前言
上一篇忘写了一点东西, 这次补上。
关于预测值稳定性的测试
我们在业务中会经常更新模型, 尤其是在自学习场景中。 每天都要中最新的数据更新模型。 所以除了一些模型本身的评估指标以外,新老版本模型的预测值的范围统计也比较重要,同时也比较容易忽略。 我们知道模型其实就是个特征数据库。 根据 LR 的公式 y=w*x +b。 x 是特征向量,w 是权重。 模型中会存储所有的特征和它的权重,当新数据来了要做预测的时候就会去模型中找到该数据命中的特征,把所有的特征和他们的权重相乘累加算出一个预测值来。 我们在做 2 分类问题的时候,sigmod 函数会把预测值转换成 0~1 中间的数字以方便我们进行 2 分类划分. 这时候我们设置一个阈值,假如说设置为 0.8。 所有预测值大于 0.8 的判断为正例,小于 0.8 的为负例。 这就是做分类问题的思路, 在统计模型的魂匣矩阵的时候,也是在特定的阈值下进行计算的。
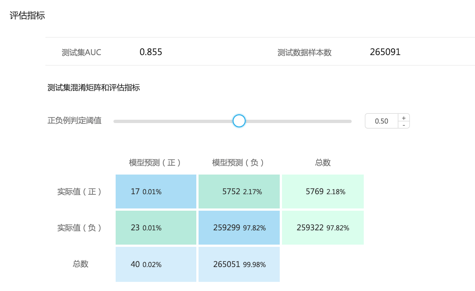
上面是一个混淆矩阵的图, 有一个阈值的拖动条, 在调整这个拖动条的时候我们下面的统计信息是会变化的。
说了这么多跟我们的测试有什么关系呢。 模型产出的只是预测值,至于要怎么使用预测值,阈值设为多少是跟模型本身没关系的。 由业务调用方自行决定。 所以如果模型的预测值范围发生变化,我们需要保证变化不会影响到调用方,或者说要通知调用方进行更改。 比如老模型的预测值分布比较均匀,基本就是在 0~1 中间均匀分布。而模型更新后预测值的分布比较极端,0.9~1 和 0~0.1 之间分布。 这就会有问题,因为调用方当初是根据老模型的 0~1 之间均匀分布的情况设置的阈值。 虽然新老版本模型的 AUC 和其他指标可能是差不多的,但是预测值查了很远。 调用方如果不重新调整阈值就会产生风马牛不相及的错误。 所以在更新模型的时候还需要加入的测试就是预测值的分布统计,也叫预测值的稳定性测试,一般是不准许预测值出现这么大的变化的。
决策引擎
在上个世界 6,7 十年代的时候大家对人工智能的定义是专家规则。 是说某个领域专家向系统中输入各种不同的规则来预测事物, 理论上只要输入的规则足够多,就可以达到人工智能的效果。 后来被证实为不靠谱的,因为人的分析能力的限制,我们无法输入那么多的规则。 但专家规则的使用却是保留了下来, 比如现在的银行中还保留了很多的专家规则系统,即便他们已经引入了机器学习能力但仍然保留着专家系统的使用。 为什么呢?主要为了防止黑天鹅事件,这些黑天鹅事件发生的概率很小,在庞大的训练样本中只占有了非常小非常小的份额,机器学习是一个偏向历史的预测系统,这么小的数据量很难针对这些黑天鹅事件学习出较好的模型。 但这些黑天鹅事件一旦发生的话会造成难以挽回的损失。 所以在这种情况下需要将人类指定的规则 --- 专家系统和机器学习系统混合使用。 某些情况下使用专家系统,某些情况下使用机器学习模型。 而做这个事情的,就是决策引擎。所以除了对模型本身进行测试以外。我们还要对决策引擎的规则进行测试。 到底什么时候用到了模型,什么时候用到了专家系统。 整个决策引擎的效果如何,都要进行测试。