-
【请教】pytest+mitmproxy 怎么联合使用? at 2021年06月23日
有点没看懂你的问题。这两个工具一个是测试工具,一个是网络代理工具,本身就可以相互独立使用。
你说要联合,是要做到什么效果?自动化测试的时候,自动配置代理,并且自动改代理里的 mock 配置,返回你想返回的 response ?
-
window 上运行 tidevice+appium,关于 webDriverAgentUrl 问题,麻烦大佬帮忙看看 at 2021年06月23日
appium 日志里,有个地方要留意下
[BaseDriver] Capability 'usePrebuiltWDA' changed from string to boolean. This may cause unexpected behavior [BaseDriver] Capability 'useNewWDA' changed from string to boolean. This may cause unexpected behavior这种转换不知道结果是布尔值的 true 还是 false
"webDriverAgentUrl": "http://localhost:8100/", "usePrebuiltWDA": "false", "useNewWDA": "false",建议第二、第三个改为用布尔值的 false,不要用字符串的 false 。
我们内部用,只需要配置
webDriverAgentUrl、useNewWDA(值为 false ),就可以用 atx server 云真机上提供的 wda 来执行自动化了。 -
瓶颈期,最近在思考一个问题,为什么学 python 为什么做自动化? at 2021年06月23日
感觉楼主是累了,进入了疲惫期。这个主要还是心态上的变化。我毕业 2-3 年的时候也遇到过,各种新想法,然后否定自己的新想法,否定多了就会觉得啥都没意思,不想做。最后是去了一次旅游放松,然后就好很多了。
建议楼主可以先暂停思考一下,放松下自己 1-2 周。然后再去思考这个问题,找到自己的方向。
新公司项目虽然用 python 但是我没有参与
后面建议可以主动申请参与下,参与了可能就没那么多疑问了。
-
如何培养结构化思维? at 2021年06月22日
我的方法是:多练、多比较,然后每次练的时候,都借鉴下其他更好的,融入进来。
比如,我基本上从高中开始全部作文都写议论文,都是总论点、2-3 个分论点、总论点的结构。重复写了这么多遍后,基本上现在想、说、写都是 1、2、3 这样的分点描述的结构了。写代码、写用例本身,其实也是一种非常锻炼逻辑思维的工作,因为要求逻辑严谨。
前期建议先从写作开始,想是最快速的,说第二,写的速度最慢,思考时间也最充分。阿里不是每周都要写周报么,刚好可以借助这个来练习下,一举两得。写完周报可以也看看其他人的,看有什么写得比自己好的,然后下一次周报借鉴提高。
如果想要先了解下怎么能分论点阐述,可以看看《金字塔原理》这本书。
-
如何封方法,调用开发接口,测试这个接口的多种调用场景 at 2021年06月21日
描述问题,先说清楚用的啥框架吧。。。看图明显不是编程语言,应该用的是 robot framework
至于你这个问题,可以用
robotframework 不定参数搜索下,很容易找到答案。基本思路是封装成字典来传,而非传 10 个参数。不过这个答案是受限于 robot framework 机制(.robot 格式的用例,没有类和对象,也没有函数可选参数机制,只有关键字、逻辑操作符和变量)所以只能这么做,如果是编程语言,直接 java bean + builder 模式(没有可选参数可用的语言,如 java )或者用函数的可选参数(keyword argument)更好。
实际编程要尽量避免传一个字典作为参数,解析字典还得各种判空和让使用者想办法保障 key 名称一致(编程工具无法帮你自动补全,重构改名字也没法直接帮你每个地方都改到位),很容易出错。
-
Appium 自动化测试不稳定,总是运行一段时间后 at 2021年06月21日
从目前给到的日志,只能看出是某个底层的请求可能由于卡住超时了,超过 240 秒都没返回。但因为不知道你使用的自动化驱动方式,所以不知道是 ios wda 卡住,还是 android uiautomator2 卡住,还是别的其他底层驱动卡住。
可以跑的时候也收集下对应操作系统的日志(如 android logcat ,ios 的系统日志),看下发生超时的同一时刻,操作系统有没有报什么异常?
-
基于百度脑图的用例增量保存 + diff 展示整体设计 at 2021年06月18日
也特别感谢你之前开源的脑图编辑器,我们内部的 vue 脑图编辑器就是基于你开源的版本进行调整的,省了很多力。
目前已经封装成了独立的 vue 组件,方便各个 vue 工程直接接入。目前在内部申请开源中。
-
测试开发之网络篇 - 常用服务协议 at 2021年06月18日
学习了。
-
Light Merge 代码合并实践 at 2021年06月18日
文章概念略多,想确认下,Light Merge 是不是相当于:
1、从 master 拉出一个新分支
2、选择一堆开发完待测试的 feature 分支,逐个 git merge 到这个新分支
3、全部成功则可以基于这个分支进行测试,有冲突则提示信息,让开发改为手动 merge这三个点?
实际实践中,有个疑问点,修改 bug 是在 feature 分支上修,还是直接基于合并后的新分支修?是否会遇到某个功能,在单独 feature 分支独立没问题,但 merge 后的新分支有问题的情况?
-
2 年工作经验需要具备哪些技术 at 2021年06月18日
个人理解,2 年一般要求是一个独立的执行者 + 入门的协调者吧
1、可以独立 Hold 住中小型项目的整个测试过程,包括前期评审到测试到最后上线。
2、接口、UI 自动化至少两者有其中一者的经验,能基于工具或框架编写用例
3、对自己测试的系统整体架构有了解,自己测的最多的部分能说清背后怎么实现的
4、视野除了自己所在的小公司,还能看到一些行业的东西,比如接口测试除了自己用过的,还有什么流行的工具,大概优缺点是什么,不一定用过,但有一些了解。不过,实际上招聘不是看 2 年经验要有什么能力或技术,你是否符合,而是岗位要有什么能力或技术,你是否符合,然后再看你工作年限,年限只要不是过大一般没问题。2 年一般对应的是中级或者高级 title,可以参考下照片网站上这方面的岗位招聘要求。
-
测试开发之网络篇 - 常用服务协议 at 2021年06月18日
RPC 应该不算是协议吧?
-
基于百度脑图的用例增量保存 + diff 展示整体设计 at 2021年06月18日
明白。
避免用例丢失思路我们是一致的,都是保存历史记录,并支持一键恢复。
可以随时选择任意父节点进行拼接这个挺好的,可以像前面其中一位同学说的,可以任意组合用例库里的用例形成自己的测试计划。从目前大家使用上来说,这种场景比较少,偶尔遇到直接在脑图里复制粘贴也基本可以满足。后面如果需要这方面的特性,我们也参考下这个思路。感谢分享。
-
学习下 MQ at 2021年06月17日
语言很通俗易懂,也有很多例子,点赞!
针对消息不一致,分享下我接触过的系统做法:
首先,消费者在消费成功后通过同步请求或者另一条 mq 队列,反馈给生产者,生产者更新自己内部这条消息的状态为已处理。
同时生产者内置一个定时任务,查看内部所有待处理消息是否超时,如果超时,进行自动补偿。补偿大概步骤是
1、发起 http 同步查询给消费者,确认消费者是否有消费
2、若消费者反馈已消费,直接更新生产者自身内部消息状态
3、若消费者反馈未收到,则进行预警,人工介入处理(一般不会直接重发,因为重发有可能引发更严重的问题,如加剧 mq 消息堆积的情况) -
基于百度脑图的用例增量保存 + diff 展示整体设计 at 2021年06月17日
好奇问下,你们当时数据存储设计,把用例拆那么细的初衷是?每次读取完整脑图都需要各种连表查询重新组合,会不会对数据库造成比较大的负载?
文章中的思路应用到你提到的 “不想每次给到后端的 json 都是整个脑图”,其实也是可以的,json-patch 的生成改为由由前端来做就行了,这样就可以只提交 patch 内容给服务端(json-patch 和 json-merge-patch 两个格式设计初衷就是做 json 数据增量保存,节省大型 json 修改保存时的带宽用的)。至于统计每个人每天新建、修改了多少用例,个人理解已经不是增量保存的范畴了,应该用你说的加更新时间和更新用户信息会更好。
我当时整个 patch 生成的逻辑全部放服务端,主要 2 个原因。一个是找到的库是 java 的,另一个是冲突时后端有全量 json ,方便做整体备份避免丢失用例。从我们引入 agileTC 进行落地的整个经历看,对于用例平台来说,丢失写过的内容(哪怕是引起冲突无法保存的内容),是用户最无法容忍的问题,所以要尽一切努力去存储用户期望保存的内容。
-
基于百度脑图的用例增量保存 + diff 展示整体设计 at 2021年06月17日
tapd 也支持 xmind 测试用例?看介绍好像没提及。
-
今天京东 APP 地址信息被修改且差点被电信诈骗 at 2021年06月17日
可以问下在京东里面的测试同学帮查,这方面信息客服不一定能看到。
-
今天京东 APP 地址信息被修改且差点被电信诈骗 at 2021年06月17日
这个得京东内部查下登录方式了。一般这种大型 app,除了用账号密码,还可能会提供别的登录方式。
-
基于百度脑图的用例增量保存 + diff 展示整体设计 at 2021年06月17日
不同团队可能需求不一样。我们这的优先级、自定义标签,用得还挺多的。
比如写用例的时候,有些地方需要用例评审时特别关注,就打个【待确认】标签。
比如给开发自测用例的时候,一般就直接给 P0 优先级的 -
今天京东 APP 地址信息被修改且差点被电信诈骗 at 2021年06月17日
信息留言放在地址管理这个挺奇怪的,感觉真的有点像地址管理的其中一个对外暴露的接口鉴权有漏洞。
-
Seldom 2.0 - 让接口自动化测试更简单 at 2021年06月17日
这种算是测试用例里面的前置条件吧,类比测试框架里的 @Before 类方法。这种场景很常见。
至于是每次生成订单,还是写死固定几个不会改状态的订单 id,就要根据实际情况来选择了。
-
关于递归找出依赖用例,请教一下各位大佬 at 2021年06月17日
依赖检测找到另一个算法,看起来逻辑比有向图判断环更简单,可以参考下:
https://github.com/scarcoco/projx/issues/38 -
关于递归找出依赖用例,请教一下各位大佬 at 2021年06月17日
1、是不是需要做下循环依赖的校验?比如 1 依赖 2,2 依赖 3,3 依赖 1 这种。
2、这里最深的 if 已经是第四层了,嵌套略深,而且也缺少对 step id 没有对应 api_id 这种异常情况的检测,目前只是直接忽略返回空列表,而非抛异常。
3、有一个场景没有描述,比如 1 依赖 2、3,2 和 3 都依赖 4。此时应该生成的是 [4, 2, 3, 1] ,还是 [4, 2, 4, 3, 1] ?按照目前实现,会出现的应该是后者。建议按照这几个信息,分块编写相关逻辑:
- 递归结束条件:step 数组内元素个数为 0、值为 null 或者不存在此 key
- 每次递归需要进行的操作:把依赖的 step id ,在验证确认对应 id 的用例存在后,加到执行顺序列表中当前 step 的前面
- 其它需要抛出异常的场景:循环依赖校验、step id 在用例列表中不存在
同类逻辑 java testng 框架的 depends 逻辑也有类似实现,建议也可以参考下。
-
基于百度脑图的用例增量保存 + diff 展示整体设计 at 2021年06月16日
哦哦,明白。
和我这块确实不大一样。我这里的 diff 除了展示,还需要具备给用户直接复制粘贴,重新应用的能力,所以展示方式使用了脑图,而不是 json 之类的纯文本展示方式。
我的展示效果大概是这样的:
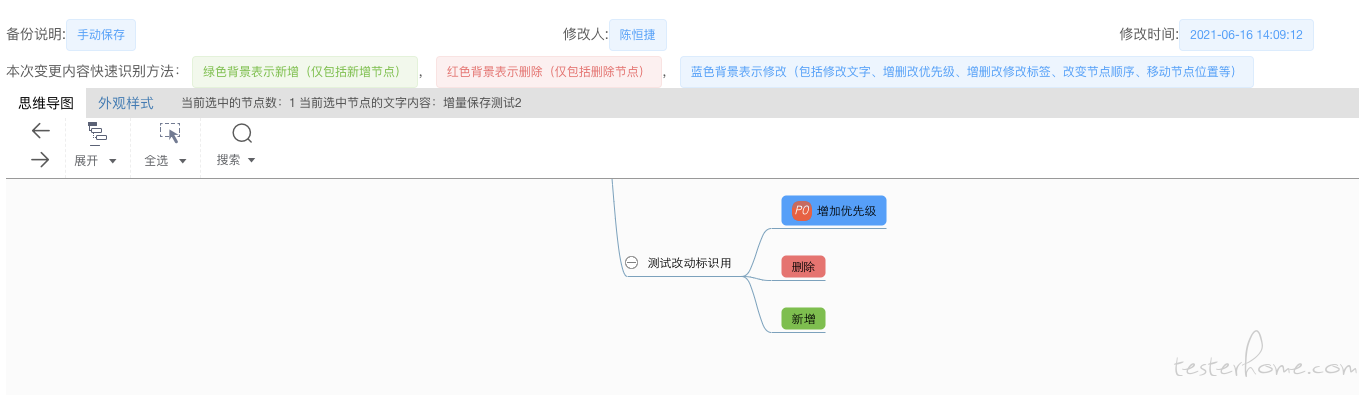
-
基于百度脑图的用例增量保存 + diff 展示整体设计 at 2021年06月16日
服务端相关的代码改动及配套单测,已提交 PR 给官方。地址:https://github.com/didi/AgileTC/pull/93
增量生成、应用、标记的逻辑全部在
case-server/src/main/java/com/xiaoju/framework/util/MinderJsonPatchUtil.java这个工具类配套单测在
case-server/src/test/java/com/xiaoju/framework/util/MinderJsonPatchUtilTest.java -
基于百度脑图的用例增量保存 + diff 展示整体设计 at 2021年06月16日
哈哈,看来大家都殊途同归。
下面介绍的 start end 坐标字段,有点没太理解具体是什么的坐标。可以写个示例么?目前节点坐标信息我是通过 json-patch 里面的 jsonPointer 直接拿的。对于子节点数组型用下标会不准,我是先把 array 都转成 object ,key 是节点里 data.id 的值。