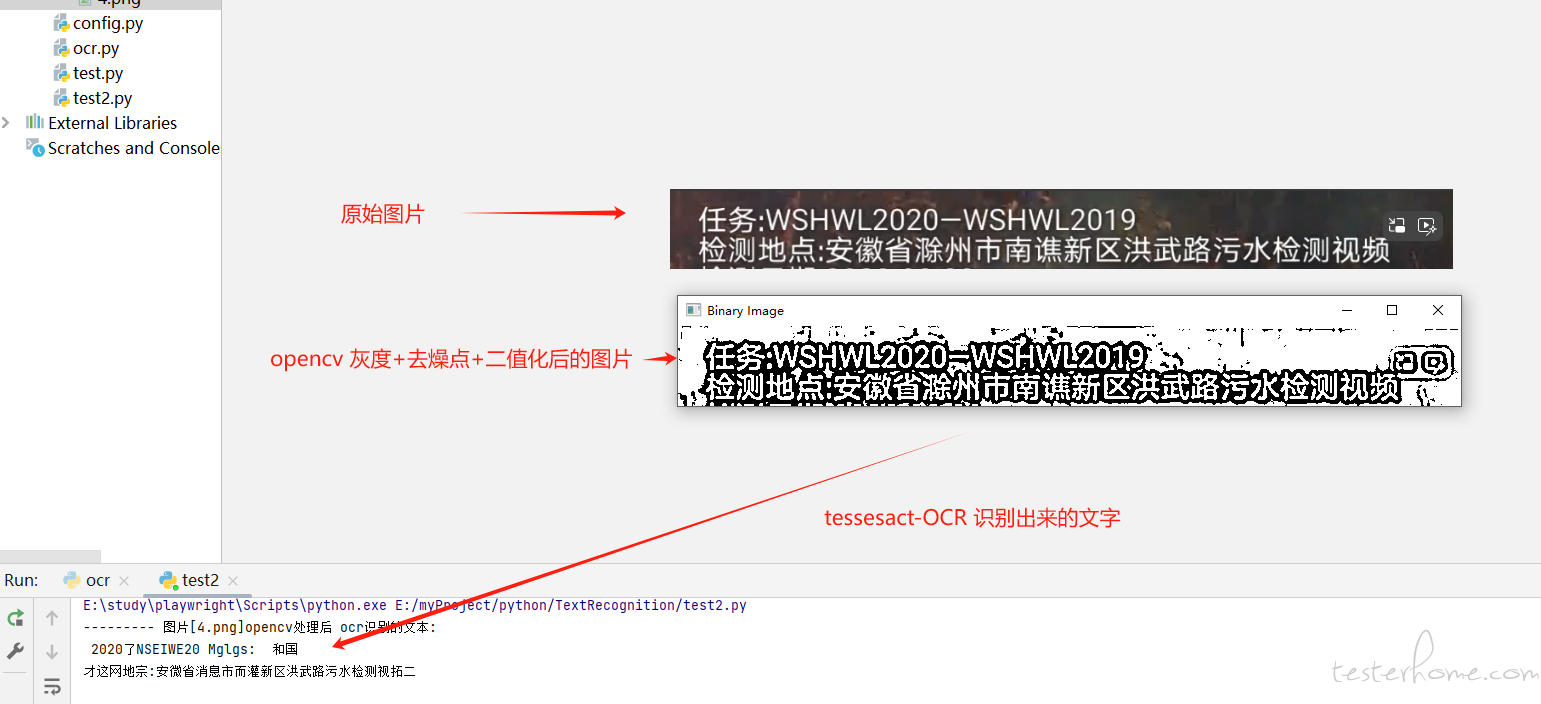
识别率惨不忍睹, 可能是特殊字体不容易识别。
目前的处理方法:opencv(灰度 + 高斯模糊去噪 + 二值法)+tessesact-OCR 识别。
但把同样的图片放到微信里识别,识别准确率很高。
是要针对字体做模型训练?有人相关的经验吗?