-
大家所在的公司都在如何进行 AI 提效呐? at 2025年12月22日
看了最近的 mtsc,好像大家分享的集中方向在用例生成和 app 测试执行方面偏多。
我们稍微有点国企背景,最近领导兴致来了,大手一挥: 那个谁谁谁,你去调研看看,别人都是咋生成的用例,用啥模型,用什么开源软件,多久能搞定。。。
然后我 .... 好的领导....
.... 好的领导....
-
对于精准测试,有人或者团队做过并成功落地的吗? at 2023年09月13日
目前正在推进中,只打算做到覆盖率的增量报告展示,用来做测试辅助。 后面的调用链分析和用例关联不打算搞。
-
会用 python 写接口,但是学不会用框架,记不住,大家有什么更好的学习办法吗,感谢回答,谢谢 UU 们了 at 2023年08月23日
web 开发框架吗? 找本教程跟着搭个系统运行起来就差不多了
自觉这个东西不需要完全记住,有个大概的轮廓就可以,然后遇到具体问题百度就行 -
使用 ASM 通过代码反推接口文档 at 2023年08月23日
有两个问题想请教下。
- 能不能直接解析源码,如果可以的话,还省却了编译 class 文件这一步
- 如果方法的请求参数定义在依赖的其他工程里面,能不能解析出来。
-
让 ChatGPT 写测试用例 at 2023年02月10日
还能上下文关联,有点厉害
-
不是哦,端口和地址都换过了,还是一样报错。
不过看报错提示是地址占用,如果是端口占用应该会提示占用的进程啥的这些信息。 -
关于实现安卓端弱网工具的一些构想 at 2022年11月28日
博主加油,期待尽快开源啊

-
从测试角度看现实问题 at 2022年08月17日
是的,这种问题的难点,可能就在生产条件的模拟。 不下雨的时候检查,可能没那么有用。 雨天检查,是不是还得考虑雨下多大,积水有多少,踩上去的是个胖子还是瘦子?
如果按照不下雨天的检查结果来保障,那么标准就相当于向上拔高,质量保障没有达到 “刚刚好” 的这个限度,成本会有损失。 -
大家有什么好的办法确定回归范围 at 2022年05月30日
同意一楼的回复,
我们这边把回归范围包含两部分,本身修改部分 + 受影响部分。
黑盒测试,确实只能通过需求文档和设计文档评估范围,但这个不太准确,时不时会有遗漏。
目前精准测试还在构建中,调用链路分析没搞定之前,貌似也起不了啥作用。如果人为去 code diff 代码行,除了对测试人员代码能力要求较高以外,花费的时间估计也不少。
可能折中一下会好一些,还是以黑盒评估为主。在代码提交以后,git diff 获取修改代码的文件,根据文件判断大致涉及功能,然后反馈黑盒,确认是否有测试范围遗漏。 不过这个方法还没实践过,楼主可以参考下 -
快毕业 3 年了,很迷茫,求大佬们指点下 at 2022年05月19日
不管啥时候,选择权掌握在自己手上总是没错的,多看看机会,跳出舒适区。说个血的教训, 我去年拿了涨幅接近 70% 的 offer,结果公司说能特批调整下,然后就没走,现在肠子都悔青了。
-
allure 怎么生成简单的聚合报告?? at 2022年05月11日
allure 本身就支持生成报告,最后的结果是 html 格式的。 一般生成报告都是集中存放,然后启动一个 httpserver,然后其他人只要拿到测试报告的地址,可以通过浏览器直接访问测试报告。
报告的地址可以在消息通知的时候推送出去,比如钉钉,企业微信,邮件等。 我们目前就是这么干的,很方便。
-
请教各位大佬一些关于 sql 层性能保障的问题 at 2022年04月12日
sql1 对应 index1, sql2 对应 index2,本来是没有问题的。
不过可能会出现一种情况就是 index1 修改以后,sql1 查询变快了,不过 sql2 查询 不走原来的 index2 索引,会走 index1 索引,导致 sql2 变慢。 -
请教各位大佬一些关于 sql 层性能保障的问题 at 2022年04月11日
是的,这就是当前的典型场景之一
-
请教各位大佬一些关于 sql 层性能保障的问题 at 2022年04月11日
服务层的性能测试我们已经在做了,而且这块如果有风险,线上就可以进行扩容等操作进行处理。
mysql 这块,就没法线上扩容,所以导致出现问题比较棘手 -
测试开发到底应该干点啥 at 2022年03月22日
说下我的理解哈
从职业发展来讲,测试开发可以干自动化测试,效能工具或平台开发,或者是专项测试及相关工具。
其实对你来说,这个可能是一次比较好的机会。尤其是你的 leader 没有什么明确思路的时候,你发光的机会就来了。先跟你 leader 对齐下目标,然后梳理思路,确定实现过程,最后就周期性跟他对齐结果就行了。
对齐目标类似就跟做规划一样,可以从 3 个角度去处理。1.你们所在部门的岗位职责。 2.你们部分承接的上级部门的 OKR 是啥?3.结合历史分析,比如去年你们哪里做的不够好,外部评价不够? 就从这些角度跟你老大讨论下,看看你们要大概做成什么样子,对你的期望是啥?
梳理思路就是讨论下实现过程怎么搞,开源工具集成还是自研工具?分几个阶段做,里程碑怎么设置?到时候做完大概怎么推动落地等等,然后就是搞一搞跟 leader 同步下进度。如果搞得不错,指不定还能拉更多资源,你就升级当 leader 了。 -
压测服务达到瓶颈以后,继续增加并发用户数,并发请求不再增加吗? at 2021年11月25日 尴尬了,补齐了基础知识的盲区
-
压测服务达到瓶颈以后,继续增加并发用户数,并发请求不再增加吗? at 2021年11月25日
好的,多谢大佬
-
压测服务达到瓶颈以后,继续增加并发用户数,并发请求不再增加吗? at 2021年11月25日
嗯,在 200 的用户的时候已经到达瓶颈了。 我的意思是继续增加并发用户数,看到压力机的网络上传速度没有增加。
我理解压力机的加压跟服务端的能力是无关的,继续加压应该会出现发送流量一直上涨。比如下图里面,300 用户的时候,流量几乎没怎么动。 电脑管家的流量监控显示的上传流量也跟 200 的时候差不多。
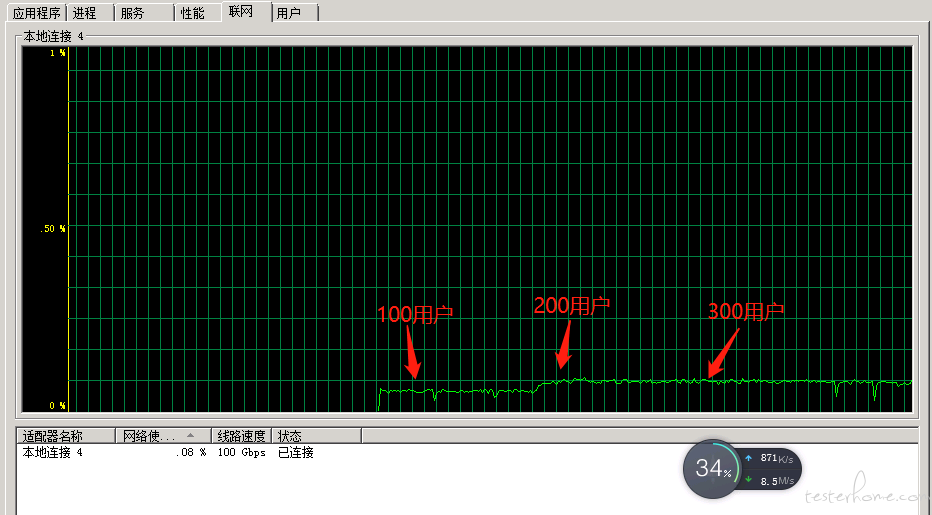
-
求数据结构 at 2021年09月09日
def my_function(n): if n==1: return 1 result = my_function(n-1)*n*(2*n-1) return result用递归计算了下组合数,计算结果跟你的没对上。
-
求数据结构 at 2021年09月08日
噗~~,看来我算错了,算了 11w+。
不过,理论上我觉得穷举所有组合其实不太可能。 等到你有 30 个节点以后,不得跑个好几年。 你做这个事情的具体业务场景是啥?
-
求数据结构 at 2021年09月08日
@ 杨漫步 5 个节点的时候,有多少种组合? 我验证下自己的计算结果
-
求数据结构 at 2021年09月08日
感觉有点类似括号嵌套的问题
-
精准测试是怎么把测试用例和代码关联起来的呢? at 2021年08月06日
流程性、依赖性的自动测试需要 MBT 来配合实施,也就是业务流程建模,你可以简单的理解为把每个功能点作为一个节点,流程用有向图连起来,构造、画图用 proxy 挂 mock-server 录制就可以实现基本的画图了,后续根据实际业务稍加修改就行,然后每个节点做一下业务功能标注和描述,推荐使用 canvas/svg,之前一个小伙伴用 graghviz,卡在图的编辑上很久,而且也比较重了;
这个把业务点用有向图串联起来,现在运维的基础设施上了 skywalking 以后,就感觉很好做了,直接把数据迁移或者爬取下来就可以,而且调用链路非常清晰。
-
精准测试是怎么把测试用例和代码关联起来的呢? at 2021年08月06日
还有只是反推到接口级别的,通过 ASM 分析(通俗点说,有点类似于平时 idea 里的 find usage 倒推调用位置,一直倒推到 controller 层)+ 运行时数据采集(比如通过反射来调用的,就只能用这种了),反推某次代码改动影响到哪些接口,然后执行这些接口相关的接口测试用例。客户端类型的话把接口改为界面(activity/fragment/view/url),也可以同理推断
非常赞同上面这个思路,我们现在的精准测试就正准备尝试这种方法。
之前去 QEcon 大会,有个工商银行的分享。提出了两个思路,一个是按照时间段,另外一个是用例打标(这个不懂怎么实现),感觉可操作性性都不强。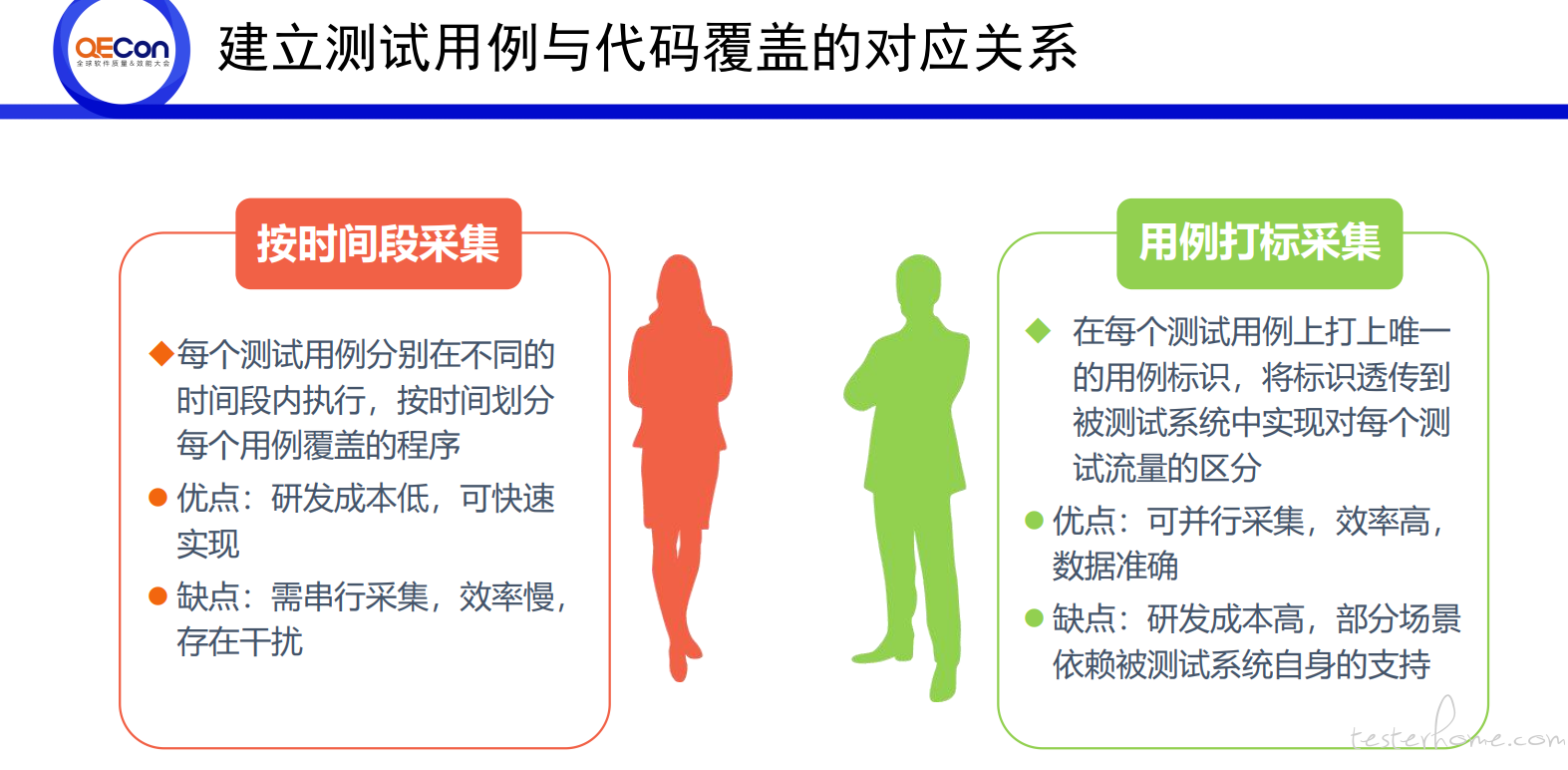
-
如何培养结构化思维? at 2021年06月22日
旁边的人就是最好的老师,开会的时候,尝试做个会议纪要,然后没事的时候拿出来复盘下,从别人的结论中反推考虑问题的思路。