-
录制线上流量做回归测试的正确打开方式 at December 30, 2020
是啊,落实下来工程量还是很大的
-
录制线上流量做回归测试的正确打开方式 at December 30, 2020
写接口是不能直接回放的,会涉及到很多数据操作和脏数据的问题。
如果要回放,需要代码入口处封装一层 fakeDB,然后实现 fakeSqlQuery,然后所有符合某种规则的 sql 都 mock 返回一致的数据。
-
从业务测试需求痛点到自动化测试平台设计开发 at December 29, 2020
大部分人不会用自动化,所以这个就是平台做出来就是为了给不会代码的人用的,因为只需要在点点点的时候开启录制即可。业务简单的 点点点更高效,是点点点更快,但是回归呢?自动化本身意义是回归。UI到底关注什么 首先是功能吧,我的业务需求其实是更关注埋点,当然功能也关注。我不提倡大家都一股脑去做什么平台,先仔细想想自己公司需求是什么,你怎么做能提高效率,这个你说的对,所以我这篇文章的核心其实是从业务测试需求痛点到自动化测试平台设计开发,出发点要对,不然就是盲目开发,你应该详细看看文章。建议在工作中 找到提高效率的本质方法 万变不离其宗。当需求足够时 引入或者自建 改造 适用于自己的才是最好的。对的,核心就是为了提高回归效率和测埋点的效率,所以这个平台就是自建开发适用于我们业务测试的平台。
分享出来的目的主要是两点:
我是如何从业务测试痛点里面去找可以提高效率的点
除了传统的 python/java + selenium/appium,我们还能怎么样做 UI 自动化平台
-
从业务测试需求痛点到自动化测试平台设计开发 at December 25, 2020
首先,登录问题可以用万能 token 做处理,对于所需的业务数据,其实用 mock 做处理直接返回,不需要真正请求到后端,然后只校验 UI 的正常显示,关于数据逻辑校验的还是放到接口测试来做。
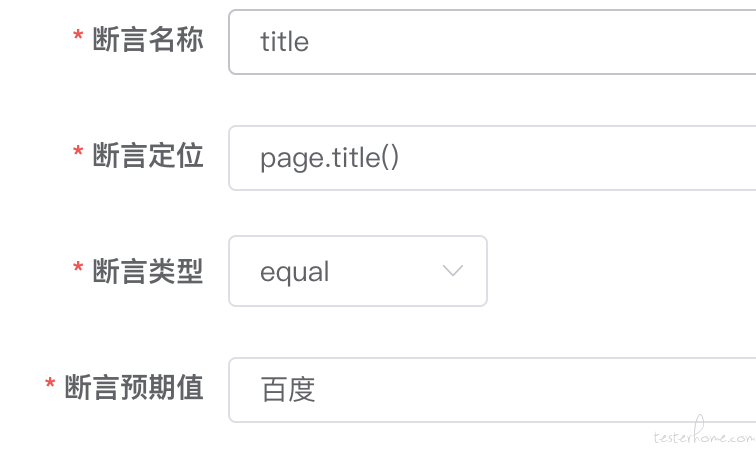
断言的话,不用写在脚本里面,在用例里面配,不过确实要自己定位加,比如这样。
-
从业务测试需求痛点到自动化测试平台设计开发 at December 25, 2020
第一,自动化代码能够做到
修改一两处就能维护好这些受影响的用例,我感觉其实更花精力,还必须得项目很稳定。
第二,修改一两处就能维护好这些受影响的用例,这种情况太理想了,更多时候 UI 是全部大改的,代码基本要重写。而且你要应用的项目不止一个,有 N 个项目都在迭代更新,真的能有这么多份写好的自动化代码吗?
第三,本身手工测试,就是要点点点,只不过这次,在 dev 环境点完了,开了录制,接下来就可以在 test / staging / release 上快速回归,不需要投入会写代码的人力物力。
第四,如果真的能够定位到修改一两处就能维护好这些受影响的用例,其实对于录制来说,真的不用重新录,把某些改动的地方匹配替换一下就行了。 -
从业务测试需求痛点到自动化测试平台设计开发 at December 25, 2020
不用维护,哪些 UI 改了就重录替代用例,快录快用。目的是没改的快速回归,以及很多第三方的置入功能,比如 mock 比如 埋点监听 等等。
-
从业务测试需求痛点到自动化测试平台设计开发 at December 25, 2020
愿闻其详
-
从业务测试需求痛点到自动化测试平台设计开发 at December 25, 2020
目前只做了基于 puppeteer 的,mitmproxy / anyproxy 都可以扩展兼容。
-
从业务测试需求痛点到自动化测试平台设计开发 at December 24, 2020
持续思考,持续进步 hhh
-
面试:如何回答你能给我们带来什么价值? at December 21, 2020
正解
-
Locust 从入门到实战 at December 01, 2020
真要看重性能,可能你得看下 boomer
-
docker 和自动化脚本 --python 栈 at November 20, 2020
......
-
录制线上流量做回归测试的正确打开方式 at November 19, 2020
时间戳,上下游响应之类的关联信息,你要想伪造那份 log 不好搞,不如直接自己写个 log 生成 request 的发生器
-
UI 自动化测试集成监听 url & mock url & 埋点测试功能 at November 11, 2020
因为我用的是 mac 当然这样写。Chromium 又不是只有 mac 版本,换一下就行。
-
字节游戏测试 (外包岗位) at November 06, 2020
不要去外包!
不要去外包!
不要去外包! -
在自动化测试里,可以一边网页 / 手机自动化测试,一边动态刷新日志吗? at November 03, 2020
可以的,你在执行的时候保存下 log,然后写个页面每次去获取这个 log,解析一下包装成你想要的数据就行了。
-
boomer 基于 gRPC 压测并发方案及性能测评 at October 30, 2020
才看到 hhh
是鸭,趋势所在 -
docker && k8s 分布式压测 locust_boomer 方案 at October 29, 2020
那就是 grafana 里面设置连接数据库的信息不对。
你选 server 模式的时候,不能写 http://localhost:9090 http://127.0.01:9090,要填本机的真实 ip 地址。
-
七牛云 goc docker 部署 at October 29, 2020
传错地方了,已上传,再试一下~
-
七牛云 goc docker 部署 at October 28, 2020
要带 tag,docker pull shaonian/goc:v1.0
你直接用 docker-compose 起不就完了,干嘛一个个单独拉。
-
docker && k8s 分布式压测 locust_boomer 方案 at October 28, 2020
你不是用 docker-compose.yml 起的吗
-
docker && k8s 分布式压测 locust_boomer 方案 at October 28, 2020
你应该还没有执行压测吧,没有执行压测那肯定没有测试数据。
如果不是这个问题,就得看看容器的日志,你截图页面没啥意义。
还有要注意一下 grafana 里面配置 prometheus 的一些连接信息,这里不对也会这样。
-
求助求助 win10 下 安装 docker 后 ,启动报错了 at October 21, 2020
你这个是 window 10 家庭版,不是专业版,没有打开 Hyper-V 的选项。
要打开这个才能装 docker。
-
录制线上流量做回归测试的正确打开方式 at October 19, 2020
hhhhh
-
为什么要做自动化? at October 16, 2020
直接代码层面引入第三方插件,智能生成 api 文档。(比如其他人说的 swagger)
脚本实现,抓数据,手写转 swagger 格式。
借助第三方平台实现,现在 yapi 接口管理平台可以导入 har 当文档了,对你来说,应该是最佳选择鸭。