版主
公众号:onthewaycool
-
版主招募~ at 2021年05月26日
-
版主招募~ at 2021年05月26日
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月26日
在这个群

-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月26日
整好了分享一下
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月26日
多谢多谢,方便加我微信吗?TTMMD155
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月26日
有没有试试 ms-node-controller 单独搭建,可以吗?
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月26日
对,Kafka 的服务、topic 都验证了没问题
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月26日
我用的也是 1.9.3 的,那我再看看,还不行的话,找您帮我看看?
-
【docker 安装成功了】有成功搭建 meterSphere 接口平台的同学吗? at 2021年05月26日
继续帮忙,有玩过的小伙伴吗?
-
接口测试工具: 基于 mitmproxy 实现接口录制,减少写用例的成本 at 2021年05月24日
看到这个,我也点了一下,尴尬。。。。
-
WMS 怎么接口自动化 at 2021年05月20日
-
UI 自动化编写规范 (基于 Airtest) at 2021年05月18日
不客气
-
服务端接口测试指南 at 2021年05月17日
写操作,一定不能直接操作表。
- 写操作:建议调用开放接口
- 读操作:可以直接查询数据库
-
服务端接口测试指南 at 2021年05月14日
不好意思,因为内容有误,已修复
-
服务端接口测试指南 at 2021年05月12日
过奖啦
-
想往性能测试深入,应该怎么学,求大佬告知 at 2021年05月12日
-
服务端接口测试指南 at 2021年05月12日

-
关于肯德基的新闻,这类 bug 该如何在测试中及时发现~~ at 2021年05月11日
这个 BUG 主要还是业务逻辑漏洞,需要深入理解业务,就可以测试出来吧
-
服务端接口测试指南 at 2021年05月10日
感谢关注
-
服务端接口测试指南 at 2021年05月09日
客气啦
-
服务端接口测试指南 at 2021年05月09日
这个回帖打💯分
-
发现一个问题,就是测试平台的二次开发的实战教程资源比较匮乏 at 2021年04月29日
你是问 debugtalk 的博客吗?
-
发现一个问题,就是测试平台的二次开发的实战教程资源比较匮乏 at 2021年04月23日
看看 debugTalk 的 httprunner 实战开发文章啊,写的非常好。
当然,如果是手把手的实战教程,说实话,给钱人家也不愿意写,容易挨骂。
-
在安卓系统上如何测试帧率?有哪些方法? at 2021年04月21日
这个说法非常错误

建议看看渲染原理:详细内容见:Android 流畅度评估及卡顿定位、优化
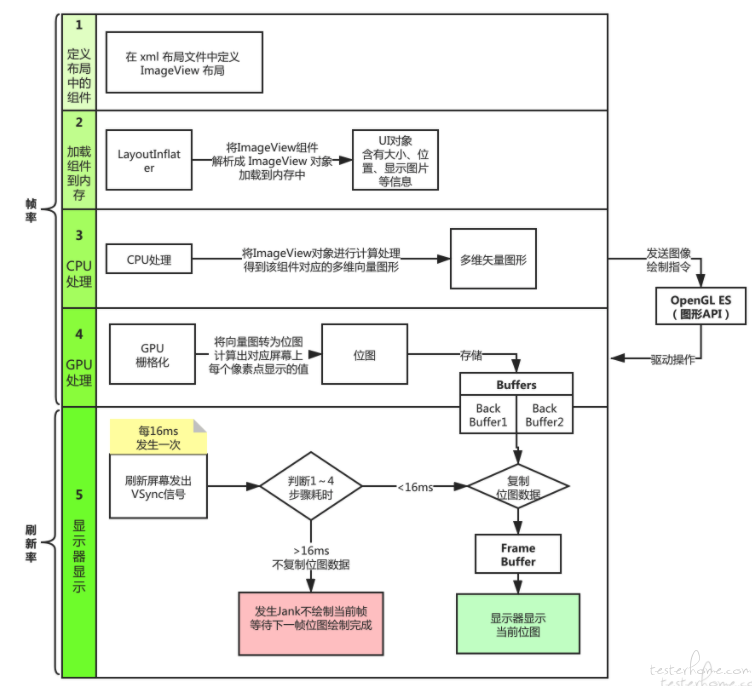
从图中可以看出,按照刷新率 60FPS 的屏幕举例,当某帧渲染超过 16.66ms 时,屏幕是不会立马绘制当前帧的,会等待下一帧绘制完成,才会显示当前帧。这样这一秒,最高就只有 59FPS 了。
其次,在描述流畅度或帧率相关问题时,用帧。用图会让不懂的人更加误解。
-
测试发展了这么多年了,为什么没有一个通用的写测试用例的工具呢? at 2021年04月21日
再通用,也不会像母语一样,大家都用同一套东西