AppCrawler AppCrawler 使用中遇到问题的问题及解决
由于项目的需求,我们自己开发的一款类似于 pad 设备需要测试其他第三方应用的兼容问题,所以尝试用了 appCrawler 进行测试,以下就说下遇到的一些问题以及解决方法
uiautomator server 启动后有概率出现 crash 的情况
具体日志 大致如下
INSTRUMENTATION_RESULT: shortMsg=Process crashed.
[debug] [Instrumentation] INSTRUMENTATION_CODE: 0
[debug] [Instrumentation] The process has exited with code 0
[HTTP] --> GET /wd/hub/session/6622d73d-d8
上网查了一波,有挺多人遇到的,但是都没有给出相应的解决方法,更多遇到问题的同学都是在 vivo 手机上出现,说是因为 vivo 手机的省电模式导致的,但是我们的设备是一台学习机,并不是手机照理不会出现这个省电的问题。不过这个也给了一些思路,去看下 android 的 logcat 日志,应该会有说明它到底是被谁 kill 掉的
通过 adb logcat 以后 发现了这样子的信息


通过定位以后发现是被我们自己定制的一个服务干掉的,了解了具体需求以后才知道是因为特定的需求会杀掉一些后台的服务导致的。
app 遍历过程中会有概率返回到桌面
在遍历过程中出现 app 返回到了桌面 launcher, 并且开始遍历 launcher 的情况,同时还会直接跑到网络的界面,将网络的开关给直接关闭了,这个给遍历测试造成了很大的困扰。
想要知道为什么还是得了解下具体的逻辑实现,其实我们仔细看代码会发现,作者其实是有考虑这块的内容的。具体见:
def needBackApp(): Boolean = {
log.trace(conf.appWhiteList)
log.trace(appNameRecord.last(10))
//跳到了其他app. 排除点一次就没有的弹框
if (conf.appWhiteList.forall(appNameRecord.last().toString.matches(_)==false)) {
log.warn(s"not in app white list ${conf.appWhiteList}")
log.warn(s"jump to other app appName=${appNameRecord.last()} lastAppName=${appNameRecord.pre()}")
setElementAction("backApp")
return true
} else {
return false
}
}
这里可以看到判断最后记录的应用的名称是否是在白名单中,如果不在则调用 elementAction("backApp")
看上去应该是没问题的才对,那问题就是 appNamerecord 的数据是否正确的, 所以我们需要去看下 appNameRecord 的数据是什么时候赋值的。
def parsePageContext(): Unit = {
appName = driver.getAppName()
log.info(s"appName = ${appName}")
appNameRecord.append(appName)
currentUrl = getUri()
log.info(s"url=${currentUrl}")
def refreshPage(): Boolean = {
log.info("refresh page")
driver.getPageSourceWithRetry()
log.trace(driver.currentPageSource)
if (driver.currentPageSource!=null) {
parsePageContext()
return true
} else {
log.warn("page source get fail, go back")
setElementAction("back")
return false
}
//appium解析pageSource有bug. 有些页面会始终无法dump. 改成解析不了就后退
}
从上面的信息我们可以看到当刷新页面的时候,其实 appNamerRecord 就会被进行赋值,那我们看下 getAppName 这个是如何获取的。
override def getAppName(): String = {
driver match {
case android: AndroidDriver[_] => {
val xpath="(//*[@package!=''])[1]"
getNodeListByKey(xpath).headOption.getOrElse(Map("package"->"")).get("package").getOrElse("").toString
}
case ios: IOSDriver[_] => {
val xpath="//*[contains(name(), 'Application')]"
getNodeListByKey(xpath).head.getOrElse("name", "").toString
}
}
}
看上面的逻辑 应该是没问题了才对,因为直接是解析 xpath 的内容,同时获取到 package 的内容不为空的节点,通过节点信息解析到对应的包名
我们看到第一个方法里面其实日志是有打印出应用的名称的,我们翻看下日志。

得到这样子的信息,appName 获取到的是空的。
PS: 为什么是空其实还没有分析出来,因为后面尝试重新复现又没有复现出来, 但是这个问题不单单是在我个人的设备上出现过。
所以我们这里改了另外一种方式,不通过解析 xml 了。通过 driver 的 api.
override def getPackageName(): String = {
driver match {
case android: AndroidDriver[_] => {
driver.asInstanceOf[AndroidDriver[WebElement]].getCurrentPackage
}
case ios: IOSDriver[_] => {
""
}
}
}
获取到应用的包名。 另外我们把判断的逻辑也进行相应的修改
//跳到了其他app. 排除点一次就没有的弹框
if (!conf.appWhiteList.exists(_.contains(driver.getPackageName()))) {
log.warn(s"not in app white list ${conf.appWhiteList}")
log.warn(s"jump to other app appName=${appNameRecord.last()} lastAppName=${appNameRecord.pre()}")
setElementAction("backApp")
return true
} else {
return false
}
app 遍历过程中有跳转到别的应用后直接就重启 app
首先我们先要理清楚什么时候会出现这个现象,我们上一个问题说过,如果出现当前的包名不是我们所测试的 app 的包名的时候,就会设置 ElementAction 为backApp, 但是这个操作其实是很重的,我们并不是很希望这种现象经常发生,不如说以下的场景

图片只是为了帮助理解问题,不是真正存在问题。 我们有的时候应用中会需要去分享一个内容,这个时候 android 可能会调起 当前可用的分享的 app.这个时候置顶的包名就不是我们所测试的包了。而程序的逻辑就比较难受了,直接会将 app 重新调起,这个时候我们重新启动的 app 的界面就不是我们遍历到的页面,往往都是程序的首页了。所以就因为这种情况,可能就会遗漏很多场景没有遍历到。
那如何修改呢,其实也比较简单些。这种场景往往可以通过 back 方式来解决,没有必要一定要通过 launchapp 来先处理,所以我们再 launchapp 之前先通过点击 back 按钮来尝试,如果可以解决就 ok 了。如果不行再换成 lauchapp 进行操作。
所以代码就这么改动就可以了
case "backApp" => {
log.info("try click back for backApp")
driver.back()
Thread.sleep(conf.waitLoading)
driver.getPageSource()
if (needBackApp()) {
log.info("backApp")
driver.launchApp()
Thread.sleep(conf.waitLaunch)
}
}
app 遍历不全的问题
由于我们这次遍历的应用是 100 多款第三方的应用,所以我们需要至少保证做到的是被测试的应用的主 tab 需要被点击到, 结果发下好几款应用的主 tab 都只是点击了第一个,其他 tab 项都没有被点击。
这里我们需要先了解 AppCrawler 是如何进行组装操作的命令的。
override def findElementsByURI(element: URIElement, findBy: String): List[AnyRef] = {
//todo: 优化速度,个别时候定位可能超过10s
//todo: 多种策略,使用findElement 使用xml直接分析location 生成平台特定的定位符
element match {
case id if element.id.nonEmpty && findBy=="id" =>{
log.info(s"findElementsById ${element.id}")
driver.findElementsById(element.id).asScala.toList
}
case name if element.name.nonEmpty && findBy=="accessibilityId" => {
log.info(s"findElementsByAccessibilityId ${element.name}")
driver.findElementsByAccessibilityId(element.name).asScala.toList
}
case android if platformName.toLowerCase=="android" && findBy=="default" => {
val locator=new StringBuilder()
locator.append("new UiSelector()")
locator.append(".className(\"" + element.tag + "\")")
if(element.text.nonEmpty){
locator.append(".text(\"" + element.text + "\")" )
}
if(element.id.nonEmpty){
locator.append(".resourceId(\"" + element.id + "\")")
}
if(element.name.nonEmpty){
locator.append(".description(\"" + element.name + "\")" )
}
if(element.instance.nonEmpty && element.text.isEmpty && element.name.isEmpty && element.id.isEmpty){
//todo: 如果出现动态出现的控件会影响定位
//todo: webview内的元素貌似用instance是不行的,webview内的真实的instance与appium给的不一致
locator.append(".instance(" + element.instance + ")" )
}
log.info(s"findElementByAndroidUIAutomator ${locator.toString()}")
asyncTask(){
List(driver.asInstanceOf[AndroidDriver[WebElement]].findElementByAndroidUIAutomator(locator.toString()))
} match {
case Left(value)=>{
value
}
case Right(value)=>{
log.warn(s"findElementByAndroidUIAutomator error, use findElementsByAndroidUIAutomator ${locator.toString()}")
driver.asInstanceOf[AndroidDriver[WebElement]].findElementsByAndroidUIAutomator(locator.toString()).asScala.toList
}
}
//driver.asInstanceOf[AndroidDriver[WebElement]].findElementsByAndroidUIAutomator(locator.toString()).asScala.toList
//todo: 个别时候findElement会报错而实际上控件存在,跟uiautomator的定位算法有关
//todo: 结合findElement和findElements
//todo: 修复appium bug
//List(driver.asInstanceOf[AndroidDriver[WebElement]].findElementByAndroidUIAutomator(locator.toString()))
}
case _ => {
//todo: 生成iOS原生定位符
//默认使用xpath
log.info(s"findElementsByXPath ${element.xpath}")
//driver.findElementsByXPath(element.xpath).asScala.toList
List(driver.findElementByXPath(element.xpath))
}
}
}
我们看下上述的代码其实我们发现一个问题了, 如果是 android 平台的话,是会组装 UiSelector 的查询语句来快速进行查找元素,但是这里确是有一个问题,即是当出现我们刚才描述的现象,底部的 tab 按钮都是一个 id 的情况下,组装出来的查询语句就会变成同一个了。这样子就会导致其他 tab 没有办法被点击到。
所以我们这里的解决方式是修改 yaml 的配置文件,将findby 从 default 修改为 xpath 让逻辑默认能够走到最后一个默认的条件即可。
修改完这些就可以了吗? 结果验证发现还是不行。又重新看了一遍 appcrawler 的逻辑。
我们发现在获取可点击的元素列表时,底部的几个 tab 都被提取出来了,但是到了判断元素是否被点击的时候,实际上提示说已经被点击了
//过滤已经被点击过的元素
all = all.filter(!store.isClicked(_))
log.info(s"all - clicked size=${all.size}")
if(all.size<lastSize) {
all.foreach(log.trace)
lastSize=all.size
}
def isClicked(ele: URIElement): Boolean = {
if (elementStore.contains(ele.toString)) {
if (elementStore(ele.toString).action == ElementStatus.Clicked) {
AppCrawler.log.info(s"element=${ele} has been click")
}
elementStore(ele.toString).action == ElementStatus.Clicked
} else {
AppCrawler.log.trace(s"element=${ele} first show, need click")
false
}
}
是判断 elementStore 中是否包含元素的字符串序列化,并且这个元素的 action 是否为 clicked,所以我们关键要知道ele.toString 的逻辑是怎么样的。
override def toString: String = {
val fileName=new StringBuilder()
fileName.append(url)
fileName.append(s".tag=${tag.replace("android.widget.", "").replace("Activity", "")}")
if(instance.nonEmpty){
fileName.append(s".${instance}")
}
if(depth.nonEmpty){
fileName.append(s".depth=${depth}")
}
if(id.nonEmpty){
fileName.append(s".id=${id.split('/').last}")
}
if(name.nonEmpty){
fileName.append(s".name=${name}")
}
if(text.nonEmpty){
fileName.append(s".text=${ StringEscapeUtils.unescapeHtml4(text).replace(File.separator, "+")}")
}
fileName.toString().take(100)
}
我们可以发现 元素的唯一标识是通过所在的 activity, 组件的类名, 第几个元素, 深度,id。理论上其实是可以唯一区别的,因为就算 id 所有信息都一样 这里还是有一个 instance 做为标识的。不过其实这里的 instance 默认都是空的, 所以这就有问题了,这个我们放到后面再去解释为什么为空,所以这里我们需要去唯一标识出来这个元素的话,就只能增加一个属性字符串了,这里我们直接在代码最后增加一个
if (x != 0) {
fileName.append(s".x=${x}")
}
来解决,不过其实这个不是根本的解决方式,因为这个改动风险还是挺大的,有可能会增加一些本应该本过滤掉的重复元素的点击。所以我们根本需要解决的问题是 instance 为空的情况, 这个我们下来会讲到怎么解决。
前置的用例执行过程中会存在一些异常的弹框,导致登录出现异常
我们发现用例在执行的过程中是不会去触发 trigger 的,所以就可能会导致我们在登录过程中(我们这里的用例都是用来做 app 登录的)一旦应用有新版本的更新导致的系统权限允许弹框或者可能一些新的活动页弹框导致用例执行失败的情况。所以我们希望能够在用例执行过程中也能够进行 trigger 的触发
我们先看下用例执行的逻辑
test("run steps") {
log.info("testcase start")
val conf = crawler.conf
val driver = crawler.driver
val cp = new scalatest.Checkpoints.Checkpoint
conf.testcase.steps.foreach(step => {
log.info(step)
val xpath=step.getXPath()
val action=step.getAction()
log.info(xpath)
log.info(action)
driver.findMapWithRetry(xpath).headOption match {
case Some(v) => {
val ele = new URIElement(v, "Steps")
crawler.doElementAction(ele, action)
}
case None => {
//用于生成steps的用例
val ele = URIElement(url="Steps", tag="", id="", name="NOT_FOUND", xpath=xpath)
crawler.doElementAction(ele, "")
withClue("NOT_FOUND"){
log.info(xpath)
fail(s"ELEMENT_NOT_FOUND xpath=${xpath}")
}
}
}
if(step.then!=null) {
step.then.foreach(existAssert => {
cp {
withClue(s"${existAssert} 不存在\n") {
val result=driver.getNodeListByKey(existAssert)
log.info(s"${existAssert}\n${TData.toJson(result)}")
result.size should be > 0
}
}
})
}
})
cp.reportAll()
log.info("finish run steps")
}
可以看到上面的逻辑就是遍历了配置文件中的用例,通过 xpath 进行查找元素,然后操作,一旦出现元素未找到,用例则执行失败
所以我们需要在用例执行之前去判断当前的元素是否有满足 trigger 的条件,由于作者其实已经实现的 trigger 的逻辑,这里只要调用对应的方法即可,代码如下:
...
log.info(xpath)
log.info(action)
// 多刷新一次页面
var flag = true
while(flag) {
crawler.refreshPage()
log.info(s"complete trigger before fresh page")
crawler.getElementByTriggerActions() match {
case Some(e) => {
log.info(s"found ${e} by ElementActions")
crawler.doElementAction(e, "click")
Thread.sleep(1000)
log.info(s"trigger complete")
}
case None => {
log.info("not found triggerActions")
flag = false
}
}
}
driver.findMapWithRetry(xpath).headOption match {
...
如此逻辑即可,因为有可能 trigger 会连续触发,所以我们需要用一个 while 循环来控制这个事情。
重新认识 instance 为空的问题
在前面的问题中我们讲过为了解决 app 遍历不全的问题,我们再 element 序列化的时候增加了一个 x 坐标的标识,但是这个是非常不好的事情,尤其是 x 坐标。所以我们需要先确认好 instance 这个属性的来历以及分析为什么为空的原因。
我们先看下 instance 是怎么被赋值的:
def getNodeListFromXPath(xpath: String, pageDom: Document): List[Map[String, Any]] = {
val node=getNodeListFromXML(pageDom, xpath)
val nodeMapList = ListBuffer[Map[String, Any]]()
node match {
case nodeList: NodeList => {
0 until nodeList.getLength foreach (i => {
val nodeMap = mutable.Map[String, Any]()
//初始化必须的字段
nodeMap("name") = ""
nodeMap("value") = ""
nodeMap("label") = ""
nodeMap("x")="0"
nodeMap("y")="0"
nodeMap("width")="0"
nodeMap("height")="0"
val node = nodeList.item(i)
//如果node为.可能会异常. 不过目前不会
nodeMap("tag") = node.getNodeName
val attributesList=getAttributesFromNode(node)
//必须在xpath前面
nodeMap("depth") = attributesList.size
//todo: 改进算法
//nodeMap("menu") = isMenuFromBrotherNode(node)
nodeMap("ancestor")=attributesList.map(_.get("tag").get).mkString("/")
nodeMap("xpath") = getXPathFromAttributes(attributesList)
//支持导出单个字段
nodeMap(node.getNodeName) = node.getNodeValue
//获得所有节点属性
val nodeAttributes = node.getAttributes
if (nodeAttributes != null) {
0 until nodeAttributes.getLength foreach (a => {
val attr = nodeAttributes.item(a).asInstanceOf[Attr]
nodeMap(attr.getName) = attr.getValue
})
}
//todo: 支持selendroid
//如果是android 转化为和iOS相同的结构
//name=resource-id label=content-desc value=text
if (nodeMap.contains("resource-id")) {
nodeMap("name") = nodeMap("resource-id").toString
}
if (nodeMap.contains("text")) {
nodeMap("value") = nodeMap("text")
}
if (nodeMap.contains("content-desc")) {
nodeMap("label") = nodeMap("content-desc")
}
//为了加速android定位
if (nodeMap.contains("instance")) {
nodeMap("instance") = nodeMap("instance")
}
//默认true
nodeMap("valid")= nodeMap.getOrElse("visible", "true") == "true" &&
nodeMap.getOrElse("enabled", "true") == "true" &&
nodeMap.getOrElse("valid", "true") == "true"
//android
if(nodeMap.contains("bounds")){
val rect=nodeMap("bounds").toString.split("[^0-9]+").takeRight(4)
nodeMap("x")=rect(0).toInt
nodeMap("y")=rect(1).toInt
nodeMap("width")=rect(2).toInt-rect(0).toInt
nodeMap("height")=rect(3).toInt-rect(1).toInt
}
if (nodeMap("xpath").toString.nonEmpty && nodeMap("value").toString().size<50) {
nodeMapList += (nodeMap.toMap)
}
} )
}
case attr:String => {
//如果是提取xpath的属性值, 就返回一个简单的结构
nodeMapList+=Map("attribute"->attr)
}
}
nodeMapList.toList
}
我们可以看下这个逻辑, 发现实际上 instance 的属性赋值实际上就是从 dump 的 xml 文件中解析出来的,所以我们直接找到一个遍历过程中的 dom 文件发现确实是不存在 instance 这个属性的。
难道是使用的 appium 的版本不对的问题? 但是按理应该不太可能,因为我们使用的 appium 版本已经到了 1.18 的版本了,只是比最新版本落后了一些而已。另外翻开 appcrawler 作者的测试代码发现,在 16 年的时候作者使用测试 xml 已经包含了 instance 了。
突然脑中灵光一现,现在我们一直使用的 android driver 都是 uiautomator2, 有没有可能是因为使用的是 uiautomator1 才会有 instance 呢? 带着这个疑问,我们尝试将 automationName 的值修改为 UiAutomator1。 结果正如所想的出现了 instance。
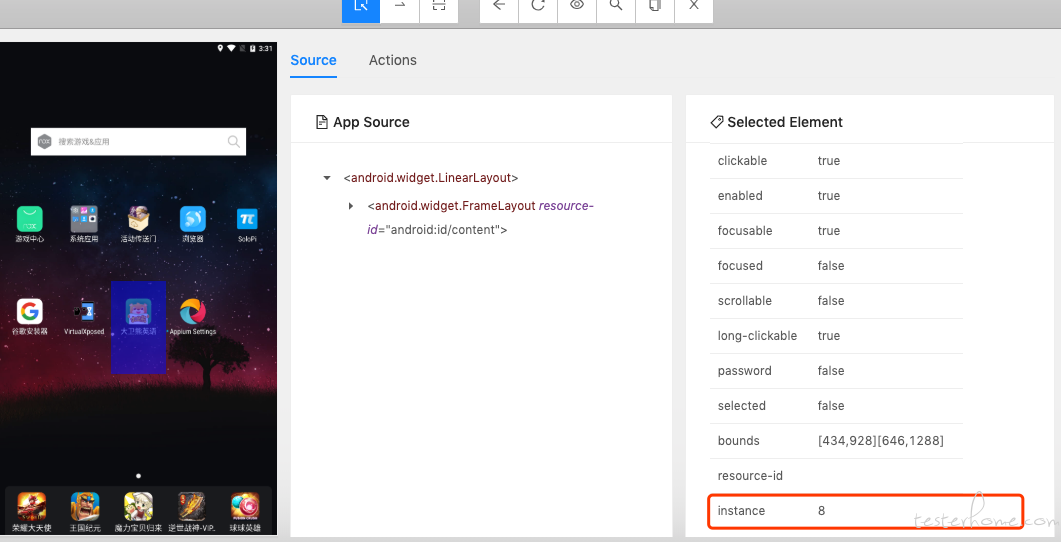
所以这个很大的可能性是因为 appium-uiautomator2-server
没有支持 instance 属性导致的。那是否真的如猜测那样呢,我们需要去看下 appium-uiautomator2-server
的逻辑了。
public enum Attribute {
CHECKABLE(new String[]{"checkable"}),
CHECKED(new String[]{"checked"}),
CLASS(new String[]{"class", "className"}),
CLICKABLE(new String[]{"clickable"}),
CONTENT_DESC(new String[]{"content-desc", "contentDescription"}),
ENABLED(new String[]{"enabled"}),
FOCUSABLE(new String[]{"focusable"}),
FOCUSED(new String[]{"focused"}),
LONG_CLICKABLE(new String[]{"long-clickable", "longClickable"}),
PACKAGE(new String[]{"package"}),
PASSWORD(new String[]{"password"}),
RESOURCE_ID(new String[]{"resource-id", "resourceId"}),
SCROLLABLE(new String[]{"scrollable"}),
SELECTION_START(new String[]{"selection-start"}),
SELECTION_END(new String[]{"selection-end"}),
SELECTED(new String[]{"selected"}),
TEXT(new String[]{"text", "name"}),
// The main difference of this attribute from the preceding one is that
// it does not replace null values with empty strings
ORIGINAL_TEXT(new String[]{"original-text"}, false, false),
BOUNDS(new String[]{"bounds"}),
INDEX(new String[]{"index"}, false, true),
DISPLAYED(new String[]{"displayed"}),
CONTENT_SIZE(new String[]{"contentSize"}, true, false);
private final String[] aliases;
// Defines if the attribute is visible to the user from getAttribute call
private boolean isExposable = true;
// Defines if the attribute is visible to the user in the xml tree/xpath search
private boolean isExposableToXml = true;
...
}
从这里我们基本就知道,其实 appium-uiautomator2-server 是不支持 instance 属性的,看来得自己尝试去修改了。
我们发现这里就是处理 dump 下来的 xml,并解析其中每一个 element 的地方。
private void serializeUiElement(UiElement<?, ?> uiElement, boolean isIndexed) throws IOException {
final String className = uiElement.getClassName();
final String nodeName = toXmlNodeName(className);
serializer.startTag(NAMESPACE, nodeName);
for (Attribute attr : uiElement.attributeKeys()) {
if (!attr.isExposableToXml()) {
continue;
}
Object value = uiElement.get(attr);
if (value == null) {
continue;
}
serializer.attribute(NAMESPACE, attr.getName(), toSafeString(String.valueOf(value), NON_XML_CHAR_REPLACEMENT));
}
if (shouldAddDisplayInfo) {
addDisplayInfo();
// Display info is only added once to the root node
shouldAddDisplayInfo = false;
}
final int uiElementIndex = uiElementsMapping.size();
uiElementsMapping.put(uiElementIndex, uiElement);
if (isIndexed) {
serializer.attribute(NAMESPACE, UI_ELEMENT_INDEX, Integer.toString(uiElementIndex));
}
for (UiElement<?, ?> child : uiElement.getChildren()) {
serializeUiElement(child, isIndexed);
}
serializer.endTag(NAMESPACE, nodeName);
}
所以我么需要在这里增加一些我们自己的逻辑,需要有一个 hashMap 来存储 className 出现的个数,这样子才能够计算出 instance 的值,操作方式类似于上述方法中的 addDisplayInfo
这里就不具体说明修改内容了,详细可以查看 支持 instance 属性
