-
求助帖:目前不知道该学习什么 at 2021年07月11日
建议你找到你工作上需要用到什么,再针对性学习。比如现在 ui 自动化的落地还有什么问题需要解决,或者除了 ui 自动化还有什么地方需要提效,大概需要什么技术。
学了但用不上,自然觉得价值低,而且效率也不高,熟练度也不高,成为不了真正的技能。
比如我之前需要二次开发用例管理平台,就重新复习了 java,学习了前端的 vue+react。后面需要做云真机,又去学习了云真机要用到的相关框架工具(这个得靠自己调研和同行交流,没有啥现成的材料可以直接学习)。学完再用到,不仅更牢固,而且产生的价值也更高
-
关于 flask 中 点击按钮后,后端终止线程的问题 at 2021年07月11日
你这个立即停止,线程应该没法满足。
1、目前应该没怎么提供直接停止线程的方法,大多是在线程内部执行时通过一些轮询来确认是否有停止记号,如果有记号就线程自己停掉,没记号就继续执行。
2、另外,python 的线程由于解释器有 GIL 限制,和其它编程语言不大一样,实际并没法通过多线程用到 cpu 的多核性能,有点像是伪并发。所以 python 并行多任务大多用的多进程,多线程用得比较少一些,一般只会用在异步任务(比如等待网络 io)。不过看你这个场景应该用不着榨干性能,应该还好。你这个场景,建议可以考虑改为用多进程(multiprocessing)?多进程的话通过 kill 发不同的信号量,可以做到仅给退出信号(类似 ctrl+c),或者强制直接杀死进程(操作系统直接杀,进程自己没有拒绝权利,比较符合你说的这个要求)。
-
【活动】MTSC 2021 深圳站议题征集 at 2021年07月11日
啥意思?
-
appium 运行一段时间后提示「 Error: timeout of 240000ms exceeded」 at 2021年07月09日
Error: timeout of 240000ms exceeded
意思是某个处理已经达到 240 秒(4 分钟)极限超时时间,但还是没有返回。
背后可能是系统卡死、uiautomation 进程卡死等,这块需要结合 andorid logcat 日志才能分析定位。但和你 systemPort 应该没啥关系
-
请问下数据中台、数据工厂、数据仓库都是啥,他们有啥区别?测试都是测些什么? at 2021年07月07日
以下个人理解:
数据仓库,属于大数据的概念,指的应该是存储基本所有待分析的有价值的数据的位置。一般用 Hive 等大型数据库存储。所有的分析报表都从数仓出来,所有有价值的业务数据最终都汇总到数仓存储。
数据工厂,或者叫造数据平台,指的是测试过程中快速造数据的工具
数据中台,属于大中台概念的一部分,指的是大数据的所有操作(包括数仓、数据处理、报表等)都集中到一个大服务中完成。日常的业务需求(比如新建一个报表,新接入一个数据源)都在数据中台中进行配置即可。与之对应的概念有业务中台、测试中台等至于数仓怎么测试,目前我也没接触过,但艾辉老师的《机器学习测试入门与实践》有大致提了下,可以看看了解下。
-
求助:接口自动化中第三方支付的如何实现?或者说绕过? at 2021年07月07日
wireshark 可以抓到,但抓到你也不一定能解析或者模拟。它用的可能是自定义协议,或者类似 proto buffer 这类没有协议解析工具没法正常解析的协议。
其实前面的同学已经给了几个可行的方案了,只是基本都绕不开开发的。推荐你还是找你们开发聊一下吧。
-
求助:接口自动化中第三方支付的如何实现?或者说绕过? at 2021年07月07日
这个理解没错。
主要是支付的交互不是简单的一个接口就搞定的事情,毕竟涉及安全 + 异步(一般支付背后涉及很多方,耗时很难确定,所以都是做成异步式交互的),所以需要先搞清楚你们系统的交互。要不找不到对应在哪里 mock 掉它。
另外,抓不到包应该不是因为加密,加密只会让你看不懂,不会抓不到(如果加密后会导致抓包工具抓不到,网络传输一样也会识别错误,因为协议本身定义的部分,怎么加密都是不能改的)。抓不到一般就是抓包方式和传输协议不一致了。
比如微信 app 支付这种方式,下图这个位置的交互,很可能就不是走 http(据我所知,微信 app 和微信服务端,走的都是 tcp ,正常微信发消息的通讯交互,你用基于 http proxy 抓包的工具,如 charles、fiddler ,也一样抓不到)。
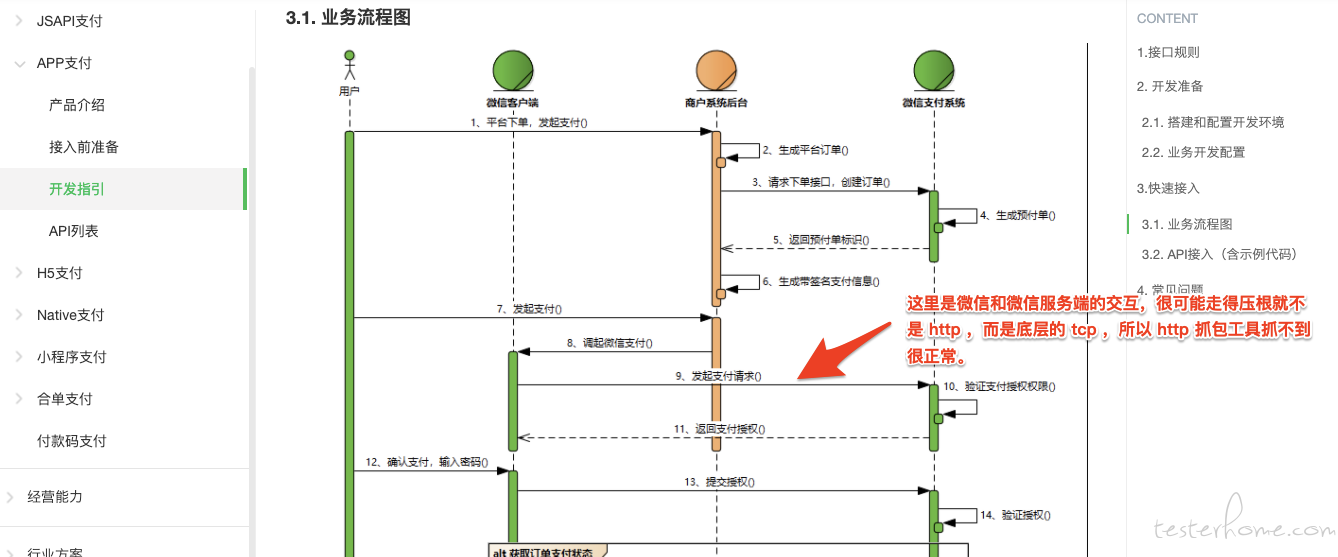
-
社区里满大街的测试平台都是接口类型的,为啥没有数据工厂的平台? at 2021年07月07日
有其它办法,比如直接仿照系统的业务处理逻辑再写一遍,开发怎么产生数据的,造数平台也一样逻辑去产生,但这么做成本太高了。
相对而言,用接口等系统提供给外部调用的入口来造数,相对维护成本低不少。而且流程性接口用例本身就是自动化测试的产物,用来造数据属于水到渠成,也没有太多为了造数据而额外付出的成本。
或者你也可以先分享下你们的现状,以及你们现在人工造数据大概是怎么做的?
-
selenium 可以测试浏览器 (chrome & firefox) 插件吗 at 2021年07月06日
请描述清楚你的问题,插件的定义太广泛了。。。
-
求助:接口自动化中第三方支付的如何实现?或者说绕过? at 2021年07月06日
那就爱莫能助了,和第三方支付的交互一般都不止一处的,不找开发确认清楚交互,比较难绕过。
或者可以试试用 UI 自动化来绕过呗。
-
设置 sendkeys 后,文本框无输入 at 2021年07月06日
但不是每次点击都有内容输入
有内容输入说明是有可能成功的。你对比看下成功的和不成功的,有没有什么差异?
-
求助:接口自动化中第三方支付的如何实现?或者说绕过? at 2021年07月06日
你有能力直接看项目代码来了解交互也可以,但问开发效率更高,而且后面遇到阻碍也容易找开发协助处理(比如鉴权太复杂,模拟成本很高,让开发开个可以跳过鉴权的后门,成本会低很多)。
我理解这只是一个比较简单的合作而已,你们是有什么特殊情况,必须纯测试团队解决这个问题吗?
-
求助:接口自动化中第三方支付的如何实现?或者说绕过? at 2021年07月06日
我指的是你的系统交互,不是用户交互。即你们的业务系统是怎么和第三方系统交互的,涉及哪些端、哪些接口等。
给你一个微信支付里的示例(只是微信支付提供的其中一种接入方式,具体你们怎么接入的,你还是问你们自己开发吧):
https://pay.weixin.qq.com/wiki/doc/apiv3/open/pay/chapter2_5_2.shtml#part-5
PS:微信 app 和微信服务端交互走的是基于 tcp 长连接的自定义协议,普通 http proxy 这种抓包是抓不到的。
-
求助:接口自动化中第三方支付的如何实现?或者说绕过? at 2021年07月06日
能否先说下你第三方支付接的哪个?大概是怎么和你们自己系统交互的?
不同第三方支付这方面还是有差异的,有的是服务端纯 api 对接,有的是内嵌 h5 界面 + 服务端回调,有的是 app sdk 接入。不同接入方式,对应的自动化方案差异还是挺大的。
这块问下你们开发应该会知道,先把交互理出来,才好说怎么自动化。
-
UI 自动化稳定性用例实战经验分享! at 2021年07月06日
哦哦,明白。如果是 web 前端 +vue,确实得用 xpath ,因为 template 里一个组件,实际对应 html 好几层结构了。
-
UI 自动化稳定性用例实战经验分享! at 2021年07月06日
页面增加新功能,导致页面元素发生改变
解决方案:
尽量不要使用元素本身的 ID、name、class 定位,尽量使用 xpath 定位方式这个和我的认知不大一样。可以分享下具体什么场景下, xpath 定位比 id、name 要好?
-
设置 sendkeys 后,文本框无输入 at 2021年07月05日
从现在提供的信息里,看不出和问题原因有比较大关联的内容呀。。。
建议:
1、把截图也发一下,确认下实际用的是哪个输入法
2、把完整的 desired_caps 参数发一下,有不少参数是要组合使用的。
3、也发下你找过哪些资料,尝试过哪些方法,这些过程也能提供更有用的参考信息。 -
社区里满大街的测试平台都是接口类型的,为啥没有数据工厂的平台? at 2021年07月05日
补充一个,极客时间的测试 52 讲里,有几讲相对系统地介绍造数据的各种形式,如果想系统点了解的话,也可以看看。
-
社区里满大街的测试平台都是接口类型的,为啥没有数据工厂的平台? at 2021年07月05日
也补充下对标题这句
社区里满大街的测试平台都是接口类型的,为啥没有数据工厂的平台?的理解1、做数据工厂或者这方面持续投入的,我目前接触除了金融类业务,好像其他业务需求都不强(大部分业务流程都是短且简单,中间态不多),所以可能做得也不多?
2、造数据很多都涉及到领域业务知识,分享出来度不好把握,脱敏太厉害就虚,写得太具体有风险。所以分享的也不多。
3、这方面更多还是体力活(一个一个脚本写下来),能做创新的点不多,受众相比接口测试这些也不广,所以大家可能分享欲望也不是太强。所以,如果是领域相关,通用性相对不那么长的,可能你直接找同业务领域的同行交流,会比在外面找分享文章效果好很多。
-
额,我已经好久没用了,官方貌似更新了挺多代码,这个是否还能触发回放我还真不大清楚。
standalone 只是一个方便快速演示用的 demo 而已,建议你直接用非 standalone 方式吧。
-
社区里满大街的测试平台都是接口类型的,为啥没有数据工厂的平台? at 2021年07月05日
我们之前内部有做,思路和你的类似,但有些地方不大一样。
我们当时的背景:业务是借贷业务,流程比较长(注册 - 登录 - 授信 - 风控审核 - 放款 - 还款 - 催收),有些时候测后面环节的变更,需要刚好到这个环节的账号,所以造数据需求比较强,很早就开始做了。
第一阶段,用的最简单的办法,web 前端根据提供的账号名,直接去改数据库某些数据的状态类型字段,比如一键注册、一键风控审核通过等。好处是实现简单,一个熟悉业务的测试同学就基本能 hold 住。缺点是容易改漏产生脏数据,而且从零造还得一步一步来。
第二阶段,结合接口自动化,用流程自动化用例来造数据。有几个能到上面提到流程点的自动化用例,并且把账号一些基础信息(如手机号)抽离成了配置项。好处是已经基本满足测试需要了,随时从零生成到某个节点的数据。缺点是客户端、前端开发以及产品还是不大会用(他们技术栈不一定是 java,所以不熟悉甚至本地都没有 java 环境),而且不同组用的不同的仓库,跨组使用还得了解哪个用例对应哪个东西,使用成本略高。
第三阶段,基于流程自动化用例,增加一些 controller+dto,变成 http 服务,并加入 swagger 做到每个接口自描述。同时也用 antd 做了一个前端,可以配置接入不同组的 http 服务,并基于 swagger 提供的内容,生成对应的界面。这样左侧是业务描述,右侧是这个业务下的各个造数据功能(也可以分组,一个 controller 在前端会放到一个 tab )。执行失败前端会展示完整日志,方便用户提供给测试同学去定位解决。
除了我们的实践外,19 年的 MTSC 大会,工程效率专场,陆金所有一个议题特别分享了他们的造数服务,你可以到社区公众号底部的 MTSC 找到当时的视频和 ppt。
针对你这 3 个困惑,也相应说下我们之前对应的情况和解决:
只有写这个造数脚本/代码的人才知道相关的造数逻辑,给其他人维护或者小伙伴离职了都比较难维护下来
我们在第一阶段的时候这个问题遇到得比较明显,因为维护的人太少了,知识掌握在少数人手上。第二阶段就好了很多,毕竟大家都在写,而且能清晰说明这个流程,被定为了试用期通过的必要条件,也能保障不至于大多数人不清楚。
因为是造数嘛,通过 post 开发的接口去实现造数,版本迭代接口变了,那造数相关的代码也得跟着变
首先,服务端接口大多都是向下兼容的,所以接口变了很少会造数脚本也必须马上改,不改用不了。大多数情况是新产品接口加了参数,需要写心得脚本才能造新产品的数据。
因为组内每个人的代码风格都不一样,较难统一下来,整体看起来参差不齐
这个就需要培训和规范了。我们其实也有遇到,一开始考虑到水平不一,没限定写法,所以百花齐放,甚至有的组的写法只有自己组才能看得懂(主要是整体设计比较特别 + 各种奇妙的命名),而且大家都处于 “知道自己写得不好,但不知道怎么才能写得好” 的状态。后面整体做了一次重构,重新统一了写法,并且初期所有改动强 review ,由熟悉规范的人 review 通过才合并,保障大家姿势正确。后面就会好很多。
-
你试过直接用 shell 脚本啥的拷贝过去不?或者用
curl命令把你 maven 仓库的包下载到你说的位置? -
测试职业发展在业务方向上延续性问题讨论 at 2021年07月05日
首先,app 和电商是两个不同维度的东西吧,app 算技术领域,电商算业务,按这个来说年限有点怪怪的。
其次,业务延续性确实不同人有不同的选择。我之前在互联网金融公司,里面的小伙伴出来有有继续在金融领域的,也有换到其他互联网领域的,甚至转行做产品或者其他岗位的。
我自己每次跳,虽然一直都是测试领域,但从公司对应业务领域来说差别都挺大。个人感受上,其实不会有太大的 “业务没有延续性” 这方面的担忧,反而会觉得自己的业务观会越来越大,而这个业务观也会帮助自己每次熟悉新领域的时候,更快速能上手和找到关键点。
补充一个点,对某个领域是否深入,呆多长时间只是一个参考值,关键还是是否有持续提升和扩大自己的视野。我在上家公司 3 年多时间,从小组长做到质量团队负责人,视野从只是管小组,变成了整个公司业务的质量,个人感觉对业务的深入度,尤其是对抓关键点的能力(比如那些功能对业务而言更重要),其实会越来越强。而这个能力后面换了公司,还是可以延续的。
-
大厂面试总结 at 2021年07月05日
包含但不限于这个,DevOps 关注的还是研发流程内部。这些年的实践,我对于提效的理解也有些转变,有点朝着精益的方向。
除了重复事情自动化外,会更多考虑怎么 “简单做”(简单到别人也能做,就可以顺势赋能),甚至 “不用做”(比如基于投入产出比评估来砍/拆需求、降低技术方案复杂度,这样质量风险减少,测试工作量也能对应减少)。
-
大厂面试总结 at 2021年07月05日
以我这几年做测开的经验, 很多有价值的事情都是需要一定的研发和运维能力才能去做。
这句想特别点个赞!很多时候想要做更有价值的事情,得先自己突破测试的界限。