---------------- 2020.07.28 更新 ----------------
1.提供 grpc 压测的 docker-compose 部署方案。
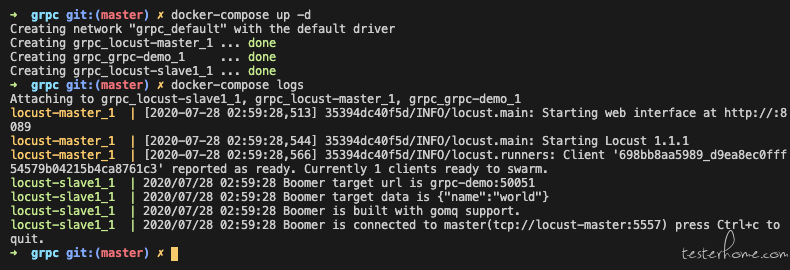
2.提供 shaonian/grpc-demo, shaonian/locust-slave-rpc 开源镜像。
locust-slave1:
image: shaonian/locust-slave-rpc:latest
command:
- ./helloworld.pb
- --master-host=locust-master
- --master-port=5557
- --url=grpc-demo:50051
- --data={"name":"world"}
links:
- locust-master
- grpc-demo
3.优化 github README 文案。
详情见: https://github.com/ShaoNianyr/boomer_locust
---------------- 2020.07.24 更新 ----------------
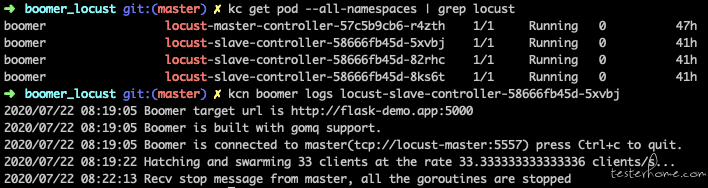
优化 slave 镜像,对非任务比重型的压测任务,提供动态指定 targetUrl 的方式,无需频繁构建镜像。
./target --master-host=locust-master --master-port=5557 --url=http://flask-demo:5000
效果如图所示:
---------------- 2020.07.20 更新 ----------------
前言
为什么要做这样的一个方案
很多时候,我们对外暴露的 API 很少,如果仅仅对暴露的 API 做压测,不能够达到想要的压测结果,或者是对外暴露的 API 做了限流的限制,会将压力挡在外面。像 docker & k8s 有很多定制开发的内容服务或组件,只能在内部访问,无法对外暴露(应该是对外暴露不安全,不能暴露),所以希望压测能够作为 k8s 的一个内部组件,对其他可通信的内部组件,进行压力测试。
这里采用 docker-compose 的方式来编排容器,k8s 的 demo 后续会更新。
为什么不用 Locust
先简单说下什么是 Locust,主要是基于 python 的 gevent 实现的伪并发来产生压力。实现方式比较多样,可以手写编程函数,丰富可测试的范围,并配置并发占比,模拟真实用户。
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(5, 15)
@task(2)
def index(self):
self.client.get("/")
@task(1)
def about(self):
self.client.get("/about/")
这个是一个简单的 demo,展示的是用户会随机等待 5-15s 发起请求,并发策略是三分之一的并发量请求 /,三分之二的并发量请求 /about。测试很有场景性,而且可以将压测作为一个函数来编程,可以根据项目来进行改造适配,通用测试很多系统。
当然,受限于 python 语言本身 GIL 锁的限制,高并发下很不稳定,给的压力也一言难尽。所以不用 Locust,显然易见。
当然如果不需要很高压力的情况下,是可以考虑使用 Locust 的,因为提供的场景很丰富。而且 Locust 支持分布式,一个 4 核 CPU 的服务器,可以设置 1 个 master 和 3 个 slave 来产生压力,进一步提高性能。
为什么用 Boomer
Boomer 其实还是 Locust,只是在 Locust 的基础上,进一步提升了可产生的压力。上面提到,Locust 打开分布式的时候,会产生 1 个 master (python) 和 3 个 slave (python),而 Boomer 打开分布式的使用,会产生 1 个 master (python) 和 3 个 slave (go),也就是还是有 locust-python-master 来作为管理中心,但是实际执行的 locust-python-slave 变成了 boomer-go-slave。
这样做的变化:
- 原来的并发基于 python 的 gevent 进行实现,现在是用 goroutine 的方式,进一步提高了并发的方式。
- 原来 Locust 并发的是用户这个概念,Boomer 里面没有用户的概念,并发的是函数。
Locust & Boomer 缺点
压测数据展示用的是 Locust 建议的 web 界面,数据不能存储,刷新就没有了。
这点好办,可以改造一下,添加 promethues 作为数据库来上报数据,用 grafana 来展示,已经有实现方案了,在 Boomer 项目里面,使用 prometheus_exporter.py 启动 locust-master。
locust --master -f prometheus_exporter.py
项目
项目 demo:shaonian/boomer-locust 欢迎来 star ~
原理:把压测也作为 k8s 内部的一个组件提供服务,那么对内访问的通道就被打开了,这样我们就可以直接在集群的内部产生我们想要的压力了。
demo 分析
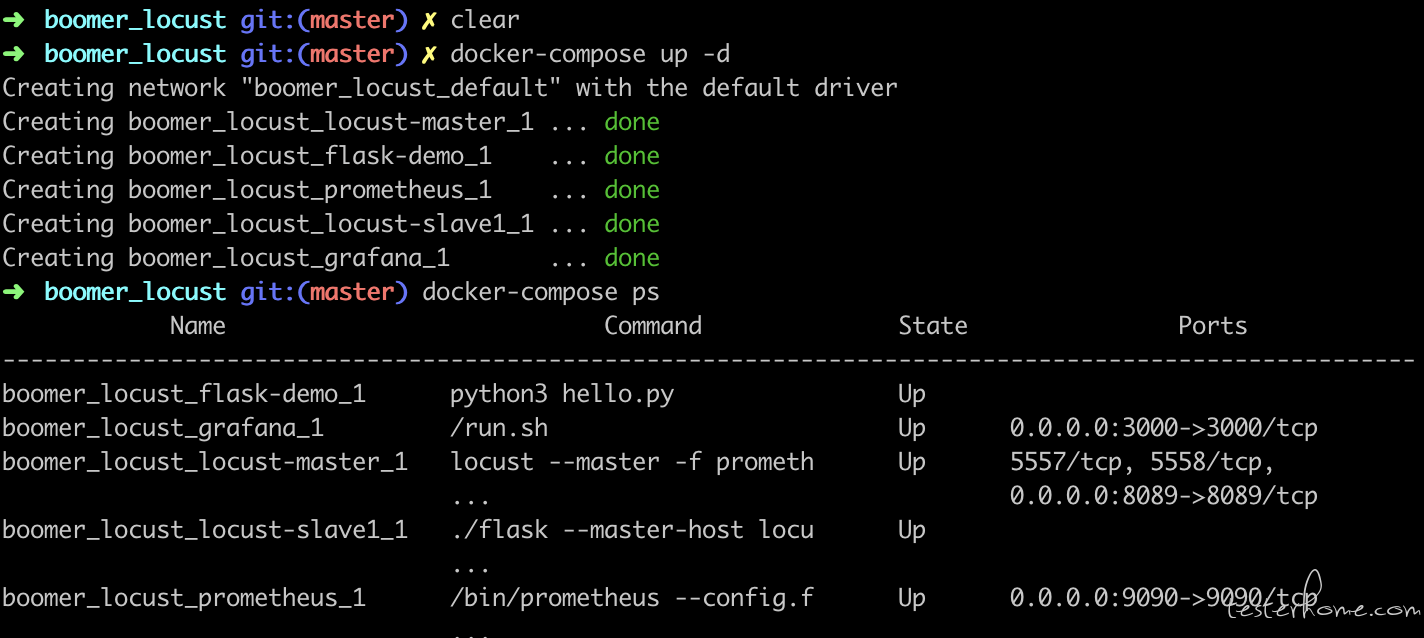
如上图所示,flask-demo 是一个简易的服务器,我已经取消了对外暴露的访问,只有在集群内部才能访问到,于此同时,locust-master & locust-slave 也作为一个容器服务,同在一个集群网络中。locust-master & locust-slave & flask-demo 的镜像均已打包好, docker-compose.yml 详情如下:
version: '2'
services:
prometheus:
image: prom/prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/data:/root/prometheus/prometheus-data
links:
- locust-master
ports:
- "9090:9090"
grafana:
image: grafana/grafana
volumes:
- ./grafana/data:/var/lib/grafana
links:
- prometheus
ports:
- "3000:3000"
flask-demo:
image: shaonian/flask-demo:latest
locust-master:
image: shaonian/locust-master:latest
ports:
- "8089:8089"
locust-slave1:
image: shaonian/locust-slave:latest
command:
- ./flask
- --master-host
- locust-master
links:
- locust-master
- flask-demo
# locust-slave2:
# image: shaonian/locust-slave:latest
# command:
# - ./flask
# - --master-host
# - locust-master
# links:
# - locust-master
# - flask-demo
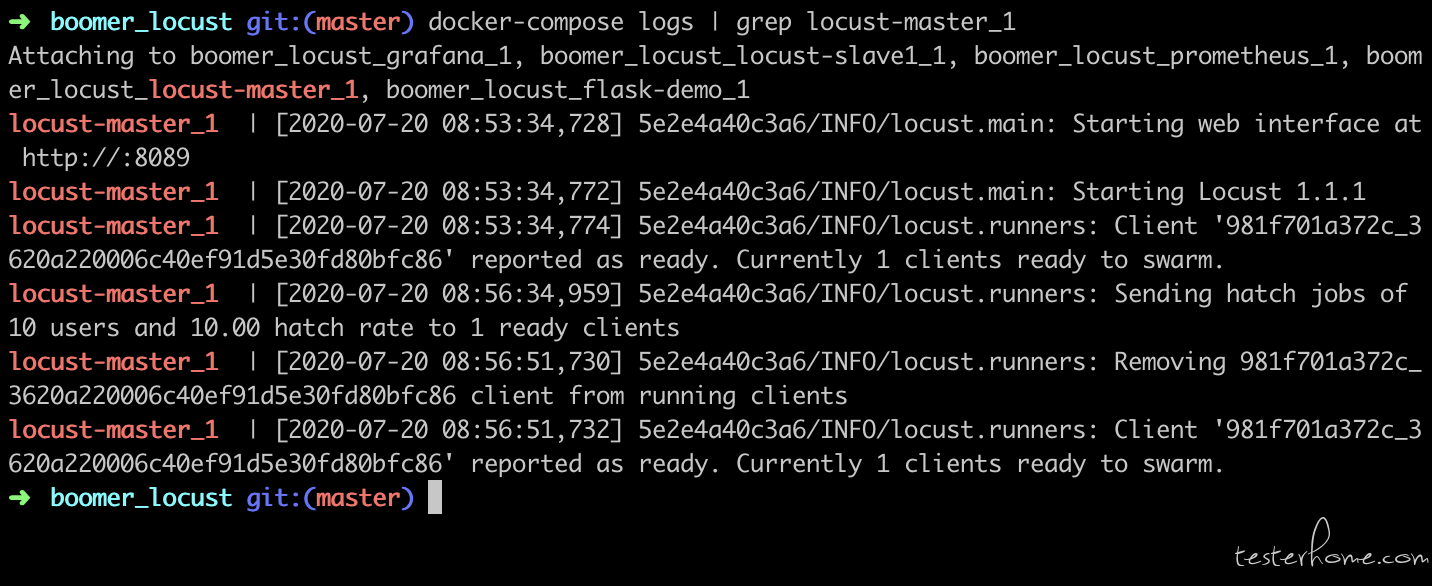
locust-master 启动以后开始监听有没有 slave 连上。
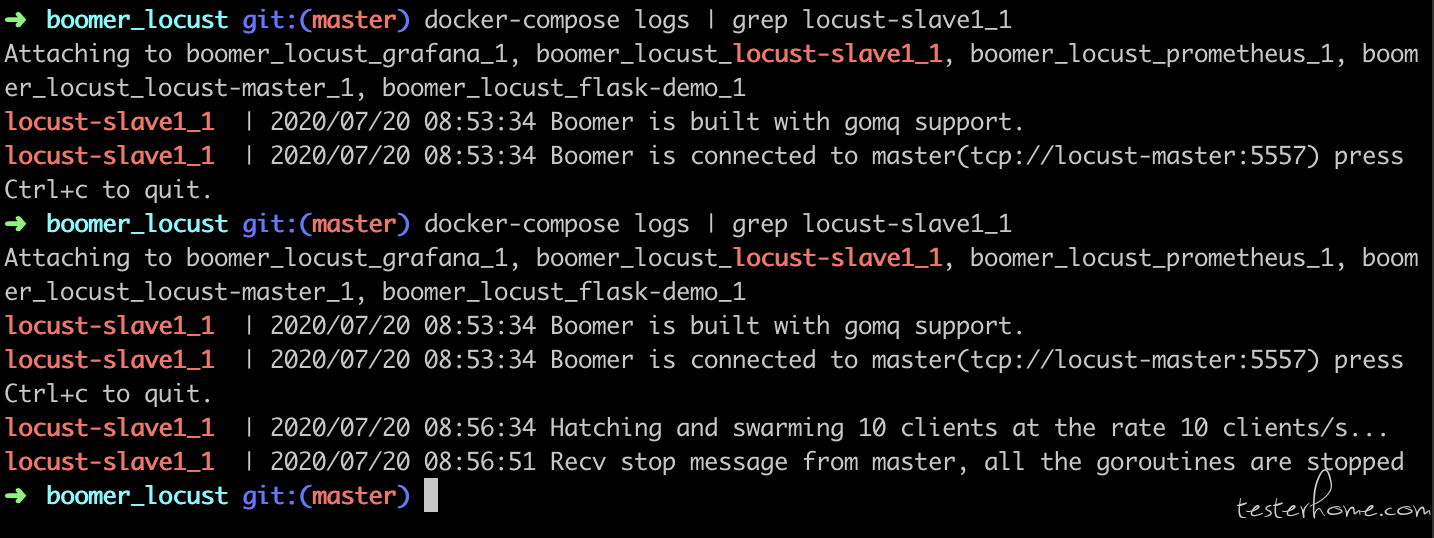
locust-slave 启动以后开始根据指定的 master-host 进行连接。
此时 locust-master & locust-slave 已经建立了通信。
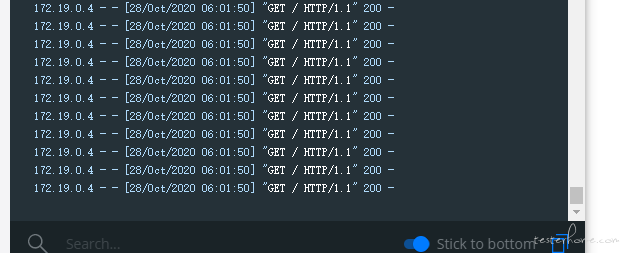
现在我们来对内部网络的 http://flask-demo:5000/ & http://flask-demo:5000/text 这个两个路由进行 1:3 比重的压测访问。这里的 host 不再是传统的 URL,而是一个容器服务的名字。
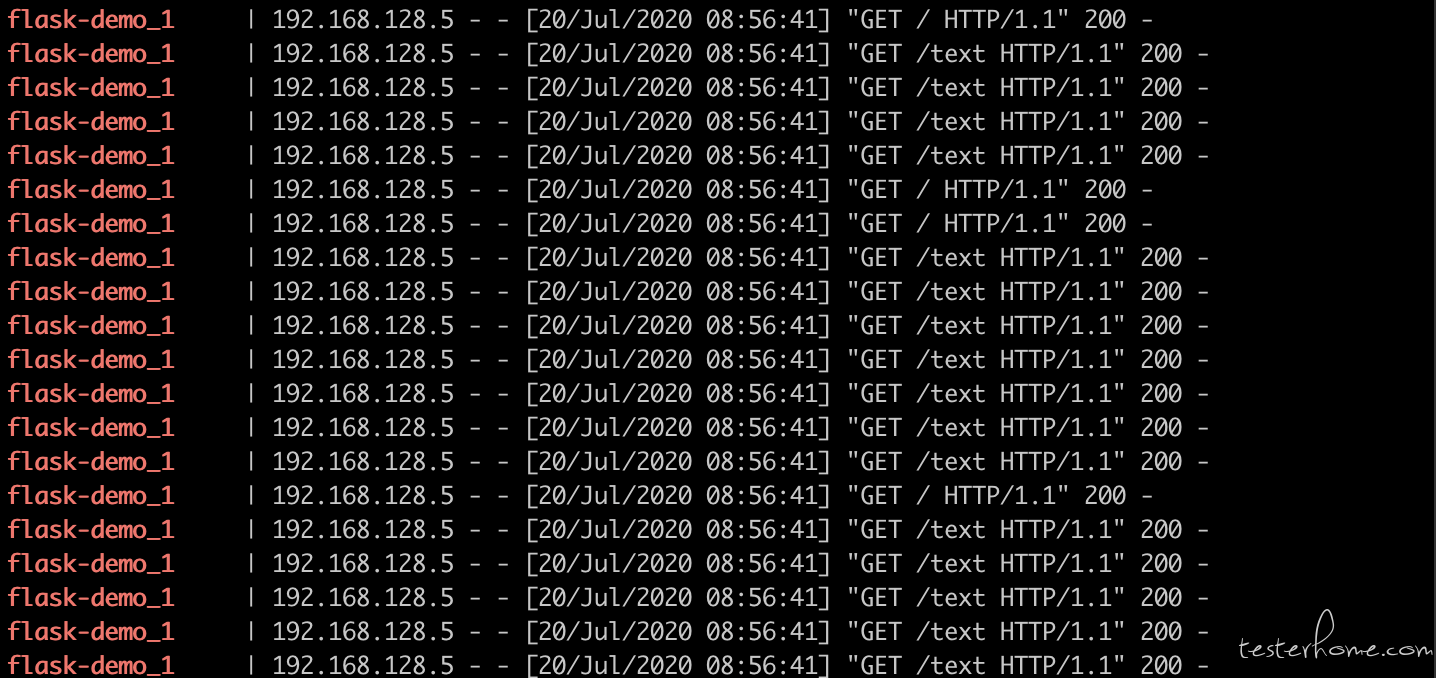
此时查看 flask-demo 的容器日志,发现压力已经正常产生。
此时原生 locust 图表展示如下:

两个路由的比重满足 1:3 的条件。
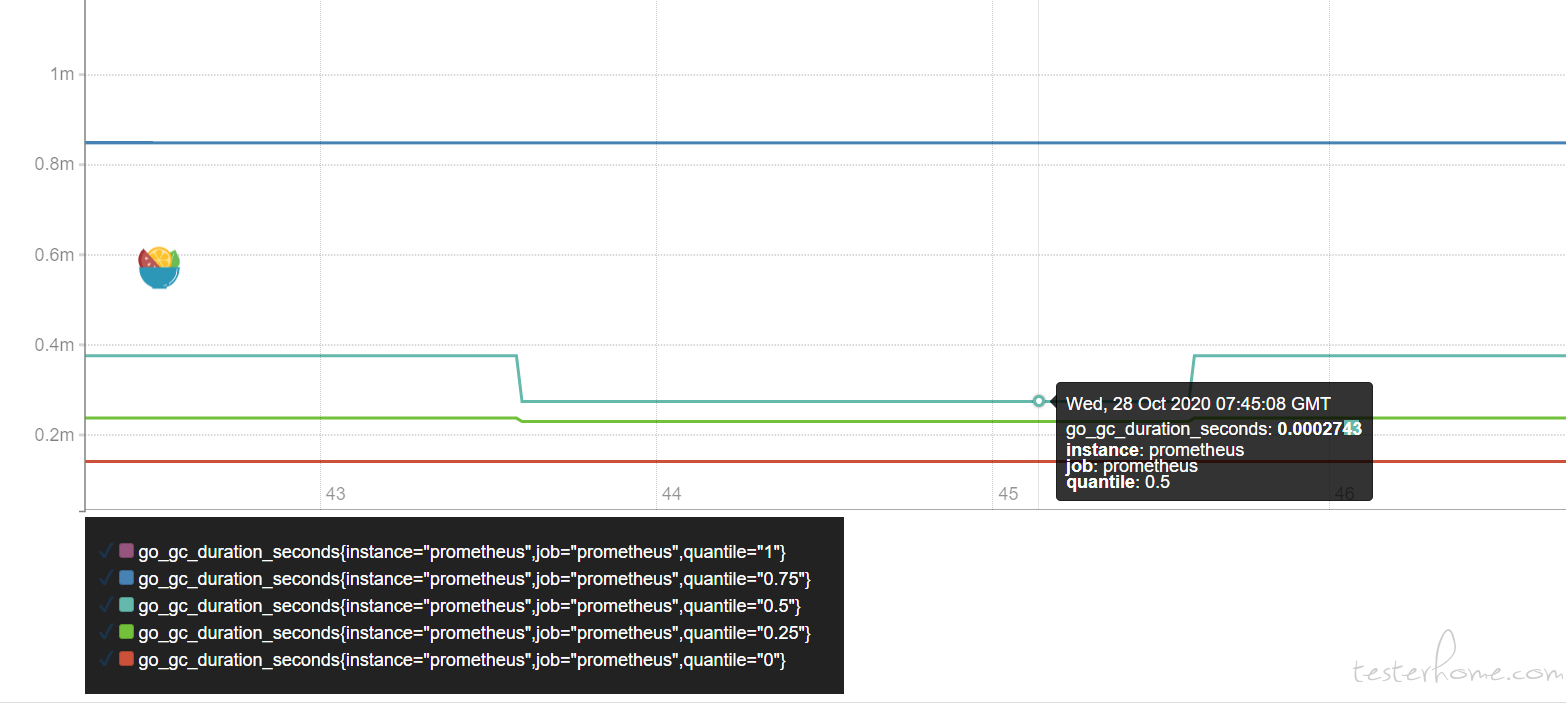
此时 grafana & promethues 的扩展图表展示如下:
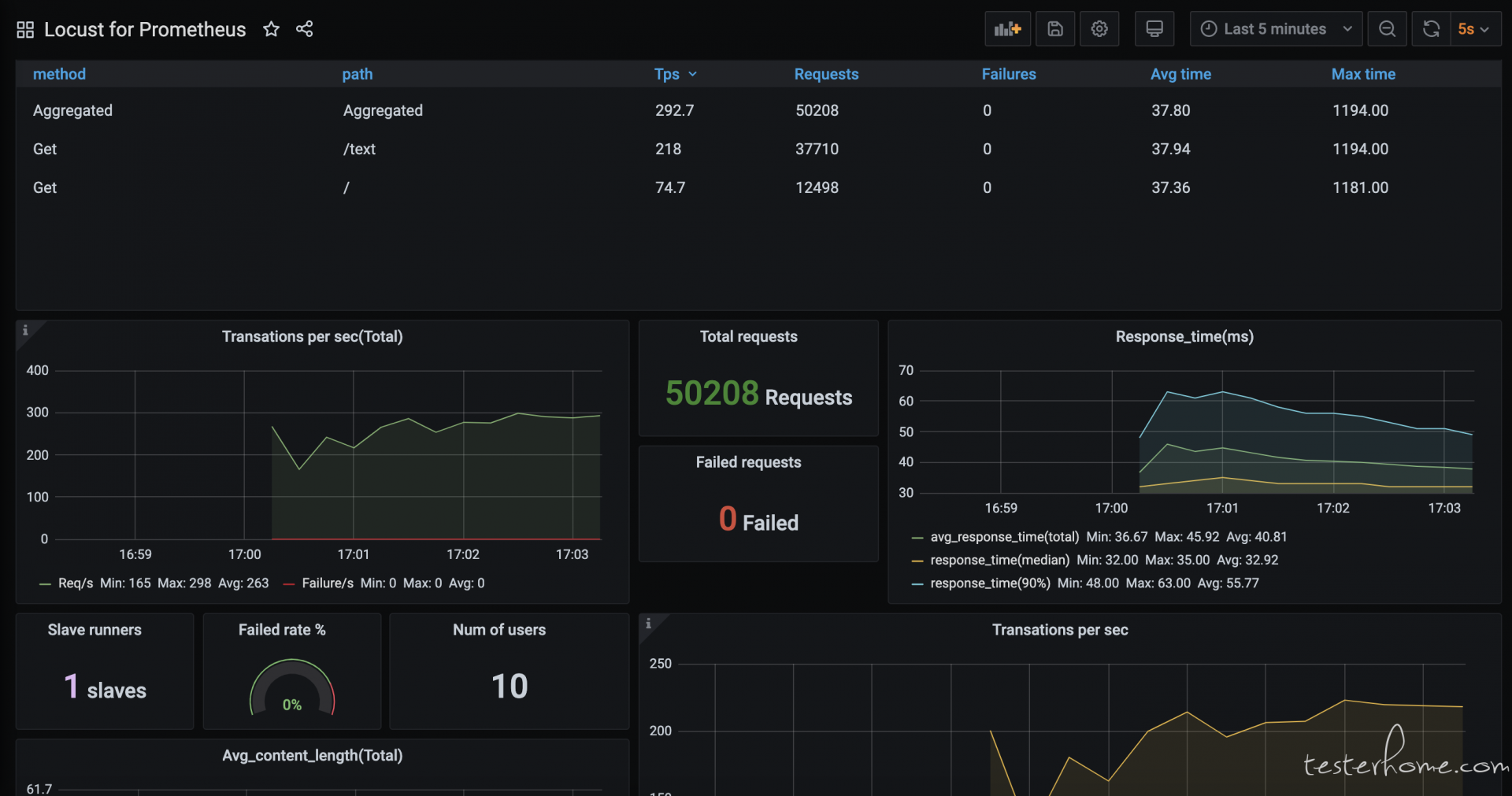
此时,各组件间通信建立成功,集群内部压力产生成功,压力图表扩展成功。
PS:技术交流 QQ 群 552643038
 ,Templating
,Templating