-
专栏文章 质量保障系统的落地实践 (六) 拓展延伸 - 记一次前后端分离项目 Django 的图片代理 at 2024年06月14日
我估计如果从头实现需要前后端各半天 (乐观一点).
如果用一些好用的工具实现呢?大概是 1 个小时吧。假设需要实现一个如下的文件上传功能需要多少开发量?
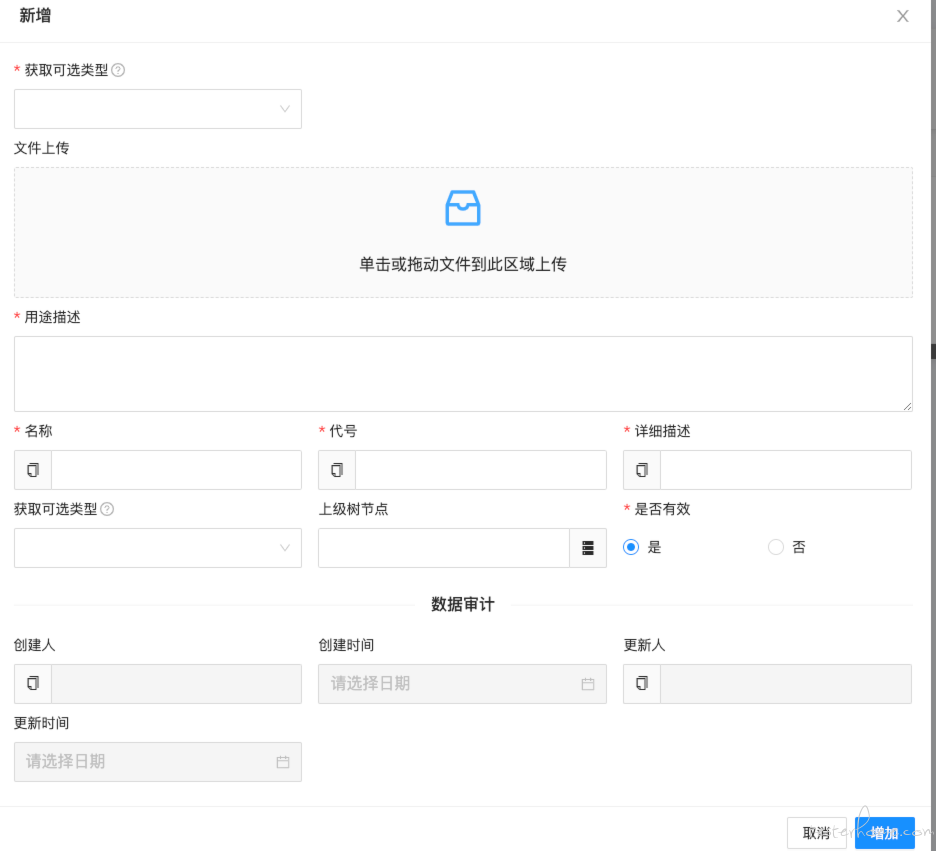
如果用一些好用工具实现,一个 JAVA 类吧:
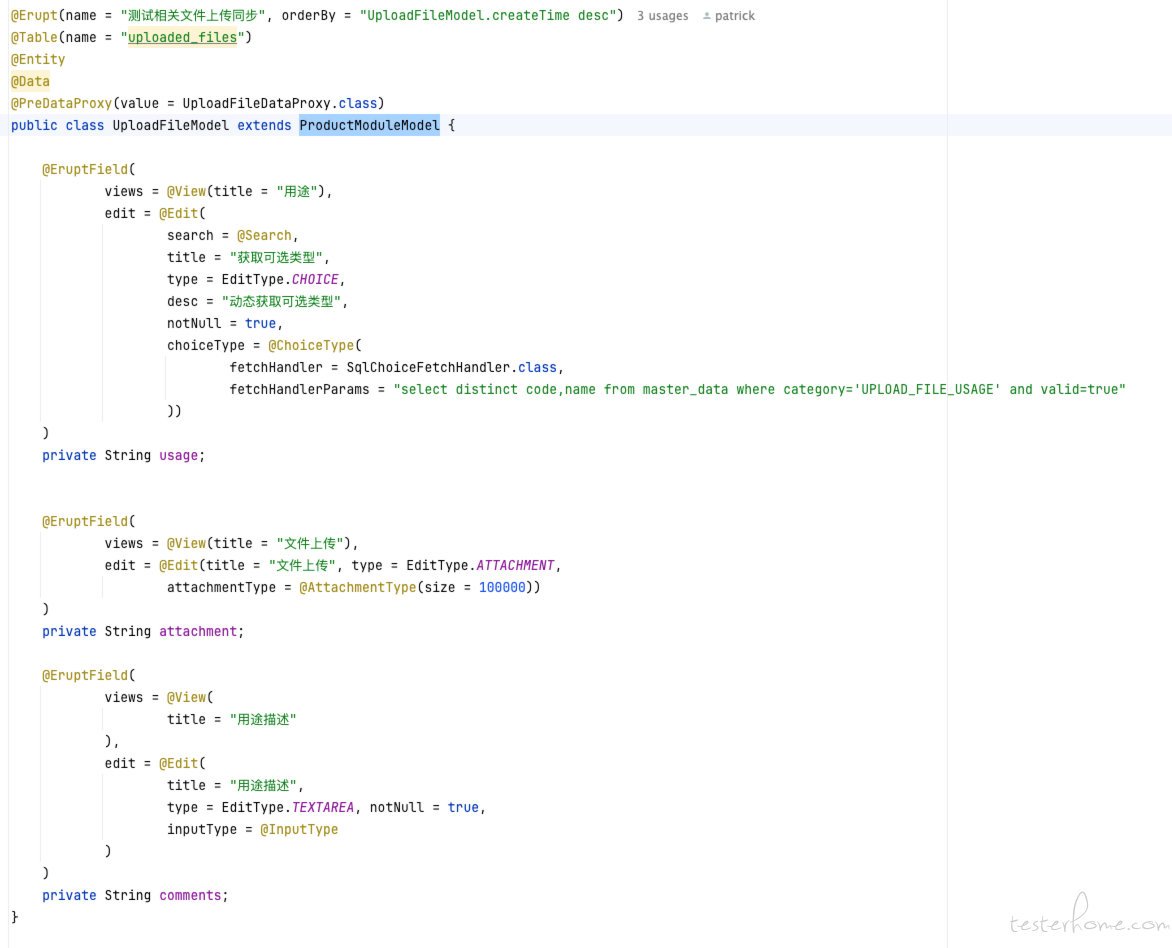
我就是这么实现一个前后端都有的上传功能。 至少个人认为,有些东西确实没有必要什么重零开始,尤其是测试开发相关的东西.
-
既然测试也要求写代码,那干脆让开发兼任测试不就好了吗? at 2024年06月11日
讨论这些没有任何意义的,需要给这种讨论设定一些范围:
- 比如说什么样阶段的产品
- 比如说什么样阶段的公司
- 等等外部其他因素 。。。。。。。。。。。
讨论了很多开发和测试工作的不同,这没有问题的,但是毕竟这些都是人做的工作,工作有些不同,不同的地方人就哪里需要哪些学呗,开发兼任测试不是不行,测试兼任开发也不是不行,就没有不行的。职位要求需要重心不同,这不代表就是完全不能做呀。
目标是降本提效,身兼多职;目标是跑马圈地,那就多找点人。
-
【测试架构师 & 资深测试开发】京东零售-ToB 业务 at 2024年06月11日
价格价格,价格范围
-
数据清洗如何测试? at 2024年06月04日
可以使用精准测试了。问问精准测试怎么做?
-
越迷信技巧越容易失败 at 2024年06月04日
你说的没错的。就是这么个情况。
-
越迷信技巧越容易失败 at 2024年06月03日
谁能给我用一个例子证明,自动化落地和必须与业务强关联这个有必然的因果关系?什么样的业务如果在人员能力,时间,成本没有任何约束的情况下不能做自动化?
-
求助贴 Jmeter 报错 at 2024年05月28日
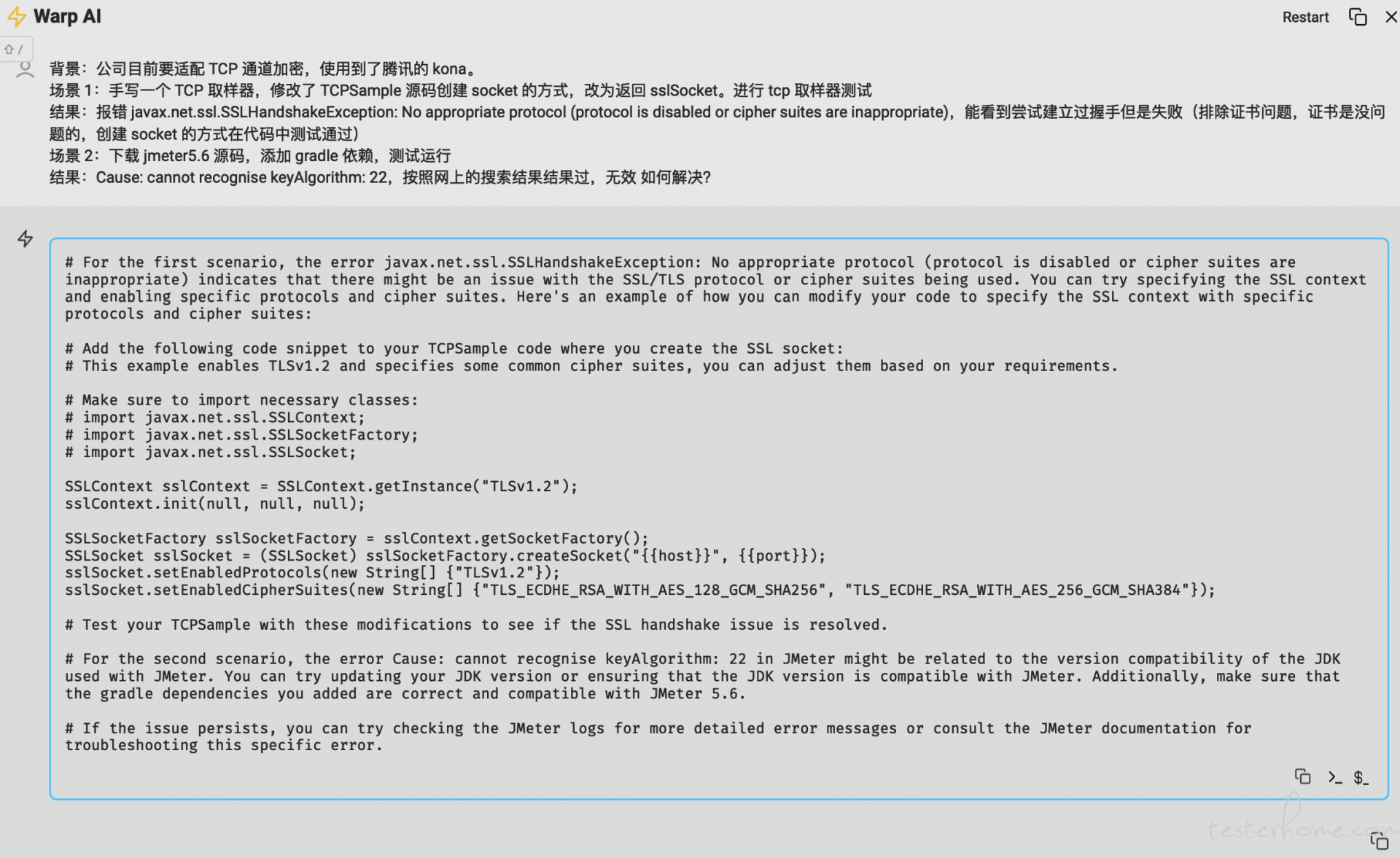
# For the first scenario, the error javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher suites are inappropriate) indicates that there might be an issue with the SSL/TLS protocol or cipher suites being used. You can try specifying the SSL context and enabling specific protocols and cipher suites. Here's an example of how you can modify your code to specify the SSL context with specific protocols and cipher suites: # Add the following code snippet to your TCPSample code where you create the SSL socket: # This example enables TLSv1.2 and specifies some common cipher suites, you can adjust them based on your requirements. # Make sure to import necessary classes: # import javax.net.ssl.SSLContext; # import javax.net.ssl.SSLSocketFactory; # import javax.net.ssl.SSLSocket; SSLContext sslContext = SSLContext.getInstance("TLSv1.2"); sslContext.init(null, null, null); SSLSocketFactory sslSocketFactory = sslContext.getSocketFactory(); SSLSocket sslSocket = (SSLSocket) sslSocketFactory.createSocket("{{host}}", {{port}}); sslSocket.setEnabledProtocols(new String[] {"TLSv1.2"}); sslSocket.setEnabledCipherSuites(new String[] {"TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256", "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"}); # Test your TCPSample with these modifications to see if the SSL handshake issue is resolved. # For the second scenario, the error Cause: cannot recognise keyAlgorithm: 22 in JMeter might be related to the version compatibility of the JDK used with JMeter. You can try updating your JDK version or ensuring that the JDK version is compatible with JMeter. Additionally, make sure that the gradle dependencies you added are correct and compatible with JMeter 5.6. # If the issue persists, you can try checking the JMeter logs for more detailed error messages or consult the JMeter documentation for troubleshooting this specific error. -
- 网页调用上面调用相当于调用 http 请求,所以你要建立一个 API 服务
- python 建立 API 服务非常旁边,flask/fastapi 都可以
- 你遇到了 CORS 问题,直接在 Flask/FASTAPI 里面设置 CORS 策略就可以
- 你不如直接把你的 HTML 文件放到你的测试代码中,使用 Flask/FastAPI 都可以启动 web 服务
-
幂等性(Idempotence)是指一个操作无论执行多少次,其效果都和执行一次是一样的。在分布式系统、网络通信、数据库事务等领域,幂等性是一个重要的概念,因为它可以确保系统的一致性和可靠性。
在你提到的场景中,我们可以这样理解幂等性:
第一次处理没有执行某个操作:这可能是因为操作依赖于某些条件或资源,而这些条件或资源在第一次尝试时并不满足或不可用。例如,在数据库操作中,可能是因为事务冲突或锁竞争导致操作未能执行。
第二次重试又执行某个操作:在第一次操作未能成功执行后,系统可能会自动或手动触发重试机制。如果操作是幂等的,那么即使重试,也不会对系统状态产生不良影响。
常见于有缓存的地方,缓存失效后会重新执行:在很多系统中,为了提高性能,会使用缓存来存储一些数据。当缓存的数据失效(例如,由于数据更新或缓存过期)时,系统需要重新从原始数据源获取数据并更新缓存。如果数据获取和更新操作是幂等的,那么即使在缓存失效后多次触发这些操作,也不会导致数据不一致或重复处理的问题。
幂等性的重要性在于:
- 一致性:确保系统状态不会因为重复的操作而变得不一致。
- 可靠性:在面对网络波动、系统故障等不确定性因素时,幂等性可以保证操作的最终正确执行。
- 简化设计:幂等性简化了错误处理和重试逻辑的设计,因为开发者不需要担心重复操作带来的副作用。
在实际应用中,设计幂等的操作通常涉及到使用唯一事务 ID、检查操作是否已经执行过、确保操作的副作用有限等策略。这样,即使在复杂的系统交互中,也能够保持操作的确定性和可控性。
来自 AI 的回复
-
10 年测试,有没有必要转开发? at 2024年05月22日
- 哪个钱多?
- 做的东西有多少差别?
- 测试和开发的区别在编译器这个领域差别到底在哪里?差别到底有多大?
- 做测试工具算开发吗?
-
pytest 接口测试 - 接口依赖 情况下实现 参数化 的问题和解决过程 at 2024年05月14日
是的,可以这样的,顺手写了一个 pytest 的一些使用,https://testerhome.com/articles/39759, 仅供参考。
-
pytest 接口测试 - 接口依赖 情况下实现 参数化 的问题和解决过程 at 2024年05月14日
对这个问题的间接回答:
为什么一定都要参数化呢?专门写一个有 order id 的,其他错误的用参数化一下不行吗?
为了这个事情,其实花的时间更多了吧,比直接写个测试用例专门测有 order id 的场景。对这个问题的直接回答:
-
@pytest.mark.parametrize需要的是一个 set 的列表作为参数化列表 - 可以使用如下的方式可能会更可读一些:
cases = CaseLoader.load_cases() ## load_cases可以让你的order api在这个里面调用 @user2ize("p1,P2", cases) def test_abc(): test_it()- 也可以使用一些 pytest 执行顺序插件,强制让订单接口执行
-
-
大家有没有兴趣一起搞个开源的平台化的精准测试代码覆盖率平台 at 2024年05月11日
我还是来泼个冷水,很多问题要得到回答:
- JUNIT 到现在多少年了?可能有 20 年了,做单元测试的有多少?不过这个项目其实也维护了这么久了。
- JACOCO 是不是半死不活的?你看看项目历史他有多少年了?能坚持吗?
- 为什么看到的大部分都是 JAVA 的,其他语言很少?难道开发语言只有 JAVA 吗,还有 Javascript,typescript,golang,php,。。。。。。
- 如果精准测试这么好,这么能把问题解决了而且成本也没那么高的话,为什么几十年里面没有一个开源平台在持续做?为什么连云服务国内大厂都没有提供这些服务?或者没有提供好用的服务,为什么连 google,微软,amazon 他们也听说过?(当然可能是我不知道) 那么多开源的东西都是坚持了 10 年以上,为什么这个没有精准测试的知名开源项目?为什么微软什么的宁愿把测试裁员也不让他们来做这种可以变成云产品的东西? 实话是,我对精准测试的效果怀疑的,效果好有很多种原因的,是不是就是主要是精准测试,开发工具的人当然说这个工具好,但是是不是也有越来越多测试会看代码,会分析代码的原因呢?在实际的测试活动种是不是也有了一些改变了?
- 代码能力真的到了这个程度了吗?测试想要解决的问题,真的是架构师,开发想要解决的问题吗?测试也不是说要消灭 Bug,只是尽可能让重大 Bug 没有,不严重的 Bug 尽可能少。就像之前有个帖子说的那个 AI 扫描之类的,如果仔细一看你会发现其实可能 MAVEN 的一些常见错误接触少了,或者有些可能架构设计上的问题都不敢提出或者也难提出被人接受的观点,那么其实做好这个平台的难度是不小的。常见错误见的太少了,代码量不够,常见错误见的会偏少是正常的,但是会不会给自己带来误判,觉得这些东西必须要搞个平台来检测;而不是因为自己对常见错误的经历太少了,结果可能杀鸡用牛刀了
- AI 来了,到底是生成单元测试生成方便一点还是用 AI 扫描方便推理出可能的问题方便一点?还是沿用覆盖率比较这种方式呢?
- 调用链这种,Exception Log 记录这种当然可以收集,但是你说这是精准测试吧,他更多是事后的事情,要做到新需求都要精准我不知道用什么来表达?覆盖率?改动的地方的测试,指出?
当然这种是和大佬学习的好机会,肯定支持。
-
通过 AI/搜索学东西会快很多的 at 2024年05月09日
吐槽一下,要不然您出一个节点选择指南?
-
通过 AI/搜索学东西会快很多的 at 2024年05月09日
问题不是语气,问题是为啥要吐槽这个地址没写的事情?不过感谢你把地址写出来了,然后呢?有人问你梯子,你教人怎么用梯子吗?
-
通过 AI/搜索学东西会快很多的 at 2024年05月09日
我只是自我感叹一下顺便在社区感叹一下. 你也没必要指责我吧。
-
基于 AI 大模型的精准测试分享 at 2024年04月23日
解析出答案中的依赖 groupId 和 artifactId 等关键字段,把解析出的依赖在热点代码中查找,找到了说明大概率引出故障!这种 NoClassDefFoundError 出来,然后不太知道 MAVEN 里面可能有问题,这个基本功其实真的不怎么样,当然你说用大模型能不能解决,肯定可以,用搜索其实也能解决,成本问题。
然后有一点小疑问就是,既然 NoClassDefFoundError 都不太知道可能哪里有问题的,为啥要去搞那些高难度的什么 AST,抽象语法树,直接代码分析,代码级别测试,如果能这么分析,我觉得还不如直接生成单元测试和集成测试来的直接呢,数据反正都能生成的,用例也能覆盖,为啥要绕着弯子去做一样的事情。
-
开源项目核心代码单元测试 100% 覆盖率实战 at 2024年04月23日
其实这个论坛对技术不太感兴趣的,怎么实践也是。这些离一般的测试的实际工作稍微有点远了。
-
jmeter 卡死问题 at 2024年04月21日
那就不要用 JMETER 了。
-
开始对研发的提测质量打分了,分享提测质量评估标准 at 2024年04月15日
看了这个标题时候的感受:
问题是: 研发提测质量导致测试工作量加大,因此公司内部开始推行测试对研发的提测质量打分,与研发的绩效考核相关。
对策是: 给研发提测质量进行打分, 请问这不会加大测试工作吗? 难道研发提测质量的提高只要政策一出就能马上改好吗?在没有改好之前,测试工作量是大了还是少了?看了 测试对开发质量标准的感受:
- 研发文档,具体指什么?这个有过于教条的问题,也很难评估,写一句话说清楚了和写一大堆说不清楚,不是有产品经理有需求文档吗?不是有 Bug 描述吗?不知道这个指的是什么。
- 测试顺利程度?这是什么意思?主流程没有 Block 的 Bug?低级 Bug 不低级根本不重要,只有严重程度高的 Bug 才重要,所以低级 Bug 是什么?
- Release Notes 需要完整准确: 我有点好奇,难道没有 Bug 管理系统吗?修改了 Bug,直接 Bug 就进入 Release Notes 呀
- 是否有自测: 不是和测试顺利程度有相关性吗,测试关系的是结果,是不是否自测已经是手段了,如果质量好,不自测由怎么样?因为人家找到办法了,你管不着的,看结果的。这和表示质量的指标没有一毛钱关系
- 是否有已知问题: 就算知道了,也不告诉你,你知道吗?也不是质量的指标吧
- 变改变测: 这不是常态吗?有 Bug 马上修改,和方便就发布了,马上验证,否则 CI 要来做什么?我很难理解这个的出发点是什么?变改变测很明显好处是开发测试流程缩短了,不太好的是,确实有时可能会改错,或者影响一下其他,但是我觉得没有上集成环境/回归环境,变改变测是常态呀,要不然发明哪些 CI 我不知道为了什么?
当然一笑而过,只求大家都不要太为难相互,出问题之后可能有很多原因的,太宽泛的提测质量不好一句话很难说清楚,没有具体的东西的话,之后怎么评估提测质量好了呢?工作不要搞得像仇家一样。
-
广招内容输出英雄帖 at 2024年03月12日
支持
-
代码手术刀 - 自定义你的代码重构工具 at 2024年02月09日
做完这些应为不太确定是不是完全正确,然后需要测试再全量回归一下,有时想想测试确实痛苦,这本来就是不存在的事情。及不重要又不紧急的事情,最后被推到了又紧张,又紧急的事情。关键是万一问题还要背锅,没出问题都是应该的。测试开发何苦折腾测试呢。 就这个事情,和代码重构真的不在一个维度上的,代码根本就没有重构, 重构什么了?那个 Bean 还是那个 Bean,只不过是编译的时候把 GET/SET 方法给自己生成了而已,对代码没有做任何形式的重构。
提高效率是好事,但是提高到代码重构工具,这肯定上不合适的,这肯定说不上重构,哪怕一点都说不上。
用@Data和用 IDE 直接生成 GET/SET 没大区别,就是看着烦了点,但是 Lombak 说不定还存在点坑,然后不只不觉的就引入了风险。
一切都是矛盾呀,一面说管控变更,一面一动手就用代码改代码了, 代码改代码风险并不会小。
-
为什么放弃精准测试平台? at 2024年02月06日
业务体量还不够复杂,这个确实,不过呢也不算太简单,同时业务体量这个东西很有迷惑性,是指功能多?还是指用户量多。如果用户量多,其实呢不一定用例多。业务复杂,使用人少,也可能用例很多,所以这个光一句业务体量不够复杂本身就不够清晰.
公司内某业务回归几万条用例的问题,需要精准测试,但是呢,重复的多少?没人愿意去重新搞搞清楚的可能也是有的?
另外为什么要全量回归呢?不是拆分了微服务了吗,不是敏捷小步快走吗?那么如果还是动一下要几万个 Case,那么微服务的意义在哪里,敏捷的意义在哪里,是不是先反思一下领域拆分问题?如果精准到几千条,那我想问下,如果直接通过优先级是 P1-P2 的过滤一下筛选,几万条能过滤到几千条吗?然后这个几万条用例,一条用例的定义是什么?是一个步骤还是一个场景?
个人觉得更全面的了解一下实际情况对我做决定很有帮助,所以多问几个问题。先谢过!
-
为什么放弃精准测试平台? at 2024年02月06日
我觉得这些都没有问题,我只是考虑我自己实际的情况分析,同时想看看如果要做怎么做成本更低,
- 比如你说 OpenTracingAPI,Skywalking 只是一个例子,事实上如果一个公司多语言的话,我第一反应链路 Trace 会比从代码 AST 解析出来分析要方便,否则你每个语言来一套?
- 而追踪接口变化,我第一反应也是觉得通过 API Spec 文件差异更容易实现,而我们确实也是多语言也使用 API Spec 先行这种方式进行开发,所以我觉得没有必要去做 AST 方式或者 Parse 代码方式去实现;
- 至于内部调用链和 Opentracing API 个人理解没什么冲突,如果 Tracing ID 一直传下去,直到返回,远程和内部调用没多大区别,至于是不是 JAVA 微服务,问题是我看到的例子大部分 code instrumetation 都是用 JVM 做例子,JACOCO 做例子的,如果是 JAVA 微服务,反而我觉得可能成本相对低一些,毕竟很多人都做了这个,至于其他语言的,我不确定成本会到哪里
- 另外就是关于精准的判断遗漏,工程师还是会加入,那么你说为了防止遗漏,我觉得没问题,只是我们可能还没到这个程度,公司小选择相信人,毕竟最终你还是要工程师做决定,那就考虑省去这部分平台建设
- 代码调用链路分析这个事儿,本身并不复杂,就是个会者不难难者不会的问题, 这个肯定的,几乎所有的问题都这样
-
null at 2024年02月03日
好多对上英文你就不惊讶了,比如造数工厂, data factory,就这么个事情。