刷题去WLB965 昨晚虾皮一面面试官出的一道题:利用随机生成(0,1)方法随机生成 0~1000 的数
如题,刚开始回答利用二进制,可以实现,但是二进制随机值是 0-1024,不符合。
后来一想,可以用累加法,但是好像哪里不对。
def randomunm():
re=0
for i in range(0,1001):
re=random.randint(0,1)+re
return re
执行一万次,发现值分布均在 400-599 之间。大家有更好的解决思路么。
你这个算法其实有点类似于统计概率了相当于统计 1 出现的次数,总次数越多结果越接近总数的 50%,我的想法是用 0/1 生成 10 位 2 进制数据拼接转换,结果最大 1023,最小 0,大于 1000 就爆掉重新生成一次。
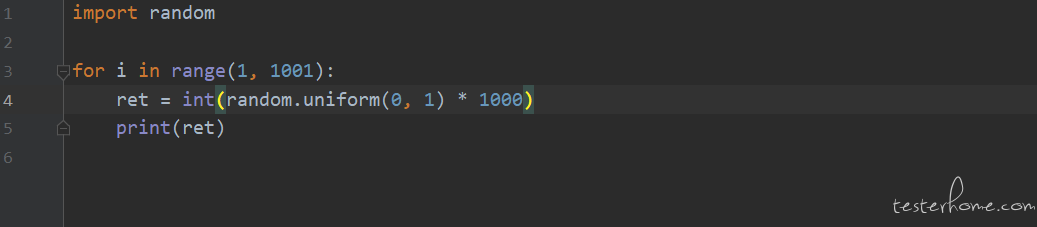
random.random()*1000 这样
Math.ceil(random.nextDouble()*1000) 就行了吧。。。
取 0-1 之间的小数,乘 1000 后向上取整。
楼上讲的取小数乘 1000 之后取整是 ok 的,另外还有一种办法,随机生成 0~N 的数,可以用随机数对 N 取余,这里是 (0, 1),数值比较小,就可以先扩大 10000 倍再对 1000 取余也是可以的。
题目都没看懂
绕了一会才想明白,原来是只能生成 0 和 1 这两个值,所以就不能用类似 random.random() 的方法去获取一个 0 与 1 之间的小数。目前想到的解法也就是累加和 2 进制了,蹲个更好的答案。
这个就是类似前几天力扣每日一题的 rand7 实现 rand10 吧
但是这个难点在于不知道如何设计拒绝采样,暂时想不出很好的思路
可以使用二进制先生成 9 位的二进制数,转换为十进制加一后,丢弃掉 500 以上的;然后再执行一次 rand 函数,生成的数加一后乘前面那个十进制数就行了,当然这里的乘也可以使用移位运算;
- 生成 n 位随机浮点数 f
- 然后浮点转成字符串
- 字符串取 hash 值,然后再取绝对值
- 最后除 1000,取余
abs(hash(str(f))) % 1000
随机 9 位(512)+ 随机 8 位(256)+ 随机 7 位(128)+ 随机 6 位(64)+ 随机 5 位(32)+ 随机 3 位(8)=1000?
不知道随机数加随机数算不算随机数
总体思路:
1000 = 512 + 256 + 128 + 64 + 32 + 8
按照上面挨个构建上面的值,再组装起来
# python
import random
a = [256, 128, 64, 32, 16, 8, 4, 2, 1]
b = []
for i in range(9+8+7+6+5+4):
b.append(random.Random().randint(0, 1))
data = [b[0:9], b[9:17], b[17:24], b[24:30], b[30:35], b[35:]]
def cal(data: list):
sum = 0
for j_data in data:
for i, value in enumerate(j_data):
sum += a[8-i]*value
return sum
print(data)
print(cal(data))
[[1, 0, 1, 1, 1, 0, 1, 1, 0], [0, 0, 1, 1, 0, 0, 0, 0], [0, 1, 0, 1, 0, 1, 0], [1, 0, 1, 1, 1, 0], [0, 0, 0, 0, 0], [1, 1, 0, 1]]
315
这个概率是有问题的,简单举例:要求为 0 的概率 1/1000;现在需要 6 次随机恰好都为 0,概率远小于 1/1000
每 200 为刻度跑了 1000 次统计的结果:37 275 394 259 35
“执行一万次,发现值分布均在 400-599 之间” 是不是我理解有问题。值不可能都分布在 400-500 之间吧,求指导
随机这事可太折磨人了,这题也不知道原始出题人的思路是啥,到底想考察哪方面,建议大家不要使用这道题
利用随机生成(0,1)方法随机生成 0~1000 的数
我看到第一反应也是 random.random()*1000 ,日常写代码要取某个范围内的随机正整数就是这么写的,random.random() 生成的是大于 0,小于 1 的随机数。但这里有两个不确定的点:
1、随机生成 (0, 1),不知道是指只会随机生成 0 或者 1,还是生成 0-1 这个范围内的数字。
2、生成 0~1000 的数,不知道 0-1000 是范围还是啥。
结果拼接为字符串,然后二进制转换为整数,拒绝采样,去掉大于 1000 的。
rand 每次结果是独立的,把 10 次 rand 取值通过进制转换为 0-1024 的一个随机数,其中每一个概率都是一样的。去掉大于 1000 部分的就是 0-1000 的随机数了。
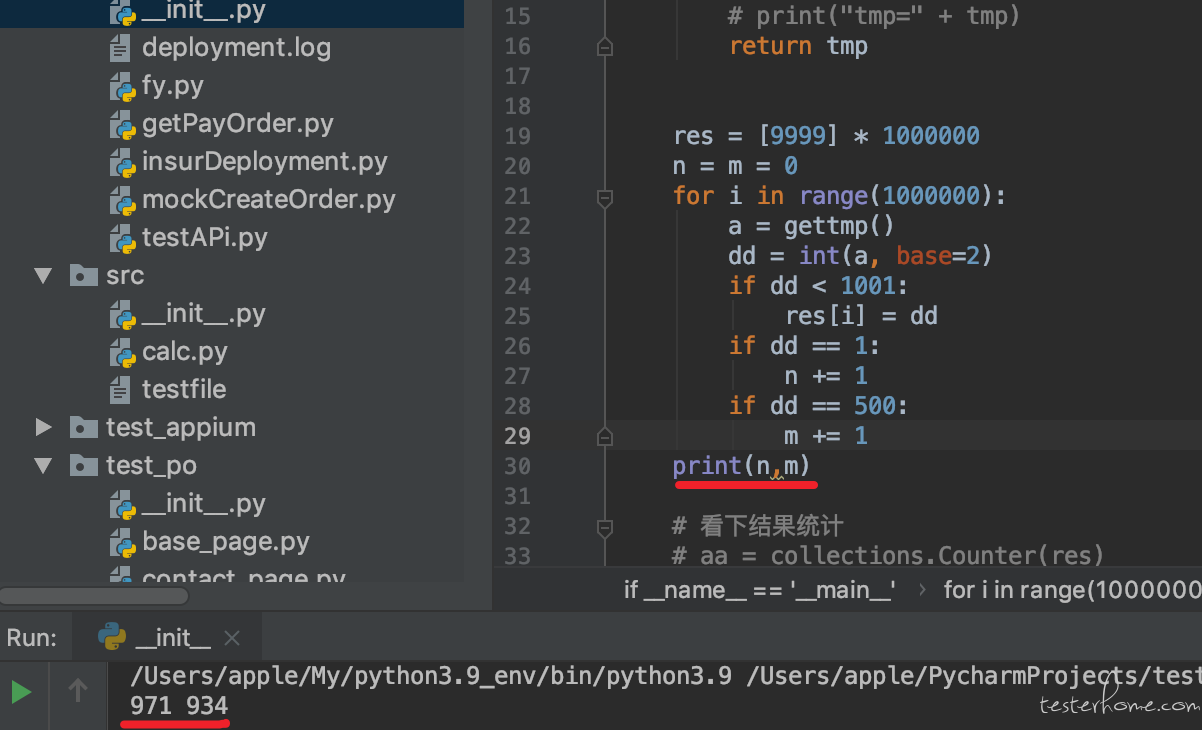
def rand():
return random.randint(0,1)
def gettmp():
tmp = ''
# 没次结果都是独立的,连续10次可以视为0-1024内均匀随机
for _ in range(10):
tmp +=str(rand())
return tmp
res = [9999]*1000000
for i in range(1000000):
dd = int(gettmp(),base=2)
if dd<1001:
res[i] = dd
# 看下结果统计
aa = collections.Counter(res)
# 去除掉9999(被拒绝掉的大于1000的部分)
aa.pop(9999)
# 出现最多的次数
print(max(aa.values())) #1077
# 出现最少的次数
print(min(aa.values())) #894
# 元素个数
print(len(aa)) #1001 [0-1000]

看到社区的公众号推送了,并且也有我的答案。
那我还是补一下坑~
代码实现
import random
from collections import Counter
def get_str() -> str:
random_str = [str(random.randint(0, 1)) for _ in range(40)]
return "".join(random_str)
def get_hash(s) -> int:
return abs(hash(s))
def get_random() -> int:
s: str = get_str()
h: int = get_hash(s)
return h % 1001
def main():
res = []
for _ in range(10000):
r = get_random()
res.append(r)
c = Counter(res)
# 所有结果,最多只有1000个
count_all = c.most_common(1000)
# 出现次数最多的前10个
print(count_all[:10])
# 出现结果最少的10个
print(count_all[-10:])
d = dict(c)
# 1000出现的次数
print(d.get(1000))
# 500出现的次数
print(d.get(500))
# 0出现的次数
print(d.get(0))
if __name__ == '__main__':
main()
运行结果
[(109, 23), (387, 21), (696, 20), (867, 20), (900, 19), (354, 19), (625, 19), (444, 19), (563, 18), (70, 18)]
[(738, 3), (77, 3), (603, 3), (800, 3), (106, 3), (780, 2), (228, 2), (22, 2), (778, 2), (107, 2)]
13
16
6
贴一个笨方法:
import collections
import random
# 这是题目所给的rand1函数
def rand1():
return random.randint(0, 1)
# 实现1-4的随机函数
def rand4():
number1 = rand1() + 1
number2 = rand1()
while number2 == 1:
number2 = 2
return number1 + number2
# 根据rand4生成1-8的随机函数
def rand8():
number1 = rand4()
number2 = rand1()
while number2 == 1:
number2 = 4
return number1 + number2
# 根据rand8生成1-16的随机函数
def rand16():
"""
省略
"""
# 根据rand16生成1-32的随机函数
def rand32():
"""
省略
"""
"""
省略rand64(),rand128(),rand256(),rand512()
"""
# 根据rand512(),先拒绝采样,然后处理
def rand1000():
number1 = rand512()
while number1 > 500:
number1 = rand512()
number2 = rand1()
while number2 == 1:
number2 = 500
return number1 + number2
# 测试函数
ans = []
tar = 0
for _ in range(100000):
ans.append(rand32())
answer = collections.Counter(ans)
for _ in answer:
tar += 1
print(tar)
print(answer)
有个不明白的地方请教一下:连续连续 10 次的 0、1 感觉不会 0-1024 内均匀随机啊,比如=1 要 000000001,这个要比其他 0、1 参半的概率低很多。
可是验证出来结果却是比较均匀的。。。
可以理解为连续抽奖 10 次 ,中奖的概率为 50%,每次抽奖的结果都是独立的。连续十次后中奖的汇总情况就有 2^10 种,且每种结果的概率都是一样的 1/1024。
比如=1 要 000000001,这个要比其他 0、1 参半的概率低很多。
1111100000(992)跟 0000011111(31)不是一样的~

import random
def randomOutput():
out = ""
for _ in range(10):
a = random.choice([0, 1])
out += str(a)
if int(out, 2) > 1000:
return randomOutput()
else:
return int(out, 2)
b = []
for i in range(1000):
b.append(randomOutput())
这题就是简单的 2 进制 + 拒绝采样叭。我输出测试了下,好像比较平均。不知道符不符合楼主思路呢
不知道我理解的对不对
import random
data = []
def get_data():
while True:
for i in range(10):
data.append(str(random.randint(0, 1)))
data1 = int(''.join(data), 2)
if data1 <= 1000:
return data1
else:
data.clear()