-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月23日
研发投入 2 人 3 个月左右。
我们走小迭代,前期核心功能 1 个月发版,后续迭代 1 周 1 个小版本 -
WebDriverAgent 踩坑记 at 2019年01月23日
建议你另外开贴,记录下你的详细步骤和关键代码吧?只有一个日志不好确定是哪里有问题。
-
21 天,搞定软件测试从业者必备的 Linux 命令 (完整篇) at 2019年01月17日
我一般只记住命令名字,用法直接 tldr 。不过写得还是挺全的。
PS:好像漏了 sudo 、su 这两个很常用的命令?
-
testerhome iOS 版放大图片闪退 at 2019年01月13日
@Maya 能否在您的手机上手动重现下?之前没开 bugly 收集崩溃,现在刚打开,如果可以重现,可以尝试几次,后台应该可以收集到崩溃日志。
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月10日
我们做这个统计倒不是信任问题,而是有的大项目测试周期比较长,参与人数、用例数也不少,统计这个可以方便作为每天进度参考,也方便负责人比较准确地确认进度有没有问题。
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月09日
你们是怎么做的?
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月09日
用户直接在平台的用例上手动登记(定义了几个特定标签用于通过、失败),暂时还没做进一步的关联。
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月09日
你说的追踪具体是指?
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月04日
截图来了:
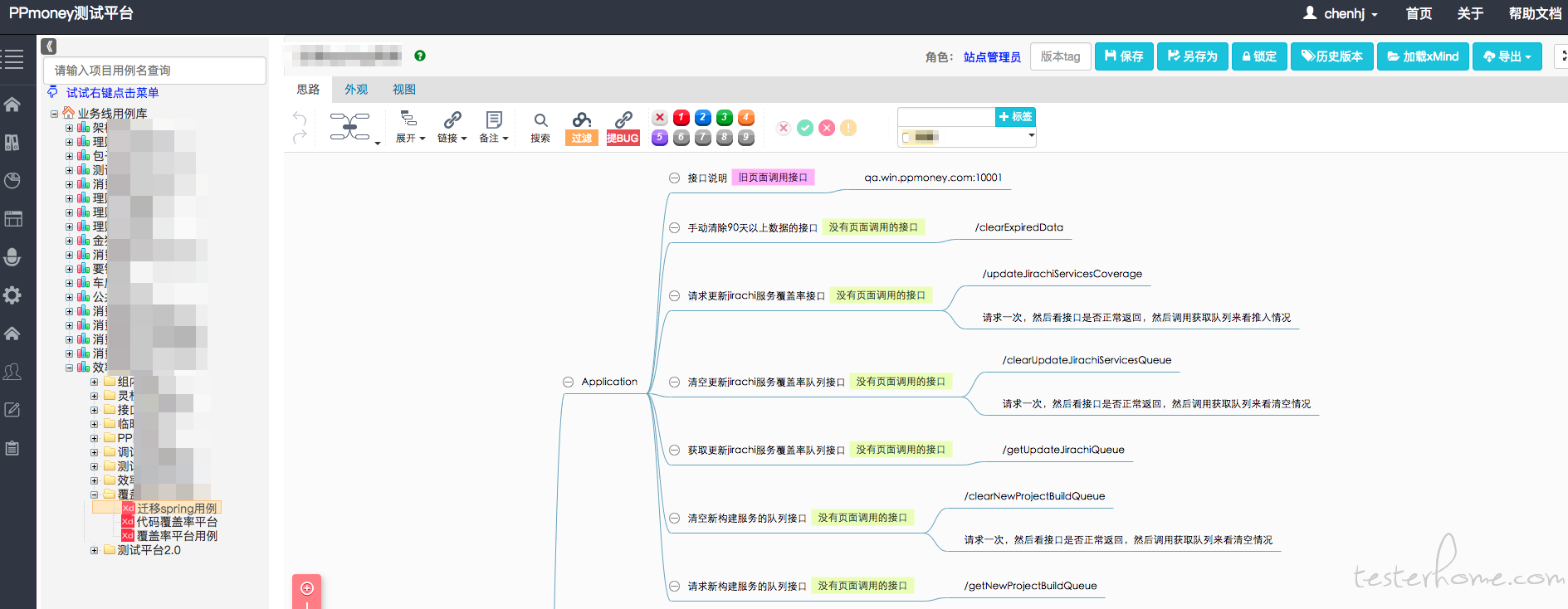
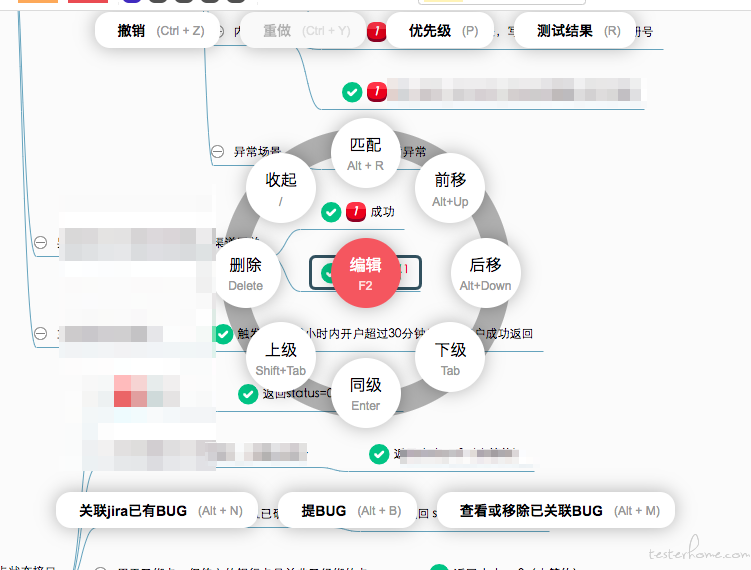

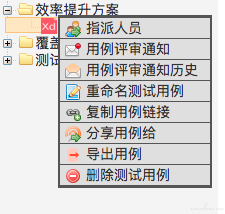
目前主要会通过这个平台进行用例的编写、任务的指派、执行结果的登记及统计。目前内部推进开发自测也是通过平台来给用例和登记自测结果,便于统计和记录。
-
边界值有没有意义? at 2019年01月03日
如果说边界值有没有意义,当然是有意义的。
至于意义有多大,相关问题是否需要修复,就要按照优先级来了。技术人员需要重点关注产品的核心功能,如果核心功能都没法保障,那边界值问题自然不会被重视。
另外,我理解任何系统对于一个输入值的大小一定是有限制的,比如 UI、接口(如 nginx 限制单个请求大小,http url 最大长度限制)、数据库(字段长度)。超出长度就会出现问题,可以看看这个机制的极限值是多大,是否能满足产品需要(建议重点看看数据库字段长度),超过极限值程序会如何处理(直接截取?报错?)。之前我们曾经出现过一次由于超出极限值系统直接截断而没有报错的问题,导致原始数据缺失,影响还是很大的。
如果不满足,那就明确提出和要求更改。
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月03日
是的,主要是团队的小伙伴给力。
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月03日
是的,你也来一个?
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月03日
就是 TesterHome 的公众号呀
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月03日
一起加油!
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月02日
明天上班再截一些图上来,主要是基于百度 kityminder 做的,在它基础上加了一些一键记录测试结果、关联 jira 、过滤用例、多人协作自动合并等功能。
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月02日
谢谢~你也要保重身体哦
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月02日
谢谢支持~
-
我的 2018 总结——工作很苦,生活很甜 at 2019年01月02日
暂时满足当前工作的需要了,进入维护阶段。后续重心会先转移到研测一体化,做到测试环境可快速搭建快速使用。
-
资损防控体系介绍 at 2019年01月01日
加精理由:从资损角度对系统线上问题进行防控,思路和方法非常具有参考价值。
-
testerhome 楼层显示错误 at 2018年12月30日
https://github.com/testerhome/homeland/issues/83
我本地环境无法复现,而且从代码上看也不大应该会出现。你看下会不会是服务器上部署配置引起的?
-
ExtentReports 生成漂亮的测试报告 at 2018年12月30日
说的挺细,但感觉和官方文档基本一致,没看到你想分享的点。
能否多一些思考选型方面的说明,或者说下踩了什么坑,怎么填的?
-
如何向整个测试部推广自己二次封装的自动化测试框架 at 2018年12月30日
如果是设计时就不想有太大偏差,建议是开发之前,就需要进入项目或者和项目人员深度交流,了解大家最需要什么,项目特点是什么。比如项目如果是流程较长,链路较长型的,单个接口如果没有准备好数据很难测试,那就需要能比较简单就可以把多个用例组装起来,达到可以符合流程自动化执行的目标,方便快速把数据造起来。
然后框架有个雏形后,就轮岗进入项目中,自己加上少数项目中对这个有兴趣的同学一起作为先锋把最需要自动化的几个用例用自己的框架实现并在项目中跑起来,然后再推广。这个时候你可以针对项目说出很多接地气的例子,大家也就更容易接受,不会自嗨。
你的想法也不错,写完一个模块就和手工联调,及时修正。如果可以,建议问下有没有一些手工对这个有兴趣,抽出 30%-50% 的时间陪你一起做,这样沟通更多,修正也更快。
-
如何向整个测试部推广自己二次封装的自动化测试框架 at 2018年12月29日
如果大家对 RF 并不是特别熟悉,我觉得 RF 的对比不大需要太突出。一个新框架本来就有学习成本,还多加一个对比,成本更高了。
建议突出自动化的好处(手工一起参与编写,写完后不用乏味地重复劳动),以及你的框架如何简单易用(如 xx 步写好一个自动化测试用例,套路一定要简单,容易听懂),让大家产生试用的冲动就达到目的了。
起步阶段,很多 pytest 的特性其实不大需要介绍,否则会让大家觉得复杂兴趣消退。只需要介绍起步阶段最常用的几个就好了。
另外:强烈建议先找个合适的团队(感兴趣、有技术底子)试点,丰富你的实际使用案例,再全面铺开,会顺利不少。
-
容器管理平台 rancher 简介 at 2018年12月29日
可以通过 rancher 的 api 来完成测试环境的部署,甚至是 ui 自动化、接口自动化工具运行环境的自动创建和执行。
-
容器管理平台 rancher 简介 at 2018年12月29日
这个就不大清楚了,目前没尝试过他们的结合。
其实主机这个一般使用不用太关注,除非是运维人员。