本帖已被设为精华帖!
一、关于项目需求——按需定制测试方案
说到性能测试的 cpu 及内存优化和异常发现,不同产品以及测试人员隶属(服务对象)不同,测试要求和测试目的是不同的,下面按个人理解分别说明下:
1、测试人员的隶属(服务对象)
(1)隶属功能测试组
-
服务对象
- 服务于各部门对版本上线的评估,将版本中发现的问题提交研发人员修改。
-
特点
- 黑盒功能测试,见不到代码也不关心代码逻辑。
- ——依据测试策略所出的报告结果评估版本风险,给版本是否发布提供依据,提交的 bug 是依据现象和测试数据,优先级是对用户的影响和后果严重性。
- 功能测试组的自动化/工具组,服务于黑盒功能测试。
- ——提供解放人力的自动化脚本方案解决部分人工压力,为特定测试需求提供脚本方案/工具,产出是要交付测试流程的。
-
CPU/内存测试目标
- 监控数据标准,及时提出优化改善意见并监控衰减;发现异常情况 bug:内存泄露,CPU 负载异常。
-
测试方案建议
- 监控数据采集及呈现方案附加在测试流程中,特别需求建立专项评估测试。根据版本周期长短调整测试内容,控制测试用例粒度。
注:我主要从事就是此类工作,有实践成果后文介绍。
(2)隶属于研发测试组(多见于 BSP 研发团队)
-
服务对象
- 服务于研发人员对修改引入风险的专项测试需求,研发人员在测试版本上的内部评估。
-
特点
- 自动化脚本测试,服务于开发人员的测试,根据研发对代码修改可能带来问题的猜测,组织测试方案验证,可以看到代码。
-
CPU/内存测试目标
- 验证研发人员代码设计上的问题及模块改动带来的风险。
-
测试方案建议
- 根据代码逻辑及加载的资源大小加 log 获取数据,对应逻辑行为统计分析数据,需要和研发人员的沟通结论基础和代码分析基础。
注:由于本身自己未从事此类工作,只是说明下如果我做会是这个思路
二、本人关于性能测试的方案设计与实践经验——测试标准和研发人员推动力非常重要
1、测试标准
(1)性能测试标准要多部门参与制定,大多数人认可
(2)基于用户体验的标准将研发排除在外,按照:
- 其他部门设定标准
- —>通知研发
- —>研发质疑标准(如果有)
- —>竞品数据对比(说服研发或修正标准)
- —>稳定落实到测试流程长期监控。
2、测试数据评价的监控
(1)思路:
- 依据测试标准设计按 case 评价得分的打分体系,根据总分变化呈现性能监控,报告监控数据变化,依据数据分析重点衰减用例。
(2)打分原则:
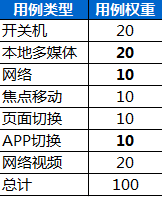
- Ⅰ、用例归类,按类别分权重。(评估版本相关部门参与制定权重)
- Ⅱ、用例权重分类,按对于评估用户体验的价值分为三档。
- 基础为 1;用户频繁常用场景 +1;用户多数在使用的测试条件 +1
- 用例评分=(所属测试类权重/用例价值总计)* 此条用例的用例价值
- Ⅲ、设计用例打分原则
-
- Ⅳ、设计数据统计展示方式:
- 我是采用的设计 excel 公式模板,每次贴数据自动计算,更新趋势图数据范围即可

3、性能测试用例设计及测试数据采集
(1)采集响应时间
- 加载时间,翻页时间,开关机等,根据项目需求设计
(2)取数据方式
- 录像数帧出数据,脚本获取时间等数据采集方式,根据数据准确性和精度要求评估
4、结果监控形式
(1)评分走势分析
- 评分降低,重点分析衰减项,超标准则提交 bug 由研发人员分析
(2)报告反馈与推进解决
- 测试结果报告发给所有评估版本质量的部门,多部门参与推动问题分析解决进度。
三、内存及 cpu 监控方案
1、测试方案选择
(1)测试流程内集成监控方案收集数据
- 数据可视化展示及分析数据,形成报告产出 bug
- ->下一个版本测试流程内回归验证修改(如有特定需求,可定制专项测试,测试版本验证)
-
适用条件
- 有成型测试模型和测试流程的,并且版本测试周期内测试时间充分的项目
-
说明
- 我这边的测试需求是系统软件版本整体的测试,也包括重点进程的测试监控,既要监控 java 层的进程也包括 Native 层的进程,还有集成 so 的 NDK 开发的应用进程。而且有成型的版本测试模型和流程,每部分测试都有指定的测试组负责。所以自己设计了监控方案集成到测试流程内,提供可视化分析方法便于交付。
-
集成监控测试的场景例举
- Daily Smoke 自动化脚本;MTBF 稳定性测试;新增功能性能评估;专项测试评估;稳定性压力测试评估;OOM crash 类 bug 复现数据分析等。
-
成本开销
- 增加分析结果,验证复现的定位分析投入。
(2)细化测试用例粒度,选择重点风险用例采集数据评估具体的操作细节。
-
适用条件
- 测试周期短,人力投入有限,没有长期稳定的测试流程的项目。
-
说明
- 没做过这类测试,未实践尝试,只是个人认为此类测试应该是这个思路。
2、我所实践的监控方案设计
(1)采集数据:
- Ⅰ、总 CPU 和进程 cpu
- 来源:
busybox top -b -n 1 - 选择原因:比 top 命令执行响应速度高,耗时 0.2S 左右,top -t 需要 3s 左右;并且精度到 0.1,花括号内有正在处理的进程参考
- 来源:
- Ⅱ、总内存
- 来源: /proc/meminfo
- 取关注的项:MemFree,Buffers,Cached,Active,Inactive,Active(anon),Inactive(anon),Active(file),Inactive(file),Dirty,Writeback,Mapped,Slab,包含 CMA 模块的增加 CMA Free
- Ⅲ、进程内存
- 来源首选:
dumpsys meminfo 进程PID - 获取:Native Heap Size;Native Heap Alloc;Native Heap Free;Dalvik Heap Size;Dalvik Heap Alloc;Dalvik Heap Free;Totle Pss;Dalvik Pss;Dalvik
- 来源备选:如果 native 进程取不到则用
cat /proc/进程pid/smaps|grep Pss求和取 Pss
- 来源首选:
- Ⅳ、获取时刻显示的 Activity
- 来源:
dumpsys window w|grep mFocusedApp|busybox awk '{print $5}'|busybox tr -d '}'
- 来源:
- Ⅴ、获取时刻的时间
- 来源:
date +%Y/%m/%d" "%H:%M:%S
- 来源:
- Ⅵ、系统启动后运行时间
- 来源:
busybox awk -F. 'NR==1{print $1}' /proc/uptime - 注:用于分析执行监控的时刻及准确的获取数据间隔
- 来源:
(2)数据格式化输出
- Ⅰ、总 cpu——cpu.csv
- Loop:10,Time,Activity,usr,sys,nic,idle,io,irq,sirq,Data Time
- 注:10 是设定的间隔,使每个 csv 可以直接取到间隔用于计算时间;Time 是开机已运行时间
- Ⅱ、进程 cpu——cpuinfo.csv
- Loop:10,Time,PID,%CPU,Command,avgs,Thread
- 注:Thread 是花括号{}内的进程,avgs 是命令行后的参数,都有的情况优先取命令行参数。
- Ⅲ、总内存——mem.csv
- Time:10,MemFree,Buffers,Cached,Active,Inactive,Active(anon),Inactive(anon),Active(file),Inactive(file),Dirty,Writeback,Mapped,Slab
- 注:选择在 cpu.csv 中记录 loop 是由于需要有列 loop 数据判定脚本抓取数据是不是连续正常的,而这里可以用行号计算。
- Ⅳ、进程内存——meminfo.csv
- Loop:10,Time,PID,Process_Name,Pss,Native_Heap(Size),Native_Heap(Alloc),Native_Heap(Free),Dalvik_Heap(Size),Dalvik_Heap(Alloc),Dalvik_Heap(Free),Dalvik_Pss,Avgs
- 注:Avgs 是进程的命令行参数,/proc/进程 PID/cmdline 取的数据
(3)数据可视化展示——highcharts
- Ⅰ、控制每张图的数据量
- 显示数量在 400 以内,时间段切片显示,默认按照 1 小时,根据间隔变化调整
- 原因:由于数据量限制一张图默认最多展示 1000 个点,加上数据点越多打开及交互响应慢
- Ⅱ、所有图共用数据
- 每个点显示:Activity;系统时间
- Ⅲ、进程 CPU 数据线和内存数据线总体设计
- 同进程跨间隔 loop 数之间 cpu 记 0;新增 PID 标红点;同一时间点同名多进程存在则横坐标累加 1/10n 标黄点,n 为同一 loop 的重复次数。
- Ⅳ、进程 CPU 数据图
- 按峰值降序排列显示 top5;可多选交互更新;有参数数据的查看点信息时进程同颜色展示;
- Ⅴ、总内存图:
- 总内存图:剩余内存=MemFree+Buffer+Cache,Active,Inactive,io=Dirty+Writeback,Mapped,Slab;
- 剩余内存图:剩余内存,MemFree,Buffer,Cache,如有 CMA 则增加 CMAFree
- Dirty 和 Writeback 图:Dirty 和 Writeback
- Active 和 Inactive 图:Active,Inactive,Active(anon),Inactive(anon),Active(file),Inactive(file);
- Mapped 和 Slab 图:Mapped,Slab
- Ⅵ、进程内存 PSS 多选展示图:
- 按每张图数据,进程 PSS 峰值降序排列
- Ⅶ、单进程内存数据展示图:
- 按进程 PSS 极值差降序排列;java 进程显示 heap 详细数据,native 进程只显示 PSS
- Ⅷ、附加
- 数据双横轴切换:sleep*loop 传参数的计算时间;Time 是精确每个取数据命令获取的开机已运行时间;
- 更换图标主题和生成图片的 highcharts 功能
3、方案采取的脚本设计
(1)shell 脚本获取数据:
- 按顺序获取
- ->显示的 Activity
- ->系统时间
- ->CPU
- ->总内存
- ->进程内存(最大限制并发 5 子进程获取)
- 注:监控所有进程采集数据开销大,当前优化后的逻辑也需要 6-8S 采集一次,随进程增多会增长;单进程获取可以在 1S 完成。
(2)Python 转换数据为 json:
- 按显示模板设计生成指定形式的 json 文件,并和模板文件一起打包成 zip
(3)node-webkit 框架数据展示:
- 由于需要加载本地 json 文件,最后选取了此框架展示,以解决浏览器本地文件读取限制问题及处理性能问题。
4、效果展示

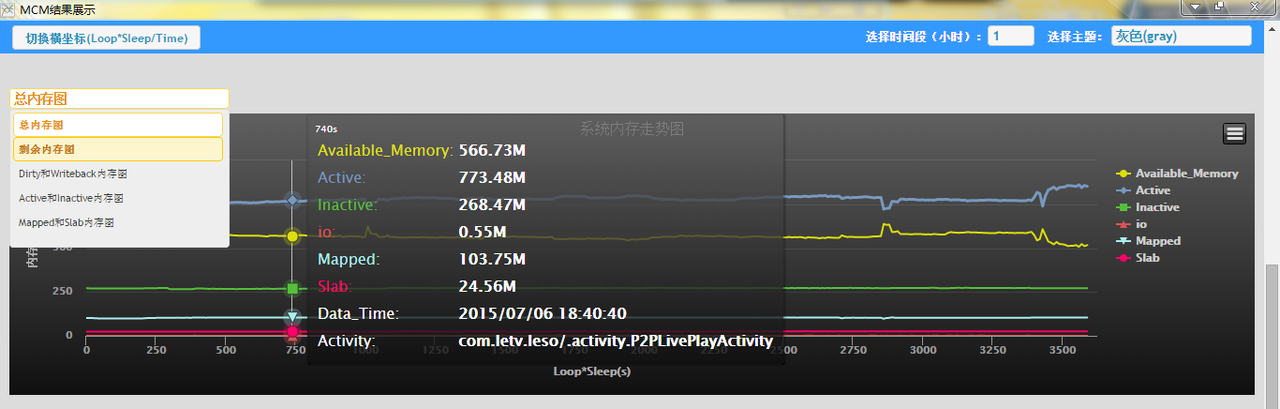
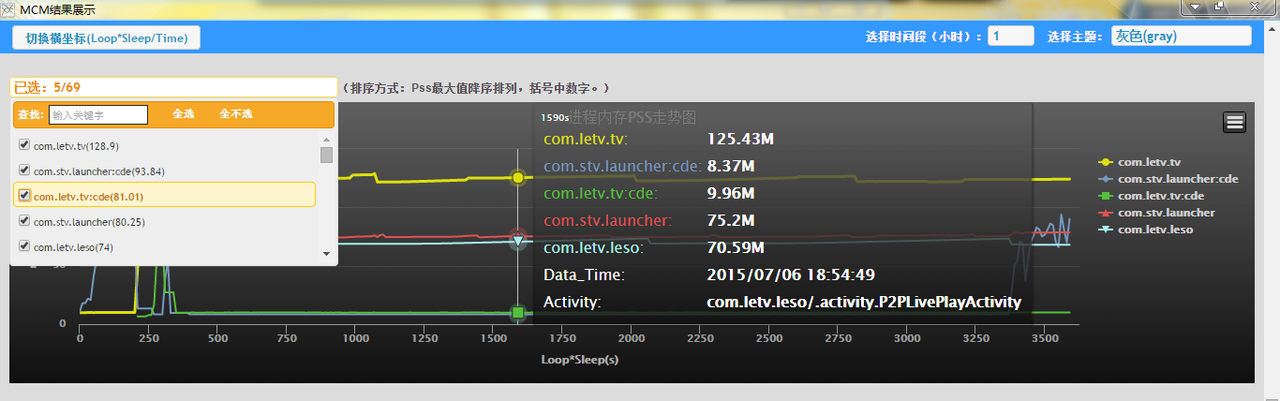
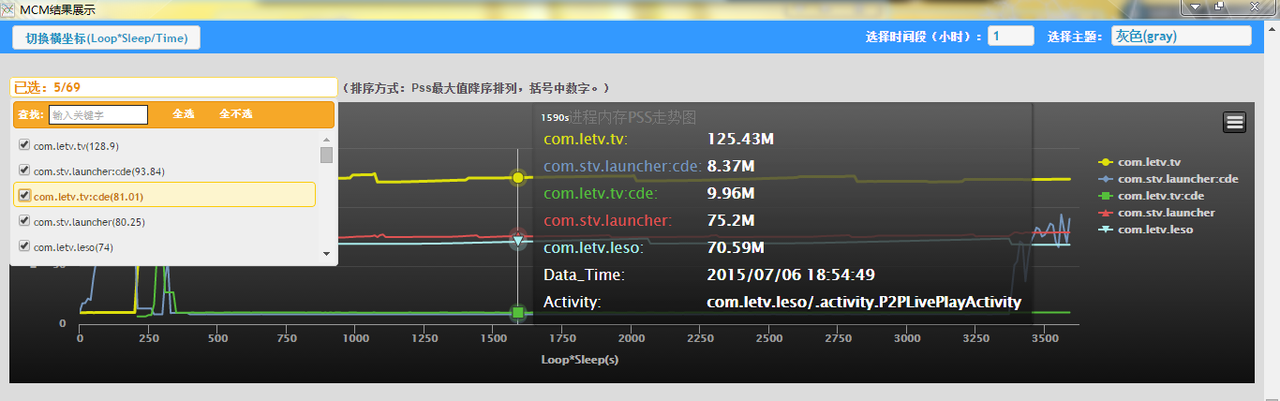

考虑了下,还是把工具放出来吧,有想尝试的可以实际试下效果。
1.关于兼容:只是适配了乐视项目情况,是否适用所有兼容机情况没什么把握
2.关于使用前提:需要 root+busybox
3.平台说明:已打包了 windows 下的 exe;shell 脚本可以直接 push 使用不涉及平台兼容;CSVtoJson.exe 就是将 output.py 打包成了 exe;MCM 结果显示.exe 就是打包了 node-webkit 框架的 win32 版本,由于此框架本身是跨平台的,可自行解决跨平台需求。
4、如果想修改为在线版本加载 json,需要修改 Html 模板中的 json 加载部分,MCM_HTML/head/mcm.js 里 node 加载 json 的语句为在线获取。
「原创声明:保留所有权利,禁止转载」
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!