前言
boomer 可使用 go 脚本定制开发 slave 的特点,使得 boomer 不再局限于做 http/https 的压测,对于 tcp/udp/gRPC 等协议的压测,也有着很大的扩展性。本次主要是对 gRPC 压测方案设计及探索测评。
什么是 gRPC
优点
简单来说,gRPC 使用 HTTP2.0 通信,并使用 protobuf 来定义接口和数据类型。
gRPC 主要应用场景:
需要对接口进行严格约束的情况,比如我们提供了一个公共的服务,很多人,甚至公司外部的人也可以访问这个服务,这时对于接口我们希望有更加严格的约束,我们不希望客户端给我们传递任意的数据,尤其是考虑到安全性的因素,我们通常需要对接口进行更加严格的约束。这时 gRPC 就可以通过 protobuf 来提供严格的接口约束。
对于性能有更高的要求时。有时我们的服务需要传递大量的数据,而又希望不影响我们的性能,这个时候也可以考虑 gRPC 服务,因为通过 protobuf 我们可以将数据压缩编码转化为二进制格式,通常传递的数据量要小得多,而且通过 http2 我们可以实现异步的请求,从而大大提高了通信效率。
缺点
暂不支持分布式,负载均衡等等。
一个 gRPC 服务,就算开多个 pod,流量也只会集中在一个 pod 里面。
因为 http2 具备更低的延迟的特点,其实是通过利用单个长期存在的 TCP 连接并在其上多路复用请求 / 响应。这会给第 4 层(L4)负载均衡器带来问题,因为它们的级别太低,无法根据接收到的流量类型做出路由决策。这样,尝试对 http2 流量进行负载平衡的 L4 负载平衡器将打开一个 TCP 连接,并将所有连续的流量路由到该相同的长期连接,从而实际上取消了负载平衡。而 k8s 的 kube-proxy 本质上是一个 L4 负载平衡器,因此我们不能依靠它来平衡微服务之间的 gRPC 调用。
不过不要慌,问题不大。因为 service mesh(istio)天生就支持 gRPC 负载均衡。这个暂不在本话题讨论范围内,后续大家感兴趣我可以写一下。
boomer 基于 gRPC 压测设计
问题: gRPC client 有没有必要用连接池?
gRPC 的 http2 组件是自己实现的,没有采用 golang 标准库里的 net/http。那要不要给 gRPC 加连接池呢?
不着急盲目加池,先测一下。
先写个非池连接的 boomer slave。
package main
import (
"flag"
pb "google.golang.org/grpc/examples/helloworld/helloworld"
"log"
"time"
"github.com/myzhan/boomer"
"golang.org/x/net/context"
"google.golang.org/grpc"
)
var verbose bool
var targetUrl string
var conn *grpc.ClientConn
const defaultName = "world"
func NewConn() *grpc.ClientConn {
conn, err := grpc.Dial(targetUrl, grpc.WithInsecure())
if err != nil {
log.Fatalf("did not connect: %v", err)
}
return conn
}
func worker() {
startTime := time.Now()
c := pb.NewGreeterClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
name := defaultName
r, err := c.SayHello(ctx, &pb.HelloRequest{Name: name})
elapsed := time.Since(startTime)
if err != nil {
if verbose {
log.Fatalf("could not greet: %v", err)
}
boomer.RecordFailure("grpc", "helloworld.proto", 0.0, err.Error())
} else {
log.Printf("Greeting: %s", r.GetMessage())
boomer.RecordSuccess("grpc", "helloworld.proto",
elapsed.Nanoseconds()/int64(time.Millisecond), 10)
}
}
func main() {
defer func() {
_ = conn.Close()
}()
flag.StringVar(&targetUrl, "url", "", "URL")
flag.Parse()
if targetUrl == "" {
log.Println("Boomer target url is null")
return
}
log.Println("Boomer target url is", string(targetUrl))
conn = NewConn()
task := &boomer.Task{
Name: "worker",
Weight: 10,
Fn: worker,
}
boomer.Run(task)
}
打包好以后,正常容器调度测试,配置 500 压力线程数并发。
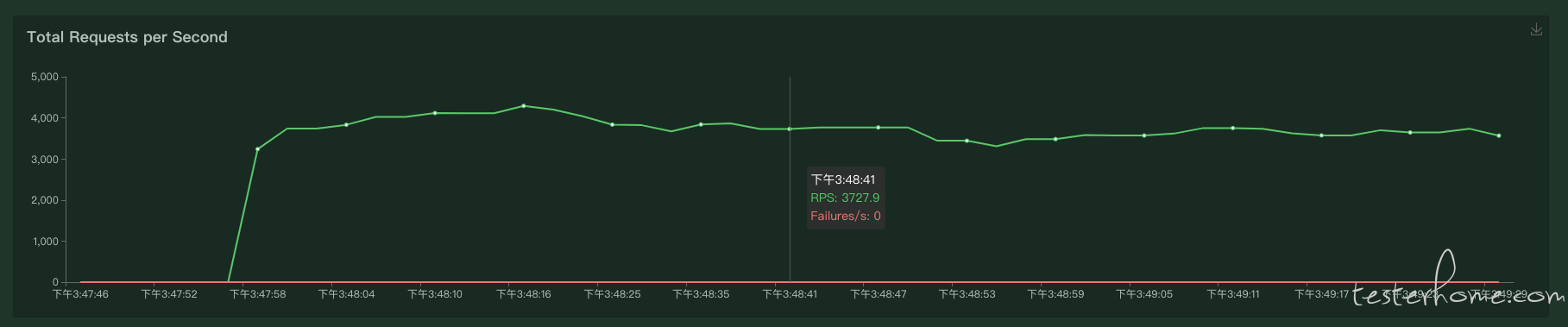

rps 能发出 3700+/s 的效果。
现在试一下加池设置,使用 pool 作为连接池。
//创建一个连接池: 初始化5,最大空闲连接是20,最大并发连接30
poolConfig := &pool.Config{
InitialCap: 100,//资源池初始连接数
MaxIdle: 400,//最大空闲连接数
MaxCap: 500,//最大并发连接数
Factory: factory,
Close: close,
//Ping: ping,
//连接最大空闲时间,超过该时间的连接 将会关闭,可避免空闲时连接EOF,自动失效的问题
IdleTimeout: 15 * time.Second,
}
p, err := pool.NewChannelPool(poolConfig)
if err != nil {
fmt.Println("err=", err)
}
//从连接池中取得一个连接
v, err := p.Get()
//将连接放回连接池中
p.Put(v)
//释放连接池中的所有连接
p.Release()
池有了,再改下 invoke 的方式,采用 bugVanisher/grequester 发起请求。
// getRealMethodName
func (r *Requester) getRealMethodName() string {
return fmt.Sprintf("/%s/%s", r.service, r.method)
}
// Call 发起请求
func (r *Requester) Call(req interface{}, resp interface{}) error {
ctx, cancel := context.WithTimeout(context.Background(), time.Duration(r.timeoutMs)*time.Millisecond)
defer cancel()
cc, err := r.pool.Get()
if err != nil {
log.Printf("get rpc ClientConn error")
return err
}
// 必须要把连接放回连接池否则一直创建新连接
defer r.pool.Put(cc)
if err = cc.(*grpc.ClientConn).Invoke(ctx, r.getRealMethodName(), req, resp, grpc.ForceCodec(&ProtoCodec{})); err != nil {
fmt.Fprintf(os.Stderr, err.Error())
return err
}
return nil
}
打包好以后,正常容器调度测试,配置 500 压力线程数并发。
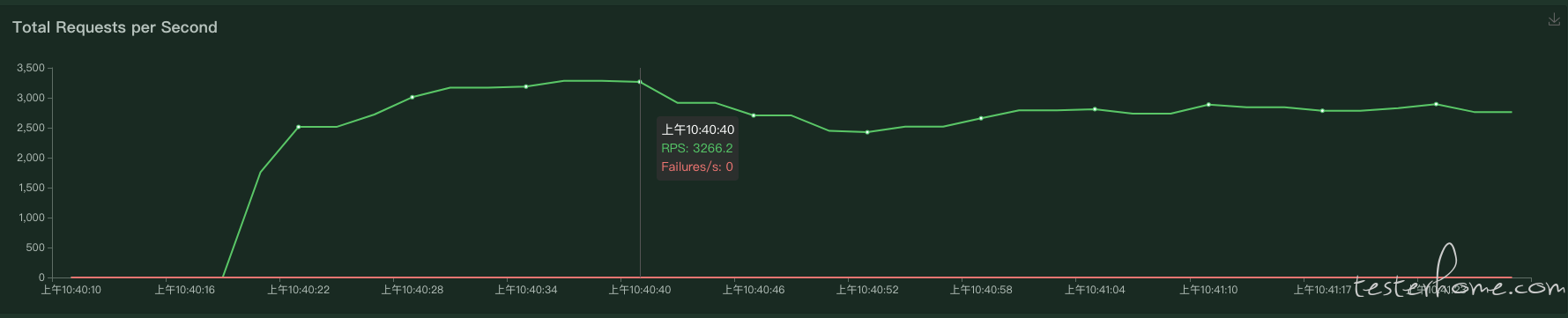

rps 能发出 2900+ 的效果。
说实话问题有点大,理想当中加池应该会有更高的性能,为什么发出的 rps 反而减低了呢?
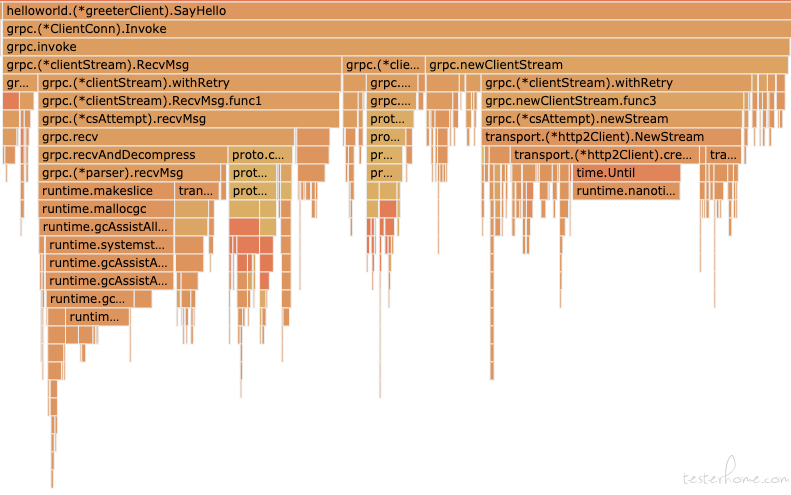
先来对比一下火焰图。
nonpool:
pool:
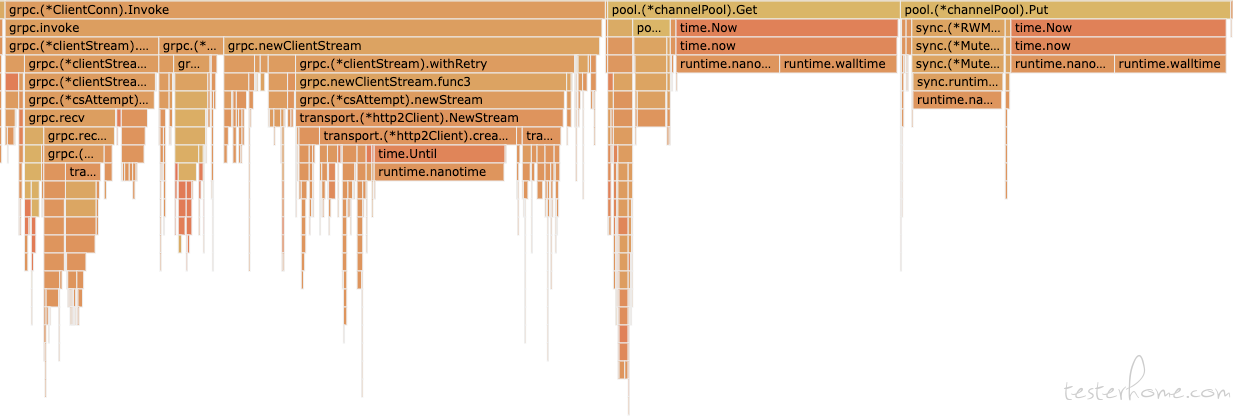
可以看到,加了 pool,其实就是把原有的 helloworld.(*greeterClient).SayHello 拆开成 grpc.(*ClientConn).Invoke,pool.(*channelPool).Get,以及 pool.(*channelPool).Put。
加 pool 的初衷是为了减少 grpc.invoke 里面的 grpc.newClientStream 的耗时,因为创建一个新的连接,理论上是比复用分配池里的一个链接要久的。因为 grpc.newClientStream 里面有个 grpc.(*clientStream).withRetry,看下代码。
func (cs *clientStream) withRetry(op func(a *csAttempt) error, onSuccess func()) error {
cs.mu.Lock()
for {
if cs.committed {
cs.mu.Unlock()
return op(cs.attempt)
}
a := cs.attempt
cs.mu.Unlock()
err := op(a)
cs.mu.Lock()
if a != cs.attempt {
// We started another attempt already.
continue
}
if err == io.EOF {
<-a.s.Done()
}
if err == nil || (err == io.EOF && a.s.Status().Code() == codes.OK) {
onSuccess()
cs.mu.Unlock()
return err
}
if err := cs.retryLocked(err); err != nil {
cs.mu.Unlock()
return err
}
}
}
可以看到这里加了锁,而且粒度还不小。所以加 pool 主要是为了节省 grpc.newClientStream 的时间。
再查看一下时间。
nonpool:

pool:

这里看确实优化到了,但,pool 里面还有 pool.Get 和 pool.Put 操作。

由此可见,加池主要是提高一个服务系统的吞吐量,让它在系统可容纳连接的范围内,使用池减少产生连接的时间,更快给出响应。但是对于一个并发工具来说,能不能更快响应不重要,请求能发出去就行,要的就是产生压力,所以它也不需要回池的操作,它只需要一股脑创建大量 goroutine 来发起连接请求产生压力即可,所以 pool.Put 在一系列高并发操作里面,有点浪费时间,产生的压力,也比没有池的要低。
所以这样一看,还是不能盲目加池。除非 pool.Get 和 pool.Put 加起来的收益比 grpc.newClientStream 高的多,比如一些复杂业务复杂数据之类的,这里就是简单的 helloworld,体现不出来效果。
方案
grpc-demo:
image: shaonian/grpc-demo:latest
locust-master:
image: shaonian/locust-master:latest
ports:
- "8089:8089"
locust-slave1:
image: shaonian/locust-slave-rpc:nonpool
command:
- ./main
- --master-host=locust-master
- --master-port=5557
- --url=grpc-demo:50051
- --cpu-profile=cpu.pprof
- --cpu-profile-duration=60s
links:
- locust-master
- grpc-demo
这里内嵌了 pprof ,刚刚上面的数据也是从这里产生的,然后直接从容器复制出来就可以查看分析了,不用专门改代码内置来看具体耗时了。
net/http 与 gRPC 性能测评
都说 gRPC 好,快,那比普通的 http 要快多少呢?
同样都是 hello world。
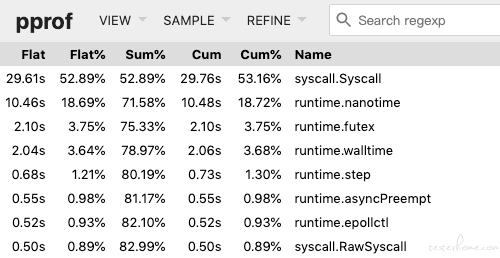
net/http:
grpc:
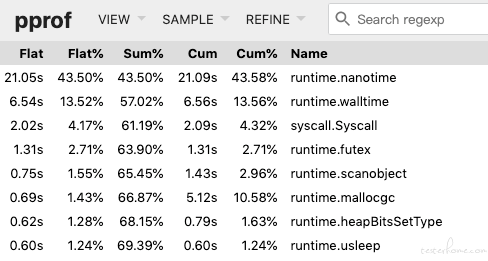
可以看到,http 大部分时间都用来系统调度了,都浪费在 tcp 握手里面了。
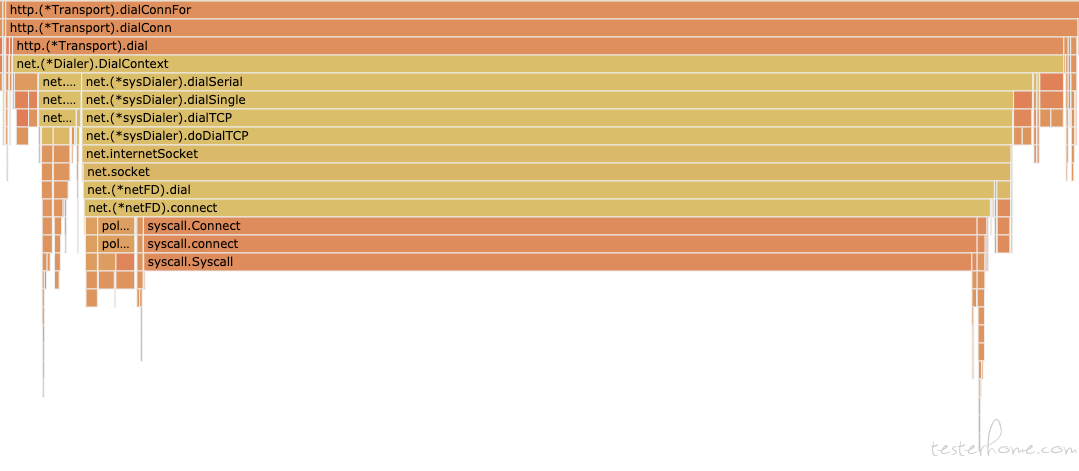
总结
至此,boomer 基于 gRPC 的压测改造已实现,以上即为 demo 以及各种框架性能测评。

项目在这里: shaonian/boomer_locust
快来 star 吧~
相关话题: docker && k8s 分布式压测 locust_boomer 方案
PS:技术交流 QQ 群 552643038