这两天做压测,用了Constant Throughput Timer 来限制 QPS。
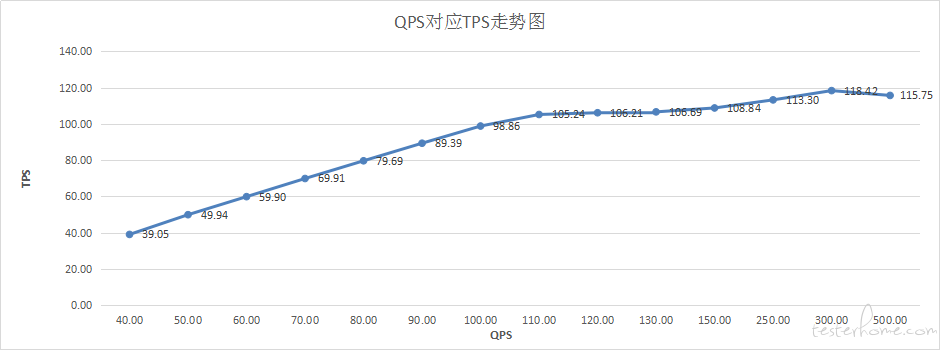
被压测接口最大 TPS 为 110 左右,在 QPS 达到 110 前,QPS = TPS,而 QPS>110 后,接口 TPS 会稳定在 110。如下图
再增加线程和 Timer 配置都只会导致响应时间的增加,TPS 却不会增加,并且无报错 (注:QPS 指每秒请求数,TPS 指每秒处理请求)
我就在想,如果接口 收到的 QPS 远大于他的处理能力,理论上应该会报错,并且处理能力(TPS)下降, 那为什么 TPS 会稳定呢。
我分析了下测试数据 (下图),
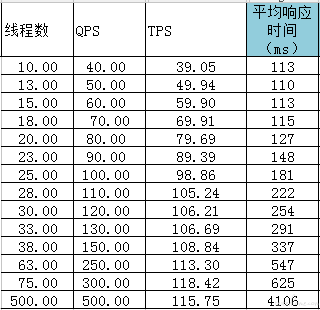
以 10 线程 40QPS 和 75 线程 300QPS 为例,
10 线程时的平均响应时间 为 0.113s,他可以造成 10/0.113=88 的 QPS,但因为 Throughput Timer 配置了 2400(也就是 40QPS),所以他实际 QPS 为 40
75 线程时平均响应时间为 0.625,对应 QPS 为 75/0.625=120,而我设置的 Throughput Timer 是 18000(300QPS),所以 75 线程时,jmeter 根本就没法提供 300QPS
500 线程结果和 75 线程 差不多,虽然 线程和 QPS 配置上去了,但因为响应时间 增加,实际的 QPS 只能达到 120 左右。
所以我最终得出结论是,jmeter 能提供的最大 QPS 只能为接口 TPS , 也就是说,jmeter 不能提供更高的 QPS 来压爆接口
另外,我用 apache 的 AB 也做了同样的测试,结论是一样的。
对于这个结论 我也很吃惊,不知道有没有漏洞,欢迎各位拍脸
那其实还是说明,jmeter 能提供的 QPS 有限嘛
也就是说,jmeter 不能在 服务器只能处理 100 个请求每秒的情况下,提供 200QPS 的 压力
jmeter 这个锅不背
 ,我设置的 QPS 他根本达不到
,我设置的 QPS 他根本达不到
哥,从你回答的 jmeter 和 loadrunner 这两个问题来看,你是不是离开一线时间太长了???
对,是想测拐点, 4 核 E5 16G 的压测服务器 没有什么压力。我的结论是 QPS 瓶颈是 jmeter 自己的,他因为要等待 线程返回 再进行下一次请求,所以你线程设置的再高没用,只有第一次请求能达到 那么多并发。 时间长 了 QPS 就达不到了
你碰到的这个问题,具体分析,如果是你服务器端的连接数有限,导致的 QPS 上不去,你就是再多的并发用户,也进不去真正的队列
当你的连接数够大的时候,你的并发用户才能真正的进行排队,然后对你的服务器才有真实的压力
让我想起来最近面试,碰到的一个研发部门总监,问我 loadrunner 的参数化怎么做的,我还心想问这个干什么,这不是很基本的问题嘛
后来才知道,他的使用经验在 2000 年的时候。
公司面试流程还是很重要的,如果脱离太久,就不要问那种问题了
从题主的答案和推理逻辑,以及你的 “这个服气” 里面看出来的,并没有了解到问题的本质,不了了之的 “服气”
嗯嗯
我压测对象是 生产环境的 阿里云服务器(施压服也是阿里云内网),有没有连接数限制 我不清楚,但是 远不至于最大只支持 100 个同时连接
我要找的吞吐量拐点 是 下降的拐点, 上升的拐点 不就是图中的 110 吗
补充一点吧,这个接口 TPS 只有 100 是因为他调用了第三方的接口, 纯前端 接口 TPS 能达到 500~600
分两方面去验证这个问题吧:
1、验证你的业务性能,可以用多台 jmeter 或者其他测试工具去做;
2、验证 jmeter 的压力性能,可以在验证了你的服务能力后,用不同的压力工具去做同类对比,然后再得出结论
阿里云不会帮你优化设置服务的连接数,还是需要你们开发运维去配置的,tomcat 之类的默认线程池连接数都不大,要想提高服务器并发处理能力,连接数是首先要调整的,否则限制住了,你客户端请求再多也上不去,池子就这么大;
你们好像搞错重点了 ,帖子的标题才是我发这个帖子的目的,我要说的是 jmeter 的问题,他提供的 QPS 受限于服务器处理能力,导致 我不能 给 100tps 的接口 施加 200qps 的压力。也就找不到 服务器最大能承受 QPS,即 什么时候开始 服务崩溃,连接超时等。
,帖子的标题才是我发这个帖子的目的,我要说的是 jmeter 的问题,他提供的 QPS 受限于服务器处理能力,导致 我不能 给 100tps 的接口 施加 200qps 的压力。也就找不到 服务器最大能承受 QPS,即 什么时候开始 服务崩溃,连接超时等。
那你需要定制了,现在的压测机制下并发用户请求都是要等待返回后再继续请求,而不是单方面的狂轰滥炸了;自己写一个工具搞吧
我假设 服务器每秒能处理 10000 并发,并且在 10000 并发下 服务一切正常,这个时候你用 jmeter 配置 20000 线程,去压测,我的观点是,jmeter 只能造成 1W QPS, 因而 服务 不会挂。 你配置的线程数 并不是实际造成的并发。不然 按我上面的数据,500 线程 压 100tps 的接口为什么 一个报错都没有
就我觉得。。。。。。。。。。要多看看响应时间,把请求的响应时间打点出来 ,然后根据线程数跟请求书自己再去重新算一遍 tps,争论这些意义不大。
如果你的服务器性能只能处理 110QPS 的请求,那么即使 JMeter 在第一秒发起了 200 个请求,服务器只能处理 110 个,剩下的 90 个会在 Web 服务器的处理队列里面,连接会被挂起,JMeter 也会一直等待这些请求响应,所以 QPS 才会稳定在 110。
而且现在的 Web 服务器这方面都处理得很好,基本不会出现因为并发量高使服务器宕机的情况。
除非请求量特别大特别大,比如双 11 那种量级的。。。
你可以设置一下 tomcat 的maxProcessors-最大处理线程、acceptCount-最大连接数,比如都设置成 1000。
还有,测试的时候监控一下服务器的 CPU、内存、IO,看看瓶颈在哪里。
具体情况还要根据你们的业务类型来具体分析。
1.QPS 指每秒查询数,通常用来记 DB 的性能的。 还是第 1 次看到 QPS=RPS 的说法。我猜,jmeter QPS 这个指标应该还是指 db sql 代码的性能测试吧。jmeter 不熟,只能猜了。
2.主流性能测试工具都是需要等回应的,如果事务返回正确,只有 1 个接口,一般 RPS=TPS,经常用 LR 的一般会看到这结果。
3.RPS!=TPS,猜测一般是客户端发送没有出去,或者看看你单机处理的客户端流量,客户端也是需要做下监控的。
4.从结果来看,如果压测机的流量正常,服务端的处理能力已经达到最大了。如果资源很少,你查一下一些参数设置,有可能是他们的影响。
5.第 4 点排除后,如果你想让他报错,就继续加 vuser 吧,500 一个请求也才 4s,默认超时是 60s。有时虽然没有报错,但不一定代码时间上可以接受。
6.如果你想,压力机 vuser N 多,不等回应,然后分开计算 RPS 和 TPS。 你可以尝试用 python Gevent + scrapy,可以实现发和回的异步事件操作。
- 在服务器能够处理的过来的时候(也就是 RPS 小于接口最大 TPS),RPS=TPS。
- 我的数据应该说明的很清楚了,jmeter 再增加线程 也不能造成更高的 RPS,所以 jmeter 测试不了 RPS>TPS 的情况
- 我帖子的主要目的是说明 jmeter 的这个问题,不是为了说怎样测试服务器性能
- 我自己写了个 python 多线程的脚本,只发请求,不管请求响应。很快 第三方接口 (我压测的接口瓶颈在第三方) 就出现了超时的异常。只不过这个脚本不太好做数据统计。代码如下:
# -*- coding:utf-8 -*-
import threading,time,requests
def post():
url = 'http://***/'
param = {'message':'***','client_acc_code':'***'}
start = time.time()
res = requests.post(url,param)
if res.status_code!=200:
print(threading.current_thread().getName() + ' error : ' + str(res.status_code))
else:
end = time.time()
print(threading.current_thread().getName() + ' : ' + str(end - start))
if __name__=='__main__':
run_time = 60 #执行次数
thread_count = 100 #并发数
for x in range(run_time):
i = 0
while i < thread_count:
i += 1
t = threading.Thread(target=post)
t.start()
同步堵塞,接口响应慢,肯定上不去啊,再怎么者也不会出现 jmeter 就能跑几百
jmeter 的请求方式是同步线程请求,基于这种请求方式,首先线程数不等于并发量,qps 也只取决于服务器的处理速度。
如果想要产生更高的压力的话,应该用异步线程,每秒发起多少次请求,然后就不管了,等下一秒再发起多少请求,这种才是真正的并发。
兄弟你的脚本还不如现成的工具呢,一来 requests 库是同步的,二来 cpython 有 GIL,多线程有点鸡肋,虽然对这种主要耗时在 I/O 的场景影响不大,但以 python 的性能,最终还是达不到 jmeter、gatling、ab、wrk 的效果。
至于 jmeter 是 BIO 的,这个我一直以为是搞性能的人的常识呢……
如果有资源,更高压力可以通过多开实例或增加客户端机器达到,但未必会得到你想要的结果。在服务器或后台服务被压死之前,考虑一下请求根本到不了服务的情况:负载均衡/反代/网关/waf 掐掉连接,netfilter 哈希表用光弃掉 IP 包,请求在 tcp 监听队列、接收队列排队直到超时,连接数限制,文件描述符限制,然后 spring cloud 或 tomcat 各种配置限制……
响应时间增加就是在排队,继续增加压力基本上只能看到计算出的响应时间越来越长,因为队列越来越长,后到的请求排了很久的队,最终看到的错误多半是连接超时或响应超时。
其实不需要真的搞挂什么,只要业务给出这场景能接受的最大响应时间(或 99%,99.9% 之类)是多少,达到这个数的时候就是极限了。之后还有余量那是用来扛突发情况的,对用户来说不管挂不挂都是不可用了,在某些行业慢几毫秒可能已经出事了。
看大佬们的讨论长知识
全部看完了,,,这个还是 jmeter 性能测试的局限性吗?怎么看都不像是 jmeter 的性能测试局限性吧,自己写的工具不也是受限于作为压测机本身的资源限制?服务器的设置限制吗?为何就似乎成了 jmeter 独家赞助的样子了。。。期待新的答疑:)
解释下加精理由,讨论区比较精彩,可以学到不少性能测试的东西。
如果用 jmeter 自定义 java 请求,忽略返回结果,是否可以达到 QPS 持续增加的条件
概念错误
我也遇到同样的问题,jmeter 端的 QPS 在 100 线程时只有 50,希望能发送 200 请求/s 到服务端,到底应该怎么实现呢?
这不能算是局限性,只是对于 jmeter 在请求配置上的限制问题,当设置所有的请求均为 1s 超时时,可以类比实现 tps=线程数的效果,jmeter 默认使用 httpclient4,可以在 HTTPHC4Impl 的 setupRequest() 方法中增加超时时间限制
protected void setupRequest(URL url, HttpRequestBase httpRequest, HTTPSampleResult res)
throws IOException {
HttpParams requestParams = httpRequest.getParams();
...
log.info("add timeout :100ms");
requestParams.setIntParameter(CoreConnectionPNames.SO_TIMEOUT, 1000);
requestParams.setIntParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, 1000);//设置请求均为1000ms超时
/* 下面是jmeter原本的实现,请求超时时间应该是可配置的
int rto = getResponseTimeout();
if (rto > 0){
requestParams.setIntParameter(CoreConnectionPNames.SO_TIMEOUT, rto);
}
int cto = getConnectTimeout();
if (cto > 0){
requestParams.setIntParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, cto);
}*/
学了不少知识
Jmeter 和 LR 都是一样的机制,同步等待返回。所以如果服务器只能有 200TPS,你加再多线程,都是一样的结果。
如果你想要达到超过 200 的效果,你可以设置超时时间,也就是将发送请求之后等待响应这段等待时间缩短,到达超时时间就会报错,放弃等待而发送下一个请求。
我觉得还是要结果导向的,比如楼主所说的 Jmeter 局限性,其实不是重点,44 楼的大神说的比较清楚了,所以现在好奇的知识点是:
1.限制 QPS 的作用是啥?
2.QPS 和 TPS 的对比有什么实际作用?拐点能代表什么东东?
不知道有没有大神解惑~
@fudax @keithmork
推荐一个 go 写的工具https://github.com/tsenart/vegeta,感觉这个工具可以满足楼主需求
概念都没理清楚....如果只是想做断链攻击的话 可以缩小响应时间
如果题主说的 QPS 是每秒请求数,TPS 是每秒交互数。
那就先说下我的看法:如果想得到有效的测试结果,那压力机的 QPS 是不可以大于服务器极限 TPS 的。
举个例子,假如 QPS 比 TPS 大 100,那压力机每秒都会多出 100 个在等待状态的连接对不对?。时间一久,会有多少在等待的连接?先不说服务器,压力机自己就要炸了。
so,这样的压力机只能提供不可控也不稳定的压力,如楼上所问,这样的压测结果意义何在呢?
能提供稳定压力的压力机在不做特殊配置和丢包的情况下,每个线程都是在等待服务器响应结果后才会发下一个请求,这就意味着压力机的 QPS 就是要等于服务器的 TPS 的。
一些评论中的说法,我觉得还是有误导性的。 希望大家可以辩证的看。
涨姿势了~感谢大神耐心回复~
还是有点疑惑,好像每个人对 TPS 的理解都不太一样,难道是术语没有在业界统一么 ,记得以前拿 LR 做性能的时候 TPS 就是每秒事务数,是根据在脚本里添加事务来确定某几个请求算一个事务的(一般来说是一个请求一个事务,此时可以理解 QPS=TPS),但是不知道 TPS 和吞吐量有什么关系,好像用 TPS 的曲线来找拐点和吞吐量是一个意思吧?
,记得以前拿 LR 做性能的时候 TPS 就是每秒事务数,是根据在脚本里添加事务来确定某几个请求算一个事务的(一般来说是一个请求一个事务,此时可以理解 QPS=TPS),但是不知道 TPS 和吞吐量有什么关系,好像用 TPS 的曲线来找拐点和吞吐量是一个意思吧?
另外还是不清楚限流的实际应用场景有哪些,莫非防止服务器报警 ddos 攻击?
你这是知道了服务器 是 120 的 TPS, 那你不知道的时候呢,如果服务器的 TPS 是 1000,我限制 300 有问题吗。 并且 我贴子不就是说明 120TPS 的时候 jmeter 达不到 300RPS 吗? 这不就是 jmeter 作为 BIO 的局限性吗。 我想寻找下降拐点 来判断 服务器最大能承受的 RPS,有问题吗, 120 是 服务器能承受的最大 RPS 吗?
首先你压测出 120 是就是服务器能承受的最大 RPS,再多哪怕一点点,持续下去拐点都会出现,但要等多久就说不好了。(为什么,请看吓我楼上的回复)
你可以用 AIO 或者 NIO 的方式模拟用 120+ 的 rps 去试试,但是用异步请求的客户端,自身的稳定性和压测数据的统计实现起来都是个问题。就算出现拐点了客户端也不知道。
这里 jmeter 作为 BIO 不存在这些问题,通过实时增加并发数就可以测出最大 TPS 和拐点,这也是为什么主流的压测机都是 BIO 的原因
44 楼大神已经说过了 rps>tps 可以通过 jmeter 多实例和分布式来实现,我自己也有测过, 完全不会出现你所推测的压力机自爆压力不稳定的情况。你那么笃定的说 120 就是 服务器能承受的最大 rps 我认为也是没有依据的。后续我自会进行详细的测试
1.44 楼哪句说了 jmeter 多实例和分布式可以做到 rps>tps?
2.RPS>TPS 压力机没炸只有三种可能:要么你测试脚本没做到 RPS 大于 TPS,要么压测时间还不够长,要么服务器先炸了。
3.一般情况下, jmeter 增加线程数测的 TPS 不变的时候,对应的 tps 就是服务器能承受的最大 rps,也就是 120。
另外,欢迎找个公网接口贴测试结果来反驳我的结论
多的我不想解释了也不想反驳了,我自己测过我自然知道。
1.不需要知道什么是 BIO,看过官方文档的就会认为更高的线程能造成更高的压力 (Number of Threads:Number of users to simulate.)
2.我根本没说线程==并发,这是你的误解。只是线程数和并发量一般都成正比,同样可以量化压力,方便你更好理解我才写括号里的。
再抬杠下次我可要收学费了哦。
只要是同步返回的接口,并且要统计响应时间的,任何工具都达不到 “提供更高的 QPS 来压爆接口” 吧;不仅仅是 jmeter。要达到压爆的效果,就和楼主写个死循环,只管发,不管返回呗
哦,你说单实例那确实,不过人家也提供了分布式多台压测解决方案了:)另外如果服务器比较刚后台程序的实现架构也比较合理(比如线程池,连接池,异步处理 mq 的引入等),就算自己写工具,作为单例的压测端来说,也很难压倒服务器,基本也都是要考虑多机分布式压测了吧。
你把概念混乱了, 这就是个典型的接口压力测试. 你举例说明的那个 75 线程计算结果是实际的 TPS, jemter 发起的并发请求就是 300,只是服务接口压力瓶颈在 110 左右,他把所有请求放在队列 (猜测的) 中处理,只要你的断言不设置超时就不会抛出异常.不是 jemter 上限只能发起 110 左右的 request. 不谈响应时间的并发量是耍流氓
一点拙见:
这里有 线程数 TPS 响应时间 QPS 四个概念,
以例子中 10 个线程的数据来说,jemeter 使用 10 个线程向业务发送请求,业务方平均处理平均响应时间为 113 毫秒,那么在第一个 113 毫秒(虽然是平均响应时间,这个地方简化理解,我当每个请求的处理都是 113 毫秒了)jemeter 10 个线程收到第一轮结果后立马再向业务方发送请求。。。 如此 在 1 秒之内 jemeter 的 10 个线程可以发送的请求数大概为 88 个,由于楼主固定了 QPS,告诉 jemeter 你一秒内发 40 个就可以了,所以 TPS 只有 40 个。
jemeter 是利用线程循环使用来发送请求的,基于这点的话 QPS <= TPS。
楼主期望 jemeter 提供高于业务方处理能力的请求数,应该不限制 QPS,而是提高线程数。
比如业务服务现在每秒只能处理 100 个请求,jemeter 使用 100 个线程进行压测,平均响应时间应该就是 1 秒,现在楼主想压爆业务接口制造每秒 200 个请求,直接设置 200 个线程,结果就是有 100 个线程的请求能处理,另外 100 个请求业务方可能就是等待了,从结果看平均响应时间就会降低。
想压爆接口 其实目的是为了看接口能处理多大的请求,而不是已经知道处理的请求数再去做压测,有点本末倒置了。
这时候要看业务服务端能不能满足需求,不满足就要提高处理能力或者新增机器了。
这么简单的一个问题,居然还精华,居然还有这么多人讨论,吃惊
在测试压力的时候应该注意响应时间和成功率
qps 和 tps 有什么对比性吗, 参见上面一位仁兄的答案, 我理解的 qps 一般适用于 db 和 磁盘的性能,对于一般应用, 得出 qps 和 tps 有什么可参考性吗
看评论就像看网易的帖子一样,真不错!
看不下去了,如果题主参加工作不久,发这帖子也能理解;如果已经多年,或者冠上高级的 title 了,只能呵呵了。这个问题还能在这论坛讨论这么久,还能吵起来,说明啥,说明这论坛、论坛会员都还处于初级阶段。遇到这类帖子,管理员应该直接移到新手技术区,竟还放在首页这么久。。。
还好后面有几个明白人啊
单实例 jmeter 不能造成大于服务器处理能力的压力,这就是他的局限性, 这句貌似不太准确吧。 我觉得方法可以是:
- 可以不限制固定 QPS
- 增加线程数,甚至可以设定集合时间点,假设服务器极限 TPS 到 100,你 JMETER 线程数 200 个,同时设置集合点 200 个线程同时发
这样同时发,不就是超过你服务器极限 TPS 了吗,但是服务器 TPS 就这么多呀,TPS 就是这么多了,但是客户端的响应时间肯定很难看。 服务器不一定会挂(说明服务器的保护不错呀),有很多等待的队列,客户端反应就是超时越来越多,错误比例越来越高。
同样如果有监控系统看的,可以从服务端的角度看系统处理时间,在这种情况下,客户端响应时间和服务端的监控的响应时间数据我觉得会有不一样
一般测试测接口不都去测接口的极限 TPS,也就是拐点么?值都测出来了就可以了啊,再去增加所谓的 QPS/RPS,如果服务端优化的够好,多余的请求都会进队列(NSQ)一类的东西进行排队,保证服务器不挂,代价就是响应时间越来越长而已,但是接口的处理能力就在那里了,一秒 110 个,你再怎么加,也只能还是 110/s 的处理能力,对于压力机来讲,最多也就 1s 能收到 110 个返回
如果服务器只能处理 100 个,那么 jmeter 给了 200,但是 tps 也上不去,但是起码你知道了服务器最大处理事务的能力是多大。那么这个时候不管 jmeter 有没有局限性,就算他不受你说的这个局限性限制,那么你给再多的并发量,最终发现的问题都是服务器最大支持的处理能力是多少。
什么是 QPS,什么是 TPS,楼主你真的清楚吗???
我想问下,TPS 有 100, jmeter 配置了 300 个并发线程数,那多的线程数是在 jmeter 这边排队等待发送,还是在压测服务器端排队。
系统资源有限,运行在这个系统上面的资源必然都是有限的,8G 的内存难不成你能消耗掉 9G?
性能问题,先分析请求链路的最下游,逐渐往上推。服务器那边统计的响应时间都没有,怎么得出的结论?
我想请问一下,用来压测的本地机器性能不同,会对压测数据结果造成很大的影响吗?如何来衡量是不是用来压测的本地机器性能不同导致的压测结果不同呢?
在使用压测工具进行压力测试的时候,尤其是 Jmeter、Locust,经常因为本机资源限制,导致性能数据出现偏差,甚至误导,可以使用如下方法进行校验:
1、观察本机各项资源是否达到;
2、对比 Jmeter 的响应时间和服务器端的响应时间,看看偏差是否较大
3、使用 jmeter 分布式,进行压力测试,对比单 Jmter 和多 Jmeter 压测数据
首先我对 TPS、QPS、RPS 这些概念认为都查不多,只是细微之处有些变化来描述一种特定的场景,没必要纠结那个大于哪个,反正都是反映服务器的性能,对于性能测试工具 JMeter 是 BIO 的,也就是同步阻塞,这样做有及其大的优势,同时更加符合人的操作逻辑。不然一整套逻辑接口,后面的接口的数据怎样根据前面已知的条件生成?(之后输入的数据根据已知的条件随机生成才能更加符合人的操作逻辑),数据也能更好的监控。JMeter 的分布式压测产生的背景是一台客户端由于内存、CPU 、网络(主要是内存)的限制造不成更加的压力,因为 JMeter 是基于线程的内存开销较大。
对单个接口来说多线程访问因为代码逻辑是一样的,在不考虑线程占用内存的影响时,TPS 最大值应该是一个固定的值,但是创建一个线程会占用服务器的内存资源,从这方面说 高线程就是等于高压力,基于线程也是 JMeter 的一种局限,因为单台客户端产生的线程有限,所以才有了分布式解决这个问题。
线程会占用服务器内存和 CPU 资源,同时也挤占了程序运行时的资源,所以高并发(大量线程)会造成内存溢出。也会造成 TPS 下降,楼主的那种情况应该是虚拟用户数过低,也就是服务器中运行的线程数不足以把程序运行的空间挤压的很小,造成程序处理速度变慢,又回到上面说的当 JMeter 一个线程发送一个请求没有响应的时候该线程是不会再发送第二个请求的。所以要想出现性能拐点必须增加虚拟用户数量,一方面需要单个客户端增大线程数量,另一方面分布式多个客户端运行。就好了。
最后说说,任何工具都有优点和局限性,有的特性可能在某种角度先是优点从另一种角度看就是局限性。JMeter 作为性能测试工具很好用。
35 楼兄弟的答案 + bio