-
今天京东 APP 地址信息被修改且差点被电信诈骗 at 2021年06月17日
暂时没有渠道查询,京东电话客服反馈 后台未看到其他登录信息,就不太好深入跟踪了
-
今天京东 APP 地址信息被修改且差点被电信诈骗 at 2021年06月17日
我主要怀疑我的 iphone 被黑了,因为我手机改完登录密码立马就会泄漏,后来卸载 APP,网页端修改密码后,才没有泄漏
-
今天京东 APP 地址信息被修改且差点被电信诈骗 at 2021年06月17日
这种逻辑漏洞应该不会的,因为一般首先会校验 id 和 token 匹配度,然后再关联 id 和用户数据,如果 id 和 token 不是一个人,应该第一层登录校验就过不去
-
今天京东 APP 地址信息被修改且差点被电信诈骗 at 2021年06月17日
你这个比我的风险还要高啊,挺危险的
-
今天京东 APP 地址信息被修改且差点被电信诈骗 at 2021年06月17日
有经验的小伙伴可以帮忙分析分析
-
Gatling:使用 Maven 创建 Gatling 性能测试项目 at 2021年06月15日
如何有不同于官方文档的见解或实践,就更棒了
-
服务端接口测试指南 at 2021年06月11日
谢谢支持
-
metabase 数据分析利器 at 2021年06月09日
好文
-
666
-
小程序的弱网测试,丢包率各位大佬都是怎么做的? at 2021年06月02日
可以看看腾讯的 弱网测试工具:QNET,介绍见:QNET 弱网测试工具
-
老板都不写文章了,哈哈
-
很荣幸,我有 4 篇,哈哈
-
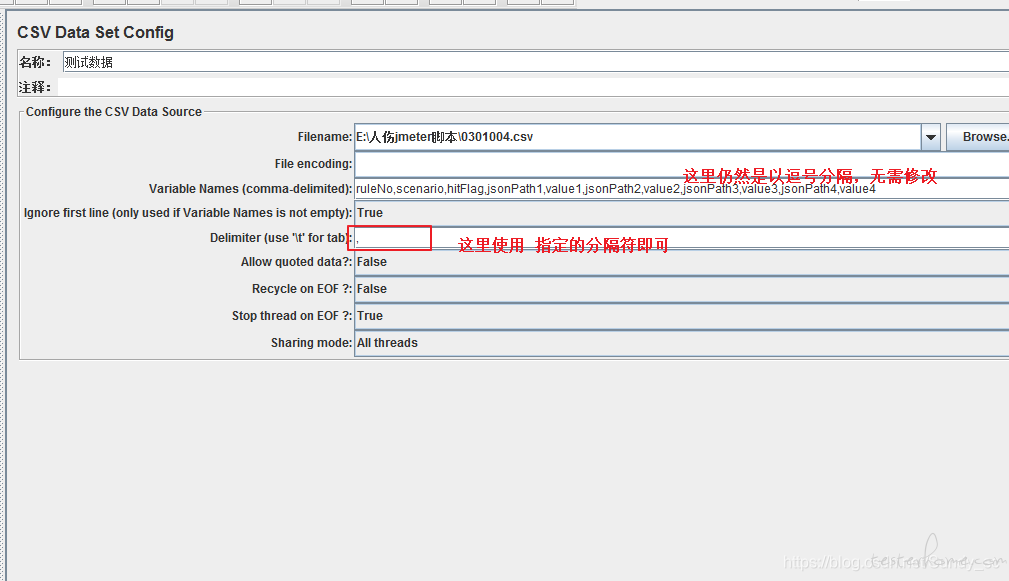
jmeter 能够从 csv 数据的一列数据中读出不同的值吗? at 2021年06月01日
首先,题主的组成数组的写法是非常低效和代码冗余的。

推荐写法:
(1)并发压力小的话,实时创建数据:用 Beanshell 实现不重复的随机数组
参考:Java 生成不重复的随机数组的方法

(2)并发压力大的话,提前生成数据:每列为 2000 个整数的数组,然后自定义非英文逗号分隔符
参考:JMeter - CSV Data 数据中带有逗号解决方法
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月31日
应该不是防火墙的问题吧,因为我命令验证 kafka 没问题
-
AutoMeter-功能,性能一体化 API 自动化测试平台 at 2021年05月30日
赞赞
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月29日
感谢感谢,你又帮一个大忙😊
-
测试瓶颈很低,大家有同感吗? at 2021年05月28日
说实话,我做测试 5、6 年了,目前在公司内部是专家级别,但是确实觉得自己才刚开始入门。做好太难了😂。
真心不觉得测试瓶颈低,而是自我要求低,且做出来的成果低
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月28日
实体机源码安装的吗?可以分享一下安装文档吗?我这边卡住了
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月27日
有验证性能测试的功能吗?
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月27日
那说明我的打开方式不太对哈哈
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月27日
哦哦,我 docker 安装有问题,现在用源码安装了,正在解决问题中😭
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月27日
docker 安装的吗?还是源码安装的?
-
版主招募~ at 2021年05月26日
😊,谢谢
-
在一个网络环境不是很良好的环境测试时怎么保证网络环境基本一致 at 2021年05月26日
1、网络环境不是很良好?指的是外网环境吧
2、保证网络环境基本一致?建议使用局域网通信,网路环境会比较稳定 -
版主招募~ at 2021年05月26日