-
为公司写的一套系统,可以开源出去吗? at 2018年04月17日
开源要向公司申请的。 不能私自开源
-
目前从事自动驾驶方向的测试,比较迷茫,求解惑 at 2018年04月16日
之前面试过一个百度无人车的兄弟, 他的路子比较野,我描述一下他测试计算机视觉的那部分。 他会给他们的程序输入各种视频信号,然后检测程序对应的反应。 怎么检测呢? 他自己用树莓派 + 发光的二极管,再加一个视频录制装置,自动的录视频传给他们的程序测试程序对光源的反应。 这个思路野吧,这个哥们就属于有才的,软件硬件都会玩的。
同时自动驾驶中的很大一部分也是机器学习模型,可以考虑从这方面下手的。 如何评估模型,如何在模型产生过程中进行测试等等。 这种测试要求你懂机器学习, 比如我再测试我们公司的机器学习平台,这个平台是产生模型的平台。 我要懂机器学习算法和业务,才能测试的了这个平台。 比如平台里集成了 tensorflow 算子,那我要就去写 tensorflow 的代码去测试这个算子。 例如我上周做的事情就是用 tensorflow 写一个 cnn 去测试我们的 tensorflow 算子在 GPU 上和 CPU 上的性能。 所以做这部分测试对测试人员的硬性要求很高,就是要懂机器学习,这个绕不过去。 楼主加油努力, 无人车测试做好了很抢手, 有实力的大厂会陆续加入到这个行列中,到时候你做好了随便跳个曹就是高薪。 而且机器学习的原理在任何业务中都是相同的,就算你以后不做无人车方向了, 其他任何机器学习方向的厂子你都好进
-
深度学习基础 (十九)-- 使用 tensorflow 构建一个卷积神经网络 (上) at 2018年04月16日
mnist 数据集,2000 轮训练的 cnn 使用 GPU 只用了 11 秒。 速度快的飞起
-
深度学习基础 (十九)-- 使用 tensorflow 构建一个卷积神经网络 (上) at 2018年04月16日
先不看了,以后我们产品要是集成了 keras 再说吧。我现在用 tensorflow 是为了测试用的, 要测试我司的 SDK 和 GPU 能跟 tensorflow 完美交互。 我写这个卷积神经网络也是要测试 tf 运行在我们 GPU 上的性能。
-
测试开发之路--Spark 之旅 (二):基础操作 at 2018年04月13日
加你了~
-
想知道一些测试薪资状况 at 2018年04月12日
变成脉脉匿名区了
-
深度学习基础 (十八)-- 使用 tensorflow 构建一个简单神经网络 at 2018年04月11日
恩,多谢提供链接哈
-
现在的中国测试也许和经济结构一样是个 M 型 at 2018年04月10日
我没想那么多, 就是在自己觉得对的路上埋头使劲干。 不犹豫,不彷徨,不退缩。 有踌躇不前的功夫,事情早就做出来了,路也走出来了。 延迟满足感,厚积薄发。 所以我从来也没怎么焦虑过,但我却一步一步走的更好了。 不要去管其他人什么水平,其他人开多少工资, 那都没用。 走好自己的路才是最实在的
-
深度学习基础 (十)--训练集,验证集和测试集 at 2018年04月09日
到底你们都是从哪听说的 6:2:2 这种配比的

-
深度学习基础 (十)--训练集,验证集和测试集 at 2018年04月09日
6:2:2 的这个做法肯定是不推荐的。 这样训练数据太小。模型效果不会好的
-
深度学习基础 (十三)--演讲稿: 机器学习服务的测试探索 at 2018年04月08日
主要是平时工作生活太忙了。。。没时间维护群。 能保持每周更新一篇文章就已经很不错了
-
小论 JS 原型链 (二) at 2018年04月06日
楼主比较喜欢用实际的代码来演示。 但这其实并不适合作为一篇文章,而更像是楼主个人的笔记。 可能楼主并不擅长讲故事吧。要讲明白原型链以及 proto 和 prototype 的区别其实还是需要很多文字和流程图的。 建议楼主更多的从受众的角度考虑如何做分享~~ 其实楼主在贴代码的同时,着重的讲一讲函数的 prototype 的指向以及对象的 proto 的指向再配合着贴一下类似下面这个图效果会好很多。
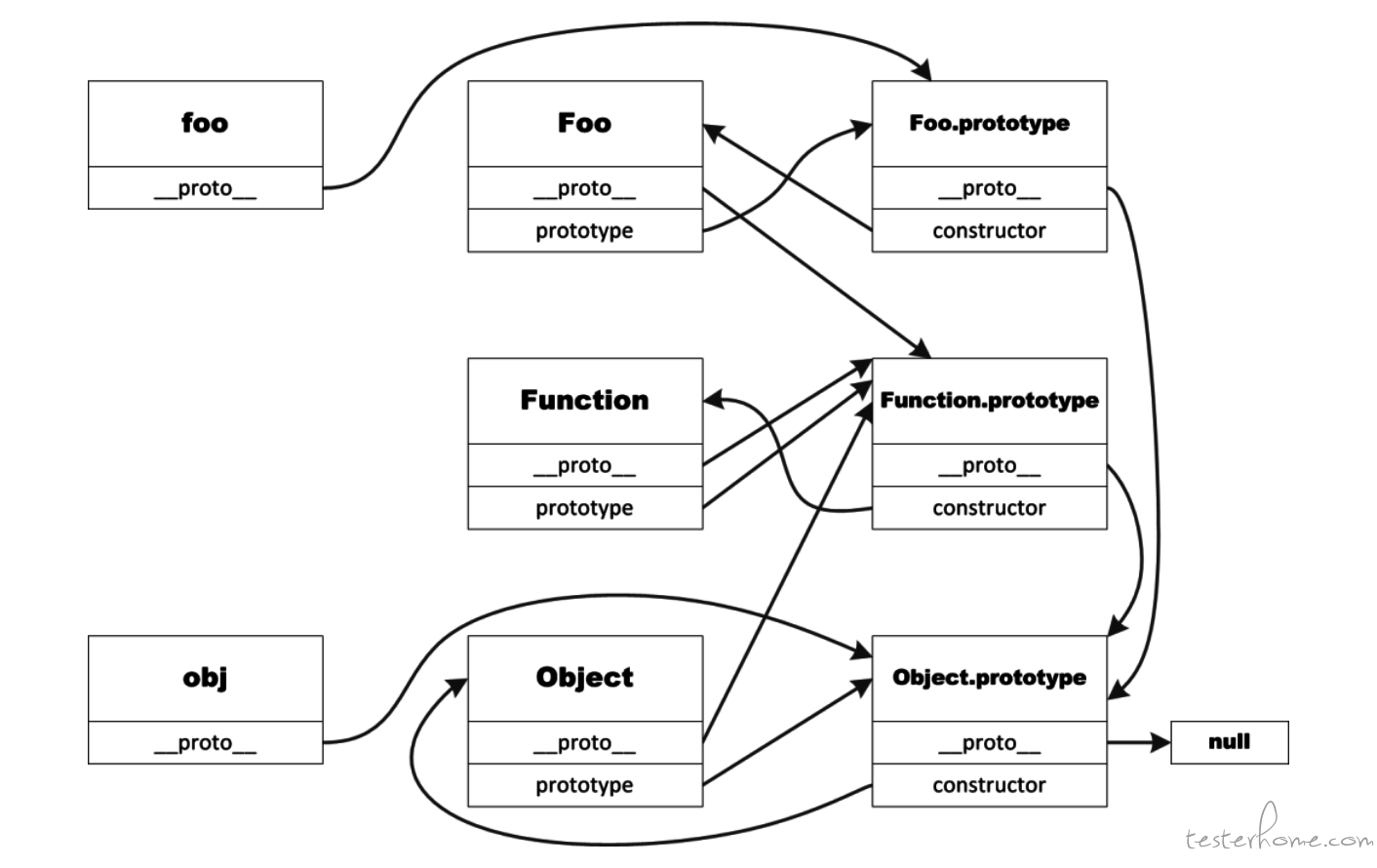
-
JS 系列学习 基本语法组合 at 2018年04月04日
恩恩~~ 坚持住哈~ 社区里还没有人写一个比较完整的 JS 系列帖子呢。 最好把 es6 也写进来, 然后选择三大框架里的一个也讲解一下。
-
JS 系列学习 基本语法组合 at 2018年04月04日
恩恩, 也建议把 eventloop 闭包这些东西也详细讲一下~
-
JS 系列学习 基本语法组合 at 2018年04月04日
既然写 es5 了~~ 起码把原型链解释清楚吧~~ 要不然直接 new 一个函数的方式人家会懵逼的~~ 你上面的 demo 也就是原本就会 js 的人才看的懂。。。 所以你这写出来给谁看呢。。。
-
当阿里云遇上 docker (三天两夜苦战 docker 记录贴) at 2018年04月03日
不错, 刚学完 docker 没多久就有这样的实践了。
-
深度学习基础 (十七)-- TensorFlow 中的变量 at 2018年04月03日
握个抓~
-
测试开发之路 -- 请不要打着人工智能的旗号在测试圈子骗人 at 2018年03月30日
机器学习的测试主要分两种,一种是把机器学习当黑盒子测试模型效果。 这个不用太懂机器学习,知道模型常用的评估方法就可以了,属于只要会机器学习中的模型评估部分就可以。 如果要测试机器学习平台, 那就要彻底的懂机器学习。 懂了就知道测什么了
-
测试开发之路 -- 请不要打着人工智能的旗号在测试圈子骗人 at 2018年03月30日
还没有这个群~~~ 话说你是哪家公司的同行呢。 目前有机器学习平台的公司没几家也。 咱们可以互相交流
-
测试开发之路 -- 请不要打着人工智能的旗号在测试圈子骗人 at 2018年03月30日
你可以看看我那篇演讲稿。里面讲了怎么测试
-
测试开发之路 -- 请不要打着人工智能的旗号在测试圈子骗人 at 2018年03月30日
不需要多久, 懂一些大数据的知识,懂一些机器学习的知识就行。 不用学很长时间的
-
北京买房应该考虑哪些因素 at 2018年03月27日
恩是啊。 我当时买的时候就是主要受这两个因素影响~~
-
北京买房应该考虑哪些因素 at 2018年03月27日
我感觉对我们这种穷人来说影响因素最大的就是价格和离公司的距离吧
-
深度学习基础 (十六)-- TensorFlow 概览 at 2018年03月26日
我 spark 还行,没碰到特别恶心的事。。。因为公司里一堆搞 spark 的。。我遇见坑了就能问。。 tensoflow 也用现成的镜像搭环境~~~ 话说你们要做数据测试了么? 也研究上 spark 了
-
深度学习基础 (十六)-- TensorFlow 概览 at 2018年03月26日
感谢支持~~ 没人留言我都感觉好孤独