前言
之前学习了训练模型的一些原理,包括特征工程,算法原理和一些超参数。 那么生成了一个模型后我们如何评估这个模型的好坏呢。 今天主要讲一下二分类模型的一些评估方法。
混淆矩阵
准确率 (accuracy):对于给定的测试数据集,分类器正确分类的样本数与总样本数的之比。单纯地使用 “准确率 accuracy” 是没法判断模型的好坏的,比如这个例子:健康的人有 99 个 (y=0),得癌症的病人有 1 个 (y=1)。我们用一个特别糟糕的模型,永远都输出 y=0,就是让所有的病人都是健康的。这个时候我们的 “准确率” accuracy=99%,判断对了 99 个,判断错了 1 个,但是很明显地这个模型相当糟糕。因此需要一种很好的评测方法,来把这些 “作弊的” 模型给揪出来。 所以我们先来讲一下混淆矩阵.
对于一个二分类问题来说,将实例分为正类(Positive/+)或负类(Negative/-),但在使用分类器进行分类时会有四种情况
- 一个实例是正类,并被预测为正类,记为真正类(True Positive TP/T+)
- 一个实例是正类,但被预测为负类,记为假负类(False Negative FN/F-)
- 一个实例是负类,但被预测为正类,记为假正类(False Positive FP/F+)
- 一个实例是负类,但被预测为负类,记为真负类(True Negative TN/F-) 为了全面的表达所有二分问题中的指标参数,下列矩阵叫做混淆矩阵 - Confusion Matrix
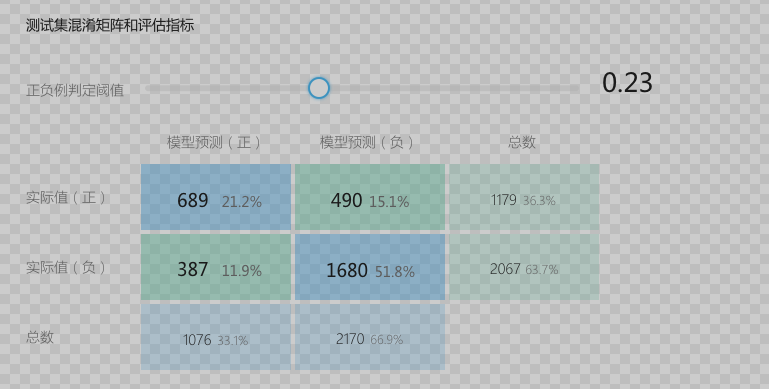
上面是我们先知平台的二分类模型评估报告中的混淆矩阵。我们知道二分类算法的激活函数是 Sigmoid,它除了为线性函数增加非线性效果之外,还可以把与测试转换成 0~1 的数字。 这样有利于我们做二分类。 如上图我们把预测值的阈值设置为 0.23,也就是说预测值大于 0.23 我们判定为正例,小于 0.23 我们判定为负例。在这个前提下算出上面的混淆矩阵。
评估指标
精准率 (precision)
根据混淆矩阵我们可以算出一些指标来评估模型。 首先是精准率 (precision)。还是拿刚才的癌症的例子说。精准率 (precision) 就是说,所有被查出来得了癌症的人中,有多少个是真的癌症病人。公式是 TP/TP+FP
召回率 (recall)
召回率就是说,所有得了癌症的病人中,有多少个被查出来得癌症。公式是:TP/TP+FN。 意思是真正类在所有正样本中的比率,也就是真正类率 (TPR)。
TNR (specificity)
TNR, 就是 true negative rate 的简写。 真负类比率。公式是:TN/TN+FP。 也就是所有健康的人中,有多少是被预测为健康的。
NPV
NPV, 也就是 negative predictive value 的缩写。 公式是:TN/TN+FN. 也就是被查出健康的人中,有多少个是真的健康的。
F1 Score
我们主要评估召回率和精准率。它们是一对。拥有高精准率或者高召回率的模型是一个好模型。注意:我们是对稀有类别使用的查准率或者召回率,而且我们会将这个 “稀有类别” 设置成 y=1!!!我们希望对于某个模型而言,在 precision 越高的情况下,recall 也会越高,但是有些情况下这两者是矛盾的,现在来考虑下面情况。
第一种情况:当且仅当非常确信他得癌症了,才确诊他得了癌症,即:
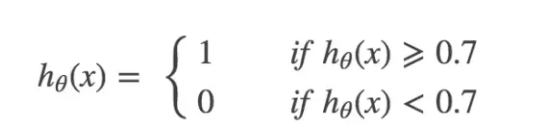
这个时候,就是要 “高的精准率”,结果导致了 “低的召回率”。第二种情况:只要怀疑他得了癌症,就确诊他得了癌症,即:
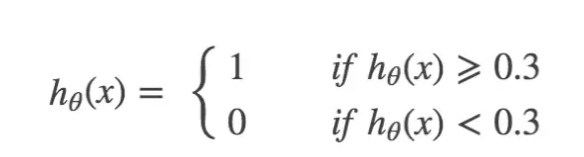
这个时候,就是要 “高的召回率”,结果导致了 “低的精准率”。我们需要一个标准可以综合这二者指标的评估指标,用于综合反映整体的指标,其中一种标准就是 F1 score。 比如,当 precision 或者 recall 中有一个特别差的时候,F1 会特别低。 当 precision 和 recall 都特别好的时候,F1 也会特别好
评估指标图
下图是一个 demo, 在当前混淆矩阵下的评估指标趋势
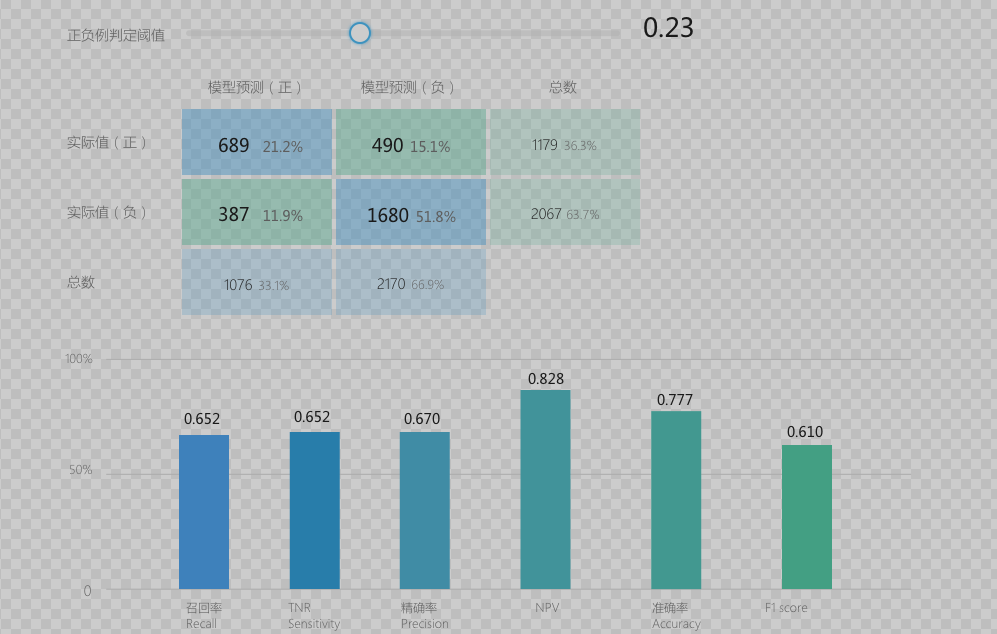
ROC
ROC 是评估一个模型的重要指标。 那什么是 ROC 呢?ROC 曲线和混淆矩阵息息相关。它的横坐标:FPR 假正类率,纵坐标:TPR 真正类率。 具体看下图:
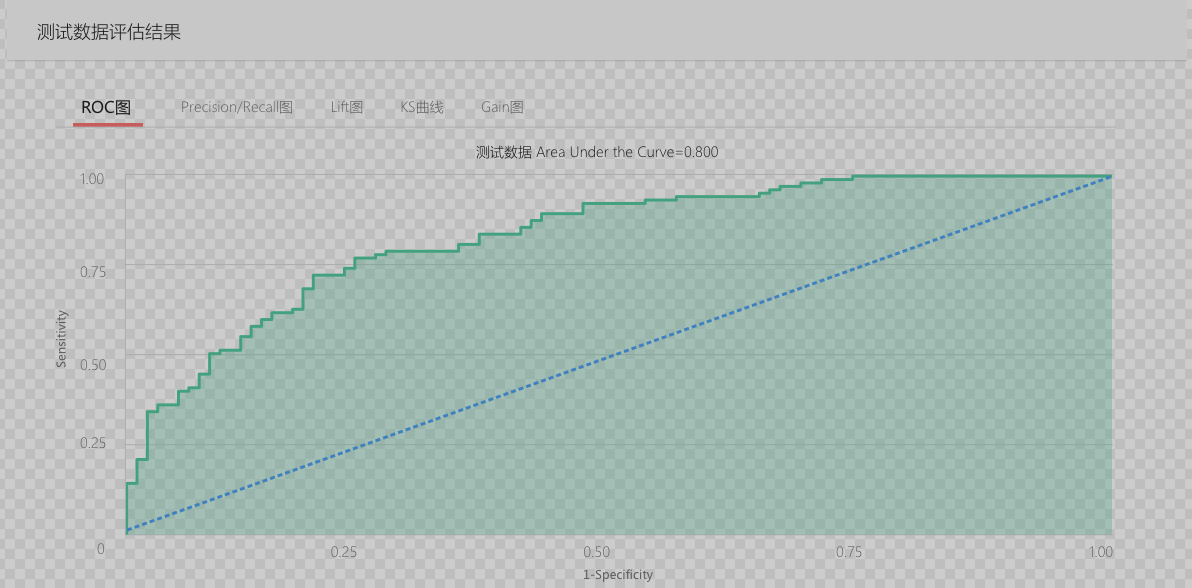
按照这种方法来分析 ROC 曲线:
- 第一个点:(0,1),FPR=0 TPR=1 ,这意味着所有的正类全部分类正确,或者说这是一个完美的分类器,将所有的样本都分类正确了
- 第二个点:(1,0), FPR=1 TPR=0 ,和第一个点比较,这是第一个点的完全反面,意味着是个最糟糕的分类器,将所有的样本都分类错误了(但其实可以直接取反,就是最好的模 - 型,因为是二分类问题)
- 第三个点:(0,0),FPR=0 TPR=0 也就是原点,这个点表示的意思是,分类器预测所有的样本都为负类
- 第四个点:(1,1),FPR=1 TPR=1,和第三个点对应,表示分类器预测所有的样本都为正类一条线:y=x。这条对角线上的点实际上就是一个采用随机猜测策略的分类器的结果
总结来说,ROC 曲线的面积越大,模型的效果越好;ROC 曲线光滑以为着过拟合越少
AUC
AUC - Area Under Curve 被定义为 ROC 曲线下的面积。AUC 值越大,证明这个模型越好。 AUC 是我们最重要的评估指标。ROC 不好量化,而 AUC 在 0.5~1 之间。 值越大越好。非常容易量化模型好坏
结尾
关于二分类评估方法还有 k-s 图,lift 图等,i 不过我还没研究明白。 以后研究明白了再写