-
谷歌开源模糊测试工具 ClusterFuzz 尝鲜记录 (进行中) at 2019年02月20日
细想了下,好像也不是邓爷爷说的。我还是改为 曾有人说 比较正规把。
-
谷歌开源模糊测试工具 ClusterFuzz 尝鲜记录 (进行中) at 2019年02月19日
官方文档没提到 Fuzz 生成规则,只是大致提到了可以根据测试的代码覆盖率等数据自动优化生成的数据集。fuzz 生成器是是使用其它开源工具实现的,不是 ClusterFuzz 本身的内容。后续再细看下相关的资料。
-
谷歌开源模糊测试工具 ClusterFuzz 尝鲜记录 (进行中) at 2019年02月19日
不一定是浏览器,应该只要是 C/C++ 都可以。比如 openssl 。
-
谷歌开源模糊测试工具 ClusterFuzz 尝鲜记录 (进行中) at 2019年02月19日
不能说所有,但可以相对低成本的检查内存溢出类问题。
-
个人互联网接口自动化遇到的问题回顾 at 2019年02月15日
1、思路上可以考虑在参数组合的表格里手动加一列,作为断言。然后根据这个列来生成对应的断言
2、你说的这个优惠券不能重复跑场景,个人觉得核心点是把造数据和测试用例分开。造数据保证每次都给出一个可用的数据(如未使用的优惠券 id),用例就直接用数据好了,而且这个造数据还可以提供给非自动化测试时用。
整体初始化数据库这种方法,对于单体应用可用,但对于涉及多个服务的应用(每个应用有自己的缓存、数据库)就不行了。 -
如何进行 UX 自动化测试 at 2019年02月14日
yy 一下
1、UX 把设计稿输出图片,且图片是 1:1 比例,和实际软件生成的大小是一致的
2、把软件生成的控件,进行截图。注意此时的颜色、文字显示尽量和设计稿保持一致
3、用截图对比软件对比两个图的差异度,要求差异度在 xx% 内话说,一般 UX 都不会较真到像素级别吧。毕竟现在移动端分辨率这么多, UX 设计稿不可能针对各个分辨率都出一个,和设计稿分辨率不一样的一般都是 UX 主观判断是否可接受。
-
appium 这个 id 为什么取不到呢 at 2019年02月13日
我用 appium desktop 试了下,貌似是可以找到的哦。
appium desktop 版本:1.8.2.20181101.4
手机 android 版本:5.1
抖音安装包:大概 2 天前官方下载的,文件名: app_aweGW_v4.3.3_84a2a6f.apk
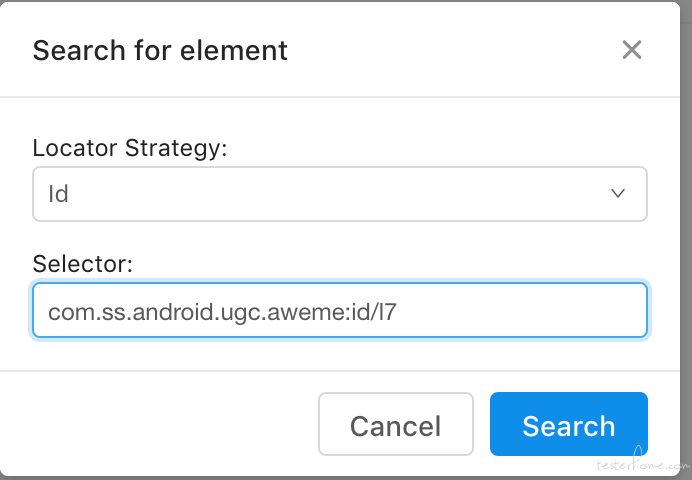
搜索日志:
[HTTP] --> POST /wd/hub/session/3ac01ec6-d048-4e5d-ac0b-cfd64ba010eb/elements [HTTP] {"using":"id","value":"com.ss.android.ugc.aweme:id/l7"} [MJSONWP] Calling AppiumDriver.findElements() with args: ["id","com.ss.android.ugc.aweme:id/l7","3ac01ec6-d048-4e5d-ac0b-cfd64ba010eb"] [BaseDriver] Valid locator strategies for this request: xpath, id, class name, accessibility id, -android uiautomator [BaseDriver] Waiting up to 0 ms for condition [AndroidBootstrap] Sending command to android: {"cmd":"action","action":"find","params":{"strategy":"id","selector":"com.ss.android.ugc.aweme:id/l7","context":"","multiple":true}} [AndroidBootstrap] [BOOTSTRAP LOG] [debug] Got data from client: {"cmd":"action","action":"find","params":{"strategy":"id","selector":"com.ss.android.ugc.aweme:id/l7","context":"","multiple":true}} [AndroidBootstrap] [BOOTSTRAP LOG] [debug] Got command of type ACTION [AndroidBootstrap] [BOOTSTRAP LOG] [debug] Got command action: find [AndroidBootstrap] [BOOTSTRAP LOG] [debug] Finding 'com.ss.android.ugc.aweme:id/l7' using 'ID' with the contextId: '' multiple: true [AndroidBootstrap] [BOOTSTRAP LOG] [debug] Using: UiSelector[RESOURCE_ID=com.ss.android.ugc.aweme:id/l7] [AndroidBootstrap] [BOOTSTRAP LOG] [debug] getElements selector:UiSelector[RESOURCE_ID=com.ss.android.ugc.aweme:id/l7] [AndroidBootstrap] [BOOTSTRAP LOG] [debug] Element[] is null: (0) [AndroidBootstrap] [BOOTSTRAP LOG] [debug] getElements tmp selector:UiSelector[INSTANCE=0, RESOURCE_ID=com.ss.android.ugc.aweme:id/l7] [AndroidBootstrap] [BOOTSTRAP LOG] [debug] Element[] is null: (1) [AndroidBootstrap] [BOOTSTRAP LOG] [debug] getElements tmp selector:UiSelector[INSTANCE=1, RESOURCE_ID=com.ss.android.ugc.aweme:id/l7] [AndroidBootstrap] [BOOTSTRAP LOG] [debug] Returning result: {"status":0,"value":[{"ELEMENT":"5"}]} [AndroidBootstrap] Received command result from bootstrap [MJSONWP] Responding to client with driver.findElements() result: [{"ELEMENT":"5"}] [HTTP] <-- POST /wd/hub/session/3ac01ec6-d048-4e5d-ac0b-cfd64ba010eb/elements 200 194 ms - 89有一个点要特别留意,如果视频在播放,此时页面处于动态状态,控件树是不会 dump 出来的。得暂停了视频后才能比较快地 dump 出来。具体原理可以百度下 uiautomator dump 控件树原理相关的文章。
-
appium 这个 id 为什么取不到呢 at 2019年02月13日
有试过对比 page_source 获取到的 xml 树,和 uiautomatorviewer 相比,缺少了哪些元素吗?
按以前经验,确实会有部分元素 viewer 可见,page_source 不可见,例如 webview 里面的元素。但从你的 viewer 截图上看,这个控件及它的上层所属的类应该都是原生布局,不大像是 webview 里面的元素。
-
appium 这个 id 为什么取不到呢 at 2019年02月13日
这个是 find_element 的日志,不是 page_source 的日志吧?
另外,实际界面上,这个元素真的有出现了吗?能否也截个图看看?
-
appium 这个 id 为什么取不到呢 at 2019年02月12日
page_source 时,可以同时也留意下 appium 的日志,看有没有什么异常。
-
appium 这个 id 为什么取不到呢 at 2019年02月12日
建议在 find 函数加个断点,然后在断点的时候通过 page_source 获取下界面的控件树,看是不是控件树和 uiautomatorviewer 看到的有出入。
-
个人互联网接口自动化遇到的问题回顾 at 2019年02月10日
这样用例量以及时间花费仍然很大,在实际项目中测试人员没有充足的时间来进行用例编写,那么去即不降低用例的覆盖场景,又能快速编写用例呢??
最近也有遇到类似的问题,暂时解决办法是提测前先覆盖冒烟场景,非核心场景有时间且有必要重复执行,就补充编写自动化用例,否则半自动化(在已有代码基础上手动改参数)。
思路上,可以试试基于接口 API 文档(引入 swagger 注解可以自动生成)自动按照数据类型,通过参数组合生成测试用例,对于单接口参数构造方面的场景用例编写会有一定程度的效率提升。
-
学习测试 aapt 取不到 activity 怎么办? at 2019年02月10日
dabging这个命令拼错了吧?aapt dump --help ERROR: Unknown option '--help' Android Asset Packaging Tool Usage: aapt l[ist] [-v] [-a] file.{zip,jar,apk} List contents of Zip-compatible archive. aapt d[ump] [--values] [--include-meta-data] WHAT file.{apk} [asset [asset ...]] strings Print the contents of the resource table string pool in the APK. badging Print the label and icon for the app declared in APK. permissions Print the permissions from the APK. resources Print the resource table from the APK. configurations Print the configurations in the APK. xmltree Print the compiled xmls in the given assets. xmlstrings Print the strings of the given compiled xml assets.官方命令里没有说通过 badging 一定可以获取 activity 信息的。建议改为用其它获取主 activity 的方法,例如获取 apk 的 AndroidManifest.xml 内容。
-
appium 这个 id 为什么取不到呢 at 2019年02月10日
你的 id 是怎么找到的,uiautomatorviewer 截图发下?
-
monitor.bat 无法连接设备是什么原因? at 2019年02月10日
全是 unable ,建议确认下会不会是 android sdk 版本太低?
-
社区要不要限制每一个账号每天的发帖数 at 2019年02月06日
对于每天发帖数,内部有讨论过是否需要限制,但最终没能达成一致,所以目前还是没有限制的。针对你提出的情况,我们按照具体情况,一般会屏蔽一部分避免引起刷屏。
后续也会推出举报功能,便于大家主动反馈给管理员,便于我们更及时处理。
-
Jenkins 集成 maven 自动化项目,构建成功未执行项目以及构建后工作区 Excel 文件显示乱码 at 2019年01月30日
不知道你用的是具体什么方法什么路径来读取和写入 excel ,不好判断你这样有没有问题。但有几个点可以肯定:
1、你本地运行的方式和 Jenkins 不完全一样,目测 Jenkins 运行并没有把 maven resources 文件一并拷贝到 target/classes 中,但你本地运行有。建议你本地和 Jenkins 用一模一样的命令来运行,再把结果作对比。
2、target 下面的文件都是构建产物,每次构建都有可能发生改变,不应该纳入 git/svn 进行版本管理。但你的截图里能看出它们都被纳入管理了(有绿色的勾)不大清楚你是根据什么教程入门学习的,但建议你找一些比较专业全面的教程学习下,太速成的只追求能跑,不追求规范,容易遗漏这些小点,而这些点才是体现专业的地方,也是避免你踩各种坑的捷径。
-
非 IT 转测试行业的新人,该如何规划自己的职业发展道路 (现阶段很迷茫) at 2019年01月30日
你有这样的迷茫,我理解是你开始对工作上的重复感到无趣,但一扩展又发现东西太多,不知道从何下手好。
建议先全身心投入工作,把工作中不懂的都弄懂,然后你会发现有些重复其实没必要,有些地方自己没想到。这段时间你可以对你接触到的东西做比较深入的学习,也可以借此探索你的兴趣点。
等到自己觉得已经对现有的东西都很熟悉后,把你了解的整理一个思维导图,再通过咨询你的导师或者身边有一定经验的朋友了解更长远的路,再做打算。
-
Jenkins 集成 maven 自动化项目,构建成功未执行项目以及构建后工作区 Excel 文件显示乱码 at 2019年01月30日
1、数据库数据没有生成,是不是就没有执行项目?
不知道你的项目具体做了什么操作,建议可以加一些关于写入数据库这个操作的日志打印(前面学习直接 System.out.println 就好,后续正式项目记得换成专业的 logback ,否则会显得是个很业余的初学者),通过确认这些日志有没有出现来确认有没有执行。
2、构建以后工作区 Excel 文件打开显示乱码
excel 文件不是文本文件,有一些二进制的部分(可以理解为硬要当文本文件打开,就会显示为乱码的东西),所以不能通过直接查看工作区来看内容(Jenkins 默认没有微信那么强大,没有集成 excel 预览功能),需要下载下来再打开查看。如果下载了查看还是乱码,再另外处理。
-
Docker 学习笔记合集第一季 —— image container 基本操作 at 2019年01月29日
博客系统 mysql 挂了,貌似系统有点问题。最近比较忙,过年的时候闲一些再修复。
建议你可以看看官方的文档,我这个文档有点年头了,和最新的已经有比较大差异了,不建议参考。
-
TesterHome 我的收藏网页标题错误 at 2019年01月26日
感谢指出。
按照您的操作步骤,我进入了我的收藏页,但没能复现您截图中的问题,可以看到页面标题是可以正常显示的(图中红色箭头所指部分),请问能否更详细地描述下您的步骤?

-
拼多多事件对我们业务测试的启发 at 2019年01月26日
之前没出过问题,不代表没问题。
有人愿意承担责任,不代表他能承担的起。
尽量不要基于个人经验做出全局的判断。
存在不确定性的情况下,一定要在可控的情况下进行逐步验证。这几句点赞!经验主义,有时候换个角度看就是侥幸心理。
-
2018 年 度个人测开账单 at 2019年01月26日
自动化平台搭建这个,1 年内就完成,并且有这么多资源,很不错呀!
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月25日
应该有吧,我们公司也有搭纯 kityminder 的。具体没研究过
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月23日
统一回复: 平台后续会做一次分享,开源方面因为还有其它公司定制功能在里面,暂时无计划。