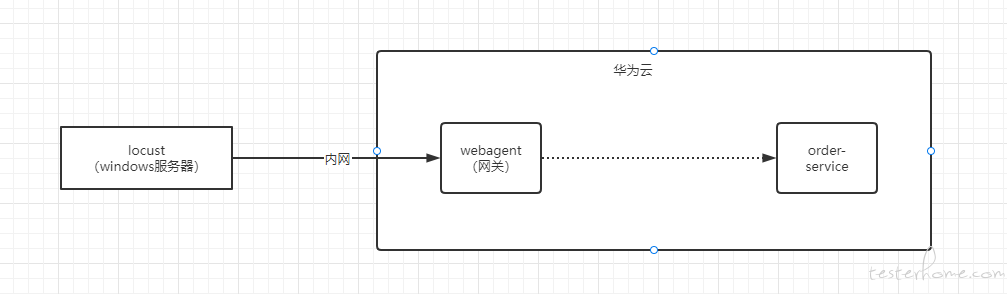
小弟负责一个功能的压测,压测简图如上。
测试过程是,通过 locust 工具,制造大量请求,经过外网网关,然后对 order-service 施加压力,目的是想得到订单查询的性能基准。
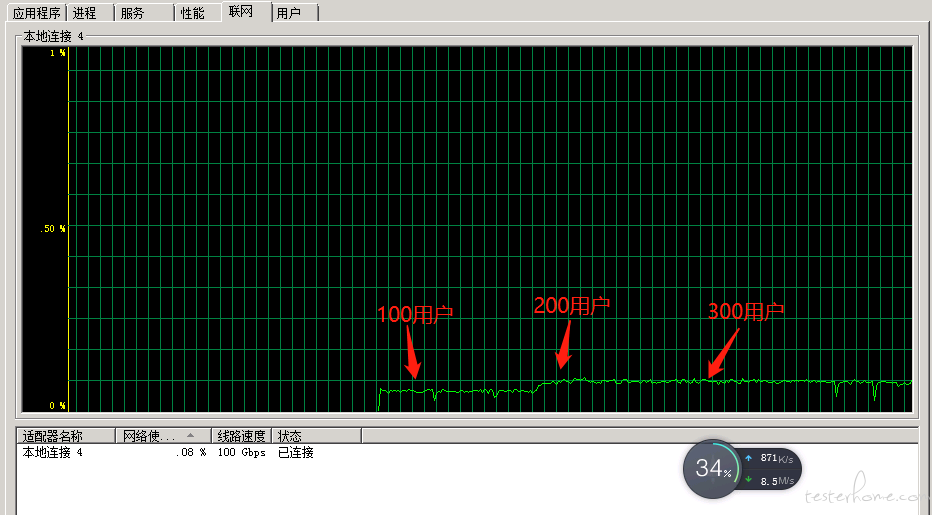
压测结果如下图,当用户达到节点 1 应该就是瓶颈了。
关键是,当用户上升到节点 2 的时候,本来预期压力机应该会发出请求量进一步增加,然后系统出现大量报错。但是用流量统计查看了压力端的网络流入和流出,发现并没有明显的增加。
所以想问下大家,为什么增加用户数,发出的请求却不变呢  ? 多谢
? 多谢
ps: locust 压力机也在华为服务器,跟运维确认了,没有网络限制。

流量监控情况:
因为响应时间增加了啊,看你上图应该是后台服务的负载处理能力达到上限了
嗯,在 200 的用户的时候已经到达瓶颈了。 我的意思是继续增加并发用户数,看到压力机的网络上传速度没有增加。
我理解压力机的加压跟服务端的能力是无关的,继续加压应该会出现发送流量一直上涨。
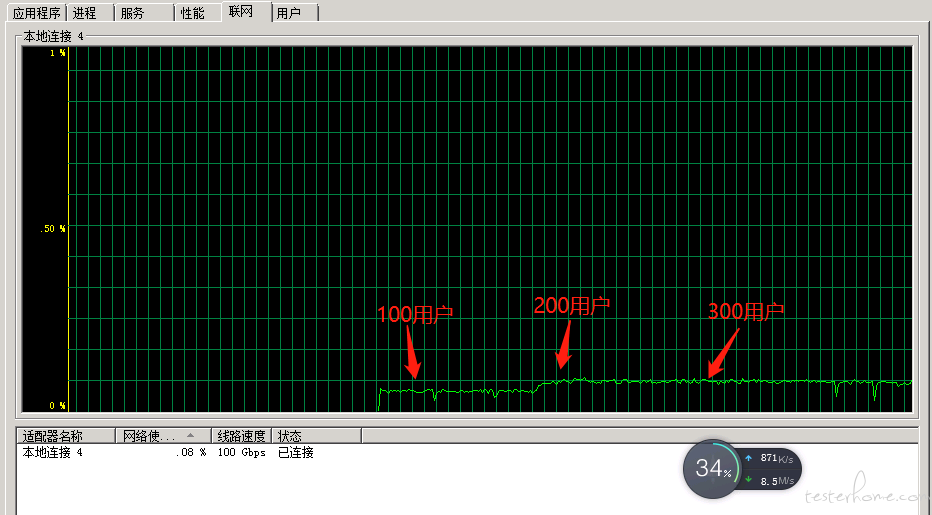
比如下图里面,300 用户的时候,流量几乎没怎么动。 电脑管家的流量监控显示的上传流量也跟 200 的时候差不多。
我理解的是 tps 饱和了,说明服务器只能处理这么多请求,再往上加压力就开始排队了然后触发超时
因为实际上压测软件里每个虚拟用户,实际都是 发送请求 - 等待返回 - 发送下一个请求 - 等待返回 这样的方式运行的。
当你从 200 增加到 300 时,虽然虚拟用户数量增加了 100 个,但因为服务器 TPS 已经达到瓶颈,所以这增加的用户数实际都在服务端的请求处理队列里等着,变成了响应时间。
举个例子,商场购物,结账只有 5 个通道(类比服务端的 TPS 是一个相对固定的值),就算你多一倍的人排队(增加压测工具的并发用户数),也只是增加了排队时间(表现出来就是响应时间增加),并不会让这 5 个通道的处理速度上升(TPS 不会上升),也不会让能结账完出商场的人流量增加(网卡流量上升)。
当你继续增大压力,压力达到服务端队列也撑满,新请求不是进队列而是直接被拒绝的时候,才会出现你提到的 “系统错误不断增加” 这种情况。
这个队列在 Java 常见的服务端架构里,是由 tomcat 负责的,有兴趣可以看看这篇文章:https://segmentfault.com/a/1190000023657729 里面关于线程池的说明
“我理解压力机的加压跟服务端的能力是无关的,继续加压应该会出现发送流量一直上涨”
这个理解是错误的,同一个线程或者说虚拟用户,发请求不是一直发的,要等服务端返回才会继续发

 尴尬了,补齐了基础知识的盲区
尴尬了,补齐了基础知识的盲区在 200 的用户的时候已经到达瓶颈了,服务器处理不过来啦!你可以在 linux 装一个 tcpdump 来看看请求是否到服务器等
节点 1 后再增加并发,qps 仍然增加,说明节点 1 的瓶颈不是服务端瓶颈,可能是并发太少或者发压机瓶颈导致 qps 上不去
节点 2 后再增加并发,qps 不增加或者反而降低说明有可能是服务端瓶颈,还要结合响应时间、资源情况、服务 log 去排查原因
qps 上不去的原因是多种多样的,要结合压测服务的链路配置等去调整,并没有特定的规律,压测过程中流量 qps 只是其中一个指标,要结合服务器资源、数据库资源、网关等链路的每个点去看对应的指标情况,这样你才能分析出 qps 为什么会出现这样的曲线