-
深度学习基础 (二十三)-- 科普:深度学习业务场景与原理概览 (三) at 2018年05月20日
你真把我当算法工程师了
 。
。 -
深度学习基础 (十三)--演讲稿: 机器学习服务的测试探索 at 2018年05月16日
对了,算子的测试一般不是要高并发的~~ 一般不会这么测的。 就是单个算子在环境里跑。 这样能测出这个算子的 baseline
-
深度学习基础 (十三)--演讲稿: 机器学习服务的测试探索 at 2018年05月16日
基本上机器学习的所有测试类型都跟数据有关。 所以做性能测试最关注的是数据的构造。 不同的模型对不同的数据有着不同的性能表现。 最简单例子比如你可以把高维特征 (海量离散特征,比如 1 亿维) 喂给 LR 算法也没什么问题。但是喂给 GBDT 几百维都能慢的像蜗牛一样,几万维特征给 GBDT 能把集群撑爆了。 所以要构建不同数据规模,数据分布,数据类型的数据。 同时算子运行的参数也很重要。 最常见的影响参数是 batch size,learning rate, 训练轮数等。
-
我认为广义的自动化测试就三样,app 自动化测试,web 自动化测试,接口自动化测试 at 2018年05月13日
所以我一直在说这些根咱们讨论的有什么关系么?这个帖子在讨论的,还有我在说的一直都是有很多地方测试很有技术含量。有很多测试类型值得去研究,我列举了很多会用到的技术点。但你选择忽视所有你不想听的。一直反复的说测试 low 测试没技术测试在骗人。如果你不是来讨论的,只是单方面的在诋毁一个职业。 那咱们没必要聊下去了
-
我认为广义的自动化测试就三样,app 自动化测试,web 自动化测试,接口自动化测试 at 2018年05月13日
这个例子跟讨论的主题有什么关系么?跟测试有没有技术含量有关系么?跟自动化测试有什么关系么?
-
我认为广义的自动化测试就三样,app 自动化测试,web 自动化测试,接口自动化测试 at 2018年05月13日
我司成立三年多,只是个 300 多人的小厂子,不是大厂不是独角兽,docker 技术在 QA 团队刚组建,只有 2 人的时候我就在学习使用了,那时候公司只有 30 人。 我提到的这些,只要是这个方向的公司,都会涉及到,跟公司规模没关系。 你指的小公司会用的可能性为 0 是什么概念? 我司是小公司,我司 QA 起码一半很熟悉 docker,另一半多少也会用点。 我认识的其他的公司的, 不管是 bat,还是快手头条美团这个级别的,还是专门做容器的公司比如七牛,灵雀,众人,甚至是像我司这种小厂。会用 docker 的也不少。
会和使用是两码事,那你为什么觉得我们只是会个皮毛呢? 我们 10 个人的小 team 里有 3 个是能自己搭建 k8s 集群并维护并开发应用的?我们虽不敢说精通,但我们起码都是日常跟 k8s 打交道的。
你说自动化和功能测试的工资差不了多少,那给我举几个纯功能到 30k 以上的例子。 你知道我司多少 QA 在 30k 以上么?你知道我上面列举的这些公司中有多少 QA 30k 以上么 (有些公司甚至不可以用月薪来衡量了)? 甚至 40 的我都见过。 你觉得纯功能测试能拿这个数么?
我承认我说的这些都是集中在北上广深的精英群体。但这个群体已经不是个小数目了。 不要总向下看,人往高处走,水往低处流
-
我认为广义的自动化测试就三样,app 自动化测试,web 自动化测试,接口自动化测试 at 2018年05月13日
首先回答一下楼主觉得没技术含量的事
我给楼主提供几个场景。
- 产品微服务架构下使用 k8s 管理。做调度测试的时候,调完接口难道验证个 response 就结束了么?当然要去 k8s 上验证调度是否正确。
- 大数据模块的功能测试,我们存储一个文件到 hdfs 上,难道验证个 response 就结束了么?当然要去 hdfs 上查看一下文件和文件内容,统计和分析数据分布
- ai 平台的测试,平台支持集成 tensorflow。难道直接在 UI 上点默认模板,或者调个接口跑通了就行么? 当然要构建各种 tf 代码,测试 dnn,cnn,rnn,tensorboard,分布式,GPU,模型导出,模型上线。
就不扯设计模式,代码架构这些容易让人觉得是在务虚的东西了,虽然那个很重要。 我们就说实打实的技术。 楼主觉得调个 http 接口很 low 很没技术含量。 那楼主觉得我上面说的 k8s 技术,大数据技术,tensorflow 技术还 low 么? 是,自动化手段就那么几样,也玩不出什么花来,但是自动化手段向来也不是重点。 而是根据你的产品特性,架构特性你能做出什么样的事情来。 这也是为什么做底层测试会比业务测试有技术含量,虽然他们都是在调接口。测试人员不要局限于自动化手段上,而要对我们所处的领域有更深的研究。这建立在你对产品业务和产品架构的专业度上。专业度上去了,没有人觉得你 low,不管你是研发还是产品还是测试。 我们的 PM 设计某些涉及到底层调度的功能的时候会来问问我的意见, 设计 hadoop,机器学习算法相关模块的时候会拉上我评审一下。甚至做 K8S 相关项目的时候产品 leader 指明要我来做 owner。 测试 tensorflow 的时候大家也是第一个想到我。 我们这的资深 QA 每一个都有一手绝活,我们这里没人轻视 QA.
回答一下楼主觉得自动化没用的事
关于质疑自动化质疑技术的言论有很多, 但是你发没发现这几年质疑的声音越来越小了。 其实不是技术没用,只是技术不好,或者不懂得把技术转换生成产力才给人一种好像没什么用的错觉。 但既然有用的不好的,那就有用的好的。 只是可能很多人没去过像样的厂子所以没见过。 这方面我不多说了,免得又撕上逼了。 可以跟楼主举个我自己应用的例子, 我在我们团队使用 k8s 做自动化部署和 CICD 流程,支撑日千级的构建次数和超过 60 套环境的自动化运维, 这种量级的测试环境你让我人肉维护我要招聘多少个人? 就算是大家最看不起的 UI 自动化测试,都是放在 K8S 里分布式执行,40 个浏览器并发都要跑半个小时。 这种量级的测试用例你让我手工执行我要招聘多少个人? 所以我不劝别人怎么怎么样了, 我觉得技术和自动化很有用。
总结
如果觉得现在做的事情没什么技术含量就多出去看看。大厂核心部门,独角兽核心部门的测试还是很有技术含量的。另外学无止境,只有持续不断的学习,才能去做更有技术含量的事情。 我现在越学习,越觉得自己无知。
-
你心目中的测试专家是怎样的? at 2018年05月09日
不撕~ 不撕~ 不撕~ 不撕~
-
深度学习基础 (二十一)-- 科普:深度学习业务场景与原理概览 (一) at 2018年05月07日
有,只要是分类问题,就有阈值。
-
你是不是觉得特腻歪 at 2018年05月06日
我做了快 8 年测试了。现在还真没觉得腻歪,总感觉有无穷无尽的动力和学习欲望。 总感觉有学不完的东西。
关于自动化
关于质疑自动化质疑技术的言论有很多, 但是你发没发现这几年质疑的声音越来越小了。 其实不是技术没用,只是技术不好,或者不懂得把技术转换生成产力才给人一种好像没什么用的错觉。 但既然有用的不好的,那就有用的好的。 只是可能很多人没去过像样的厂子所以没见过。 这方面我不多说了,免得又撕上逼了。 可以跟楼主举个我自己应用的例子, 我在我们团队使用 k8s 做自动化部署和 CICD 流程,支撑日千级的构建次数和超过 60 套环境的自动化运维, 这种量级的测试环境你让我人肉维护我要招聘多少个人? 就算是大家最看不起的 UI 自动化测试,都是放在 K8S 里分布式执行,40 个浏览器并发都要跑半个小时。 这种量级的测试用例你让我手工执行我要招聘多少个人? 所以我不劝别人怎么怎么样了, 我觉得技术和自动化很有用。
关于学习编程
这个我感同身受,以前没有目的的学习,大概也跟楼主是一样的。 学完了发现也没啥用,而且没有应用场景的学习基本也就是学个皮毛。 我现在只学能用的上的,尤其是能用在项目里的。 这时候就会发现学的有动力,而且应用场景越复杂,学的就越深。 有那么一句话是这么说的,技术的高低取决于问题的复杂度。这也就涉及到了我一直坚信的一个理念 ---- 抛离了业务的技术都是在耍流氓。
关于重复造轮子
这个我同样感同身受,有时候就是为了那点 KPI,为了晋升。各个大厂里晋升项目多的是,晋升了以后项目就没人维护了。 这个没办法,只能说有人的地方就有江湖吧。 这个我们只能严格律己,自己别这么搞就行了。 我现在做框架基本都是大杂烩,能用开源的就用开源的,很少自己造轮子。 顶多就是 2 次开发。 一个是因为没时间,事情太多,也没工夫装那个逼。 因为我们这里是结果导向,不管有没有造出特别牛逼的轮子,产品质量不行,什么都是扯淡。 再一个是因为我自己造的轮子也没人家开源的好啊,人都是好多个大牛共同开发出来的东西。我还真比不上。
关于测试组长只动嘴
一个合格的管理者确实有很多事情要忙,关注的东西很多,他确实没什么时间去做具体的事情了,这确实是跟技术人想象的不一样的,管理者不是只拍脑袋动嘴皮子,有很多时候是他帮手底下的人档住了很多锅和压力。 但那是基于管理一个有规模的团队和一个有规模的业务的前提下。 一个小测试组长手底下就那么几个人,对接的就那么点业务。这种规模的就别称自己是管理岗了,这么点东西有啥好管理的。这个确实是一个不好的风气。 我以前也碰见过不少这样的,都是在混日子的,我们不要学他们就好了。 不过就像我一开始说的,管理岗确实还是有很多事要忙的。 我现在的工作算半技术岗半管理岗吧, 我自己有测试任务,owner 了好几个模块。带着几个人一起做事。 同时我是公司 CICD 小组的 owner, 测试架构的 owner,自动化测试的 owner。 所以除了干活, 还要设计流程,搭建框架,组织会议,协调资源, 出规范出计划,还有几乎每天都有的面试。 我还带着几个新人,每周的培训也得有。 我甚至忙的有些框架都没法自己写了, 让同事写,但是我要 review 他的设计和代码。 我组内的新人我还要 review 测试用例,review 需求评审。 所以虽然一个测试小组长不干活是不对的,但也千万别觉得管理岗真的就整天无所事事了。
关于白盒测试
这是一个误区,白盒测试是最高大上的,其他的都是垃圾。。。这是一个最最最最大的误区。 就算是我们这些搞过白盒的人都不会有这个想法。。。 在一个庞大的系统中,某个模块的白盒实在是太渺小了。举个例子,白盒这是一个点或者线上的打击方式。关注面较窄,但很精。 但还有一种面上的或者说立体上的打击方式。 涉及一个产品生命周期的各个方面。测试里比如调度,数据等测试,或者 工程效率方面比如自动化运维,CICD 等等。 只能说工种不同,并没有高低之分。
-
你工作的成就感 (动力) 来自哪里?(除了穷之外) at 2018年05月03日
升职加薪是我最大的动力哈哈哈哈。
-
大家都在用什么方式管理测试用例 at 2018年04月30日
求 testlink API 的介绍
-
测试开发之路 -- 请不要打着人工智能的旗号在测试圈子骗人 at 2018年04月23日
网易云课堂中的吴恩达视频
-
Selenide 阶段性总结介绍 at 2018年04月18日
这就是 selenide 的 python 版本~~~
-
Selenide 阶段性总结介绍 at 2018年04月18日
这个我还真没用过~ 之后可以看看
-
Selenide 阶段性总结介绍 at 2018年04月18日
是吧~ 哈哈, 所以我一直安利这个框架
-
Selenide 阶段性总结介绍 at 2018年04月18日
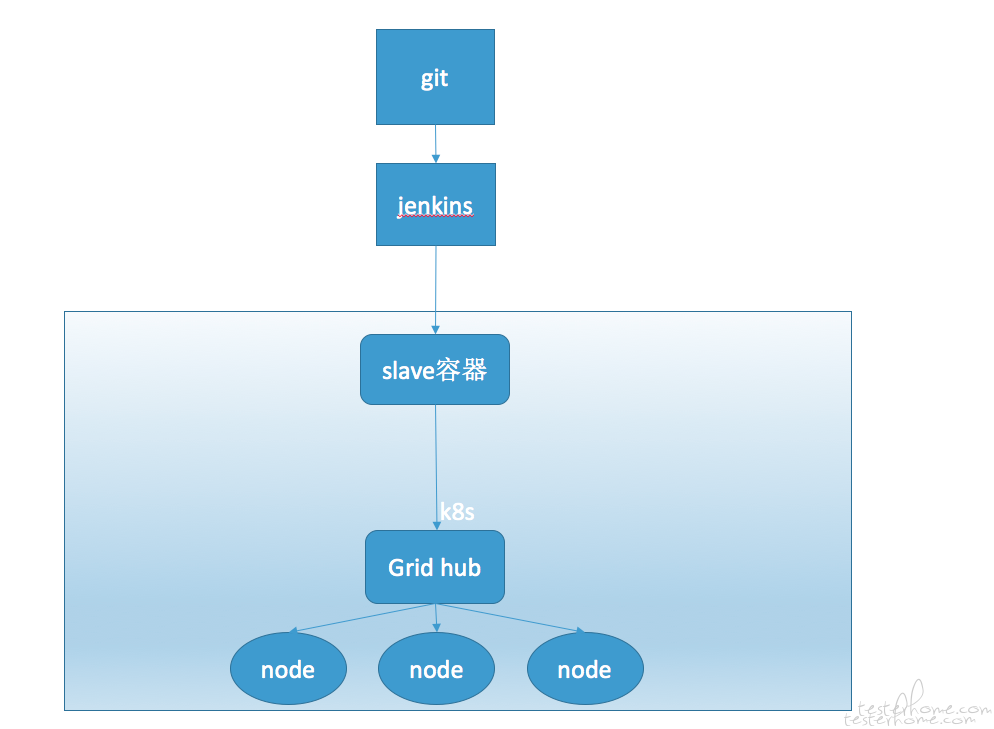
推荐 selenide+docker gird 架构, 最好跑在 k8s 里。 自动化运维和执行效率杠杠的。 我再我们这 40 浏览器并发,速度飞起
-
大家用过的好用的 web UI 自动化框架有哪些? at 2018年04月18日
其他的没太用过不敢评价, 比较火的比如 macaca,rf
-
Selenide 阶段性总结介绍 at 2018年04月18日
移动端的我没研究过了~~ 反正 web 端我觉得这玩意最好用了。听说 python 也支持 selenide 了
-
为公司写的一套系统,可以开源出去吗? at 2018年04月17日
开源要向公司申请的。 不能私自开源
-
目前从事自动驾驶方向的测试,比较迷茫,求解惑 at 2018年04月16日
之前面试过一个百度无人车的兄弟, 他的路子比较野,我描述一下他测试计算机视觉的那部分。 他会给他们的程序输入各种视频信号,然后检测程序对应的反应。 怎么检测呢? 他自己用树莓派 + 发光的二极管,再加一个视频录制装置,自动的录视频传给他们的程序测试程序对光源的反应。 这个思路野吧,这个哥们就属于有才的,软件硬件都会玩的。
同时自动驾驶中的很大一部分也是机器学习模型,可以考虑从这方面下手的。 如何评估模型,如何在模型产生过程中进行测试等等。 这种测试要求你懂机器学习, 比如我再测试我们公司的机器学习平台,这个平台是产生模型的平台。 我要懂机器学习算法和业务,才能测试的了这个平台。 比如平台里集成了 tensorflow 算子,那我要就去写 tensorflow 的代码去测试这个算子。 例如我上周做的事情就是用 tensorflow 写一个 cnn 去测试我们的 tensorflow 算子在 GPU 上和 CPU 上的性能。 所以做这部分测试对测试人员的硬性要求很高,就是要懂机器学习,这个绕不过去。 楼主加油努力, 无人车测试做好了很抢手, 有实力的大厂会陆续加入到这个行列中,到时候你做好了随便跳个曹就是高薪。 而且机器学习的原理在任何业务中都是相同的,就算你以后不做无人车方向了, 其他任何机器学习方向的厂子你都好进
-
深度学习基础 (十九)-- 使用 tensorflow 构建一个卷积神经网络 (上) at 2018年04月16日
mnist 数据集,2000 轮训练的 cnn 使用 GPU 只用了 11 秒。 速度快的飞起
-
深度学习基础 (十九)-- 使用 tensorflow 构建一个卷积神经网络 (上) at 2018年04月16日
先不看了,以后我们产品要是集成了 keras 再说吧。我现在用 tensorflow 是为了测试用的, 要测试我司的 SDK 和 GPU 能跟 tensorflow 完美交互。 我写这个卷积神经网络也是要测试 tf 运行在我们 GPU 上的性能。