Android 开发基础 关于实现安卓端弱网工具的一些构想
关于实现安卓端弱网工具的一些构想
一、前言
随着 WeTest 的另一测试工具 QNET 也开始暂停免费试用,我开始着手它的替代品的开发。目前已完成部分基础工作,在过程中收获了很多知识,下面我将结合自己的经验介绍如何实现一个安卓端弱网工具。
二、主流方案解析
我先放上 QNET 产品文档中所介绍的主流弱网测试方案之一,结合此方案给大家介绍 QNET 到底有何玄机。以下资料均来自QNET 官网文档
1、通过 Android 设备连接到 PC 上进行弱网络测试,比如 Fiddler,Charles,NET-Simulator 等。基本 思路是在 PC 上装一个 Fiddler 网络抓包工具,然后再将 Android 设备的网络代理到 PC 上,通过在 PC 上的 Fiddler 在设置延时来进行弱网络模拟。
2、在专有服务器上构建弱网络 Wi-Fi,移动设备连接该 Wi-Fi 进行弱网络测试,相关的技术方案有 Facebook 的 ATC 和腾讯的 WeTest-WiFi。
第一种方案使用了我们熟知的抓包工具,其技术本质是代理技术,作为中间人可以延迟数据包的转发,这很合理。代理分为四层代理(传输层),它能直接与 TCP 层交互,还有一种是七层代理(应用层),我们所使用的抓包工具一般都属于这种,它能转发 http 包,最后一种是 socks5 代理,他的原理是同时维护和客户端与服务端的两条连接,自己作为传话人转发信息。可以看出代理只工作在传输层之上,并不能处理网络层的包,例如 ICMP 包,即大家所熟知的 PING 命令所用的包。
第二种方案是在服务器上搭建 wifi,目前主流是通过 Linux 操作系统中的流量控制器 TC(Traffic Control)用于 Linux 内核的流量控制,主要是通过在输出端口处建立一个队列来实现流量控制。
QNET 对它们的评价如下。
(1)需要额外的 PC 或者服务器,弱网环境构建成本高;
(2)需要安装、部署额外的工具,并且弱网络环境需要在 PC 上或者 Web 上进行配置,使用成本高;
(3)弱网络环境功能并不完善,比如 Fiddler 不支持丢包、抖动等弱网环境。
其中第一和第二点其实表达的意思都一样,它们针对了以上两个方案都存在的问题,就是需要额外的设备才能实现弱网,而 QNET 能做到一个 App 就能实现。
第三点针对的就是第一个方案的问题了:不能控制网络层数据包的转发。
三、VPN 与代理
首先我们先了解下 VPN 和代理,这两个技术所实现的功能及使用目的是非常相似的。它们运作的方式都是居于用户和目标网络的中间,中转网络请求,同时也能隐藏真实 ip 地址,并基于自身所在 ip 地址对目标网络进行访问。除了匿名访问,我们还可以通过它们进行"翻墙"。
虽然功能相似,但它们的底层实现却不太一样。
原文:https://yuerblog.cc/2017/01/03/how-vpn-works-and-how-to-setup-pptp/
vpn:英文全称是 “Virtual Private Network”,翻译过来就是 “虚拟专用网络”。vpn 通常拿来做 2 个事情,一个是可以让世界上任意 2 台机器进入一个虚拟的局域网中(当然这个局域网的数据通讯是加密的,很安全,用起来和一个家庭局域网没有区别),一个是可以用来翻墙。
vpn 比 ss 更加底层,它通过操作系统的接口直接虚拟出一张网卡,后续整个操作系统的网络通讯都将通过这张虚拟的网卡进行收发。这和任何一个代理的实现思路都差不多,应用层并不知道网卡是虚拟的,这样 vpn 虚拟网卡将以中间人的身份对数据进行加工,从而实现各种神奇的效果。具体来说,vpn 是通过编写一套网卡驱动并注册到操作系统实现的虚拟网卡,这样数据只要经过网卡收发就可以进行拦截处理。
一句话,vpn 在 IP 层工作,而 ss 在 TCP 层工作。
从上可以看出,vpn 可以拦截并处理网络层的包,这是代理并不能做到的,除了增加了对 ICMP 包的控制外,这对于实现模拟 TCP 的丢包也至关重要,因为众所周知 TCP 不可能丢包,所以使用代理并不能完美的模仿 TCP 在弱网环境下,TCP 的一些特性:例如拥塞避免,超时重传,滑动窗口。
但这也对于开发工作来说是个挑战,因为接收到的是 IP 包,意味着要自己去实现 TCP 通信流程,从三次握手到四次挥手,不再纸上谈兵。
四、VpnService
在 android API 14(即 android 4)中,添加了一个 VpnService 类,通过实现这个类可以在 Android 中实现一个内置 VPN。
文档:https://www.apiref.com/android-zh/android/net/VpnService.html
VpnService 是应用程序扩展和构建自己的 VPN 解决方案的基类。 通常,它会创建一个虚拟网络接口,配置地址和路由规则,并将文件描述符返回给应用程序。 从描述符读取的每一个信息都会检索发送到接口的传出数据包。 每次写入描述符都会像接收到的接口一样注入传入的数据包。 该接口在 Internet 协议(IP)上运行,因此数据包始终以 IP 标头开始。 然后,应用程序通过隧道处理和与远程服务器交换数据包来完成 VPN 连接。
关于 VpnService 的使用,我参考了以下开源项目:
创建后能得到一个ParcelFileDescriptor对象,可以通过读操作获取需要转发的 ip 数据包,通过写操作将重新分装好的 ip 数据包发给客户端。
五、结构设计
为了实现延迟、丢包、限流等效果,需要设计多个线程和数据结构相配合,在不影响正常通信的情况下达到效果。
1、整体结构
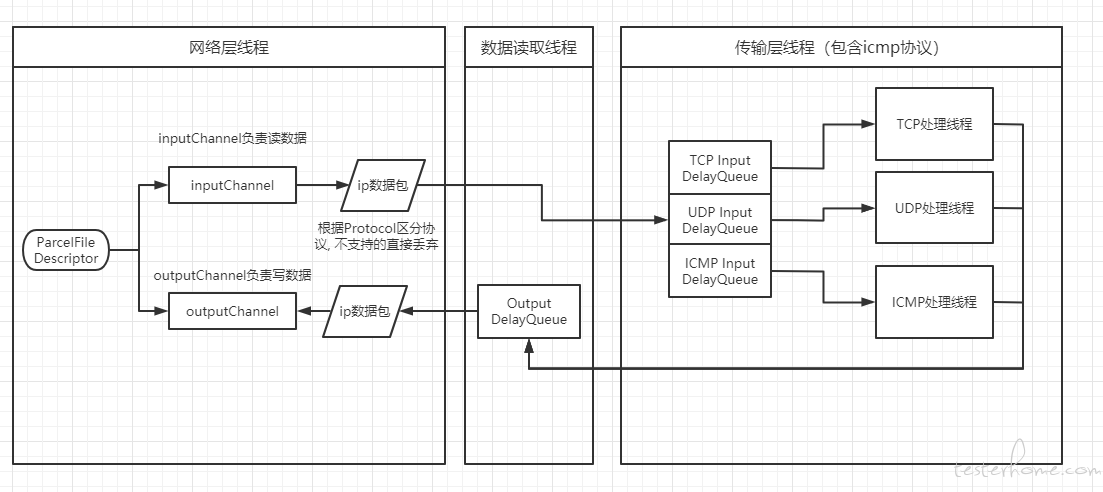
首先由虚拟网卡的文件描述符转化为一个读和一个写 IO,但因为 java 中 FileDescriptor 不支持 NIO,只能阻塞式读取。其中 InputStream 进行读操作可以获取客户端发送的 IP 数据包,向 OutputStream 中写入数据可以向客户端发送数据。
获取数据后,将其从 buffer*填充到 ipv4 包头中,获取到 Protocol 后,再进一步填充到 TCP/UDP/ICMP 包头* 中,若不是以上三种,则直接丢弃。
最终将数据包放入对应 DelayQueue 中,各个协议的线程通过读取对应 DelayQueue 获取数据并处理,用以模拟上行延迟。【注:DelayQueue 是 java 中的延迟队列,将数据放入时可以指定延时,经过延时后才能从另一端取出,常用于定时任务。】
对应线程处理完成后,将回包放入 OutputDelayQueue 中,一个常驻的线程循环读取 OutputDelayQueue 中的数据后发送给客户端,用于模拟下行延迟。
2、TCP 处理线程
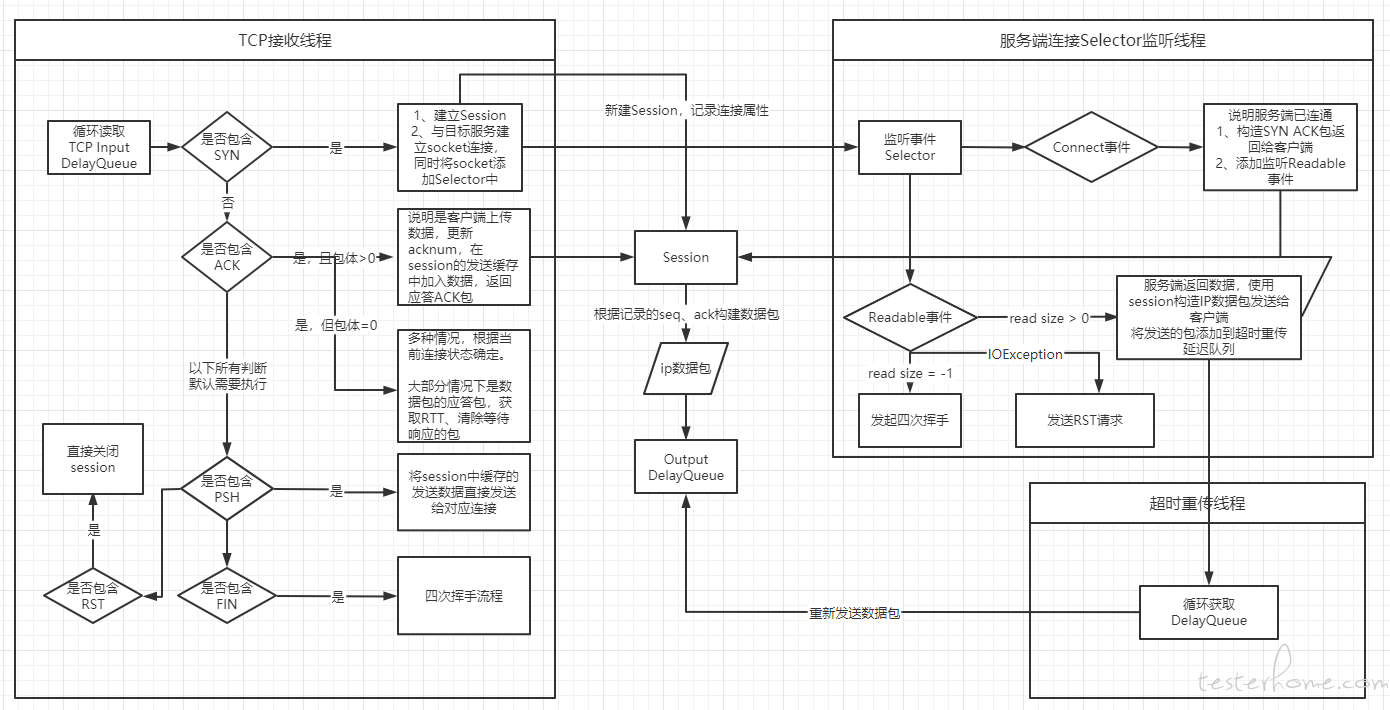
TCP 数据的处理是整个系统中最复杂的,图中限于篇幅只简单列举大概流程,可结合后续介绍理解完整系统。
其关键点在于收到 SYN 包后,维护一个Session 对象用于处理不同连接,首先,同一连接的ip 数据包的 identification需要是连续的,其次,tcp 包中sequenceNumber和acknowledgementNumber需要根据具体情况变化,简单列举以下场景:
1、在收到 SYN 包后,记录其携带的 sequenceNumber + 1 为自身的 acknowledgementNumber,自己生成一个 sequenceNumber,构造 SYN ACK 包后发送给客户端。
2、在 ESTABLISHED 阶段,收到带数据的 TCP 包,检查收到包的 sequenceNumber 是否等于自身 acknowledgementNumber,是的话则更新自身 acknowledgementNumber=收到包的(sequenceNumber + payload length),如果不是则代表丢包,不更新自身 acknowledgementNumber,构造 ACK 包后发送给客户端。
3、在 ESTABLISHED 阶段,发送带数据的 TCP 包,自身(sequenceNumber += payload length),构造 ACK PSH 包发送给客户端。
4、在 ESTABLISHED 阶段,收到不带数据的 TCP 包,为ACK 包,判断其 acknowledgementNumber 来判断上一步自己发送的数据是否成功被接收,简单判断方法为收到包的 acknowledgementNumber==上一步(sequenceNumber += payload length)即为成功 。
5、其余四次挥手阶段,服务端可以是发起端,也可以是被发起端,标记自身状态去应对不同报文,同时改变状态。
session中除了上面提到的三个成员变量,还有以下需要维护:
- connectionStatus:连接状态,例如SYN_RECEIVED、ESTABLISHED、FIN_WAIT_1等,这些状态用于判断收到的 ACK 起什么作用,主要用于握手和挥手阶段。
- channel:与服务端的连接 SocketChannel 对象,方便结束时关闭连接和向服务端发送数据以触发 Readable 事件。
- sentPackets:LinkedQueue 对象,每次向客户端发送期待回包的数据后,添加到此 queue 中,在收到 ACK 包后,如果头部数据满足条件就弹出头部数据并更新包状态。在其中的包,用于超时重发。
- packetListNode:自定义双向链表,用于检查客户端发送的数据是否丢包。如下图,若此时收到 seq 为 2001,payload 为 1000 的客户端包,则将数据插入第三个位置,并从头(当前 acknowledgementNumber 值匹配链表开头 seq)开始检索后,更新acknowledgementNumber为 4001,构造 ACK 包发送给客户端。此外,向客户端发送数据时,也应该从该链表中获取发送,在next.seq != this.exceptNext处停止。

- RTO:超时重传功能的超时时间,根据 RTT(来回通信延迟)计算而来,在 TCP 包头中带上 timestamp 字段后,客户端的每次回包都会带上响应的包的 timestamp,通过当前时间计算差值就能获取 RTT,再通过一系列算法就能获取 RTO,每次向客户端发送数据都可以设置一个延时任务:在 RTO 延迟后重发此包,除非此包已收到回应。
- 拥塞避免相关:rwnd(客户端的接收窗口)、cwnd(拥塞窗口)、ssthresh(慢启动阈值)等。
3、UDP 处理线程
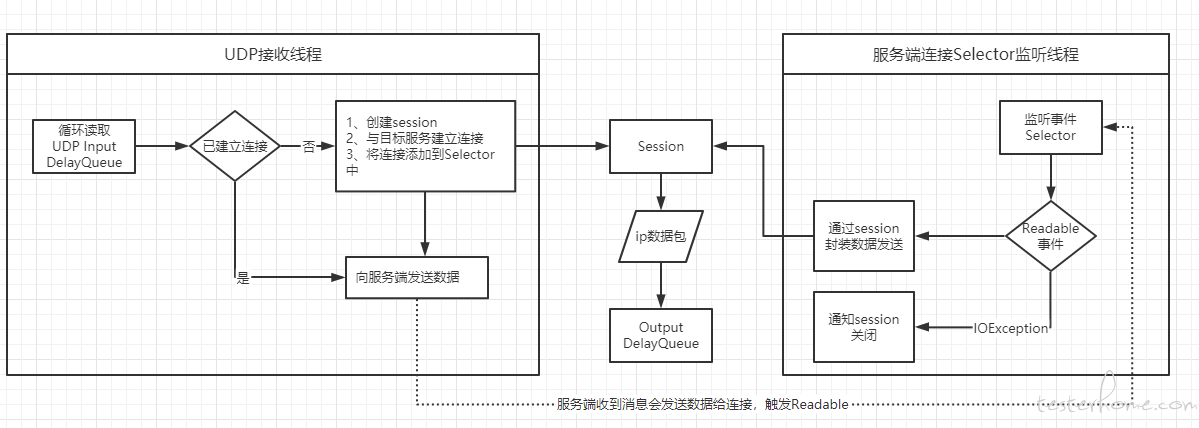
UDP 连接相对简单,只需维护与服务端的DatagramChannel即可,但也需要维护一个 session,用于 ip 包的identification记录。
4、ICMP 处理线程
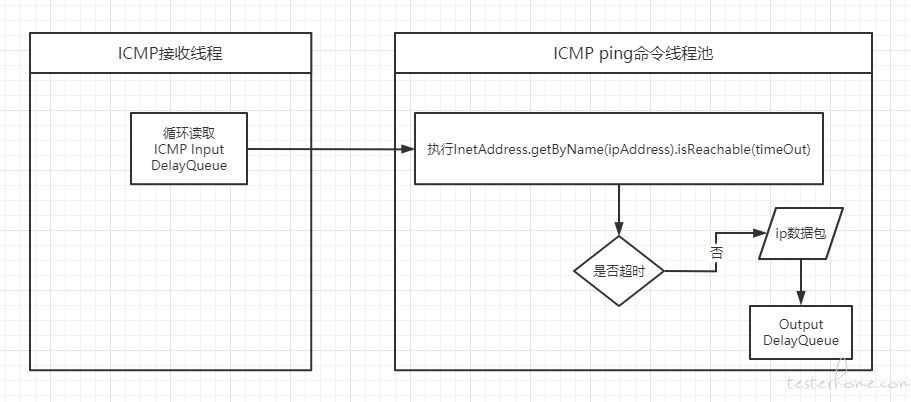
由于 ICMP 包的特性,只需要复制发送包,并反转下 srcAddr 和 destAddr 发送给客户端即可,故不需要 session 来管理。
六、TCP 的一些细节
上面已经介绍了 TCP 的架构,但 TCP 中有着非常多的细节,正是这些细节构成了这个可靠的协议。
1、Options
TCP 包头的长度不一定是 20 字节,取决于它是否拥有 Option。在 Tcp 包头中的第 12 字节开始的 4 位资料偏移表示了(TCP 包头的长度 /4),故 TCP 包头长度一定是 4 的倍数。
options 的格式基本都是 1 字节 kind + 1 字节长度 n +(n-2)字节数据。其中的例外为 kind 为 0 和 1 时,全长只有 1 个字节,0 代表选项结束,1 代表 Padding。
选项字段—最多 40 字节。每个选项的开始是 1 字节的 kind 字段,说明选项的类型。
- 0:选项表结束(1 字节)
- 1:无操作(1 字节)用于选项字段之间的字边界对齐。
- 2:最大报文段长度(4 字节,Maximum Segment Size,MSS)通常在创建连接而设置 SYN 标志的数据包中指明这个选项,指明本端所能接收的最大长度的报文段。通常将 MSS 设置为(MTU-40)字节,携带 TCP 报文段的 IP 数据报的长度就不会超过 MTU(MTU 最大长度为 1518 字节,最短为 64 字节),从而避免本机发生 IP 分片。只能出现在同步报文段中,否则将被忽略。
- 3:窗口扩大因子(3 字节,wscale),取值 0-14。用来把 TCP 的窗口的值左移的位数,使窗口值乘倍。只能出现在同步报文段中,否则将被忽略。这是因为现在的 TCP 接收数据缓冲区(接收窗口)的长度通常大于 65535 字节。
- 4:sackOK—发送端支持并同意使用 SACK 选项。
- 5:SACK 实际工作的选项。
- 8:时间戳(10 字节,TCP Timestamps Option,TSopt)
- 发送端的时间戳(Timestamp Value field,TSval,4 字节)
- 时间戳回显应答(Timestamp Echo Reply field,TSecr,4 字节)
- 19:MD5 摘要,将 TCP 伪首部、校验和为 0 的 TCP 首部、TCP 数据段、通信双方约定的密钥(可选)计算出MD5摘要值并附加到该选项中,作为类似对 TCP 报文的签名。通过 RFC 2385 引入,主要用于增强BGP通信的安全性。
- 29:安全摘要,通过 RFC 5925 引入,将 “MD5 摘要” 的散列方法更换为SHA 散列算法。
读取 options 代码:
public boolean checkOption(){
if (optionsAndPadding != null) {
int index = 0;
while (index < optionsAndPadding.length){
int kind = BitUtils.getUnsignedByte(optionsAndPadding[index++]);
if (kind == END_OF_OPTIONS_LIST) break; // kind为0,结束
if (kind == NO_OPERATION) continue; // kind为1,继续
switch (kind){
case MAX_SEGMENT_SIZE: // 获取MSS
MSS = BitUtils.getUnsignedShort(Arrays.copyOfRange(optionsAndPadding, index+1, index+3));
break;
case WINDOW_SCALE: // 获取窗口缩放
windowScale = BitUtils.getUnsignedByte(optionsAndPadding[index+1]);
break;
case TIME_STAMP: // 获取时间戳
timestampValueField = BitUtils.getUnsignedInt(Arrays.copyOfRange(optionsAndPadding, index+1, index+5));
timestampEchoReplyField = BitUtils.getUnsignedInt(Arrays.copyOfRange(optionsAndPadding, index+5, index+9));
break;
case SACK_OK: // 获取是否支持SACK
this.canSACK = true;
break;
case SACK: // 获取SACK内容
int sackLen = BitUtils.getUnsignedByte(optionsAndPadding[index]) - 2;
long leftBorder;
long rightBorder;
for (int offset=0; offset < sackLen; offset += 8) {
leftBorder = BitUtils.getUnsignedInt(Arrays.copyOfRange(optionsAndPadding, index+1+offset, index+5+offset));
rightBorder = BitUtils.getUnsignedInt(Arrays.copyOfRange(optionsAndPadding, index+5+offset, index+9+offset));
this.sackDataList.add(new SACKData(rightBorder<this.acknowledgementNumber, leftBorder, rightBorder));
}
}
int thisKindLen = BitUtils.getUnsignedByte(optionsAndPadding[index]) - 1; // 跳过以读取或未知报文长度
index += thisKindLen;
}
}
return false;
}
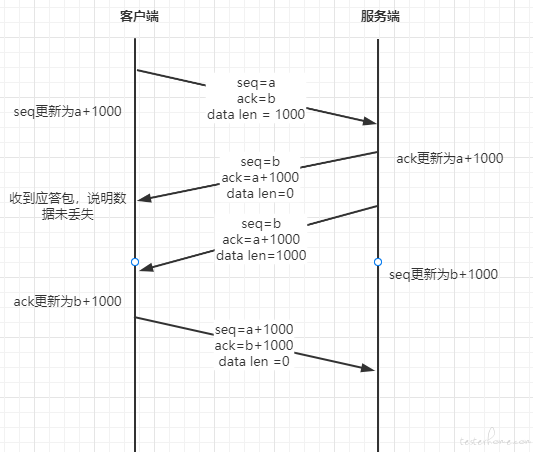
2、几种重传机制
重传机制主要依赖于上文提到的sequenceNumber(序列号)与acknowledgementNumber(确认应答),一个正常的流程应该如下图所示:
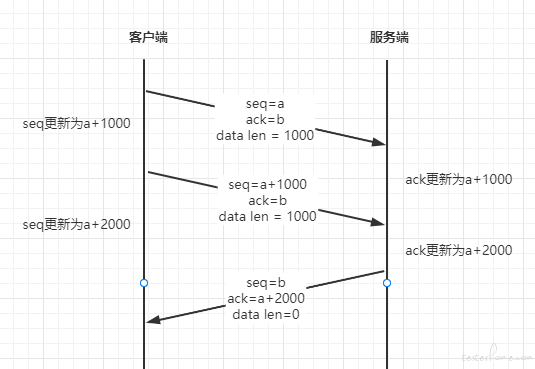
此外,由于延迟确认的存在,一个 ACK 报文可以回应多个数据包,如下图所示:
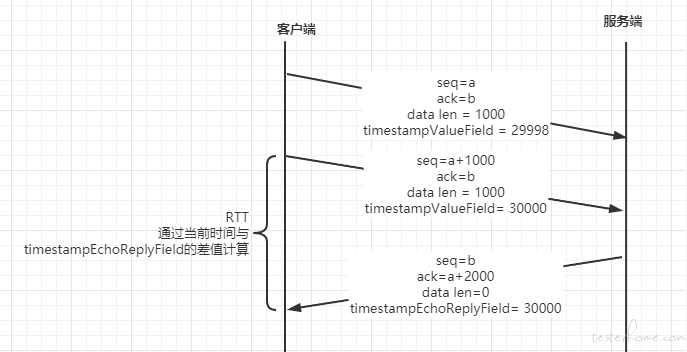
RTT是数据从网络一端传送到另一端所需的时间,也就是包的往返时间。一般通过 TCP 时间戳选项(TSOPT)计算,TCP 时间戳选项有 10 个字节,前两个字节分别为 8(代表是 TCP 时间戳类型)和 10(数据度:头部 2 + 内容 8),接下来 4 个字节为timestampValueField,即发送时间戳值,最后 4 个字节为timestampEchoReplyField,即响应回复时间戳值,其数值为回应的那个包的timestampValueField,发送端收到后,将本地时间减去收到的timestampEchoReplyField即可获得RTT。参考下图:
(1)、超时重传
重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据,也就是我们常说的超时重传。
定时器的时间就是上文中提到的RTO,关于 RTO 的算法,有很多标准,网上有很多资料可以参考,此处采用RFC6298。
RTO的特点在于略大于 RTT 的值。
https://www.cnblogs.com/xiaolincoding/p/12732052.html
- 当超时时间 RTO 较大时,重发就慢,丢了老半天才重发,没有效率,性能差;
- 当超时时间 RTO 较小时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
private final int TCP_RTO_MIN = 200; // liunx中,RTO最小为200ms
private static final int K = 4;
private static final int G = 1; // 时钟粒度,linux中为1ms
private static final float alpha= 0.125F;
private static final float beta= 0.25F;
private int RTO;
private float SRTT;
private float RTTVAR;
public void setRTT(int RTT) { // 每次更新RTT时触发。
this.RTT = RTT;
if (this.RTO == 0) { // 初始计算
this.SRTT = RTT;
this.RTTVAR = (float) RTT / 2;
} else {
this.RTTVAR = (1 - beta) * this.RTTVAR + beta * Math.abs(this.SRTT - RTT);
this.SRTT = (1 - alpha) * this.SRTT + alpha * RTT;
}
this.RTO = (int) Math.max(this.TCP_RTO_MIN, this.SRTT + Math.max(G, K*this.RTTVAR));
}
拥有了RTO后,通过将发送的数据包(作为回应的 ACK 包不需要)添加进 DelayQueue 中,同时设置延时为RTO即可,到延期后,若该包的HasAcked还是 false,则重发此包,并将此包的延时时间变为两倍,再次放入 DelayQueue 中。
/**
* 此消息用于服务端发送消息后,期待客户端的应答包,若长时间未收到,则需要重发或断开连接。
*/
public class WaitAckTask implements Delayed {
private static final String TAG = "WAIT ACK";
@FunctionalInterface
public interface GetNextDelay
{
int calculate(int delay);
}
private final TcpSession session;
// 若未等到ack,需要重发的包
private final IPPacket packet;
private long startTime;
private int delay; // 延迟任务到期时间(过期时间)
private GetNextDelay func; // 延时增长方法,一般为变成原来两倍
private int retryTime;
public WaitAckTask(IPPacket packet, int delay, int retryTime, TcpSession session, GetNextDelay func) {
this.packet = packet;
this.session = session;
this.startTime = System.currentTimeMillis();
this.delay = delay;
this.func = func;
this.retryTime = retryTime;
}
@Override
public long getDelay(TimeUnit unit) {
long remaining = this.startTime + this.delay - System.currentTimeMillis();
return unit.convert(remaining, TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
return (int) (this.getDelay(TimeUnit.MILLISECONDS) - o.getDelay(TimeUnit.MILLISECONDS));
}
public WaitAckTask checkAck() { // 若返回为WaitAckTask则将此Task包中的Packet再发送给客户端,同时再次延时此任务
synchronized (this.session) {
if (this.session.getAbortConnect()) {
// 连接已断开
return null;
}
if (!this.packet.getHasAck() && this.retryTime > 0) {
this.packet.ip4Header.identification = this.session.getIdentification();
// 防止重发包造成重传二义性问题,更新此tcp包的timestamp
this.packet.tcpHeader.setTimestampValueField(System.currentTimeMillis() & 0xfffffff);
// 检测到发生发送丢包,更新cwnd状态
this.session.setCurrentCongestionStatus(TcpSession.congestionStatus.SlowStart);
// 再次发送包,且设置下次重试时间
return new WaitAckTask(this.packet, this.func.calculate(this.delay),
this.retryTime - 1, this.session, this.func);
} else if (!this.packet.getHasAck() && this.retryTime == 0){
Log.w(TAG, session.getConnectionKey() + ": retry chance is use up!");
return null;
} else { // 此包已经确认接收
return null;
}
}
}
public IPPacket getPacket() {
return packet;
}
public TcpSession getSession() {
return session;
}
}
(2)、快速重传
https://zh.wikipedia.org/wiki/TCP%E6%8B%A5%E5%A1%9E%E6%8E%A7%E5%88%B6
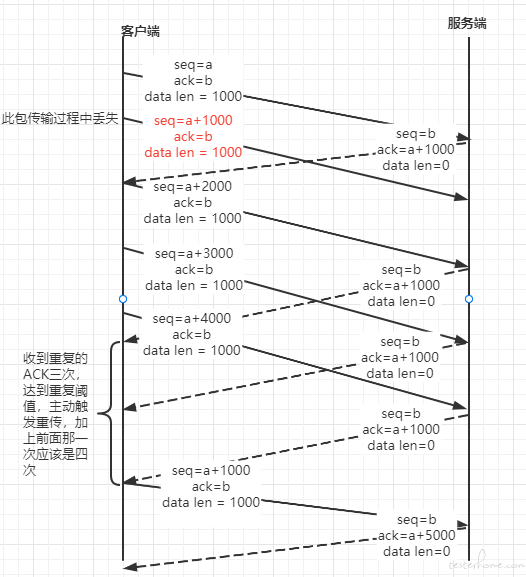
快速重传(Fast retransmit)是对 TCP 发送方降低等待重发丢失分段用时的一种改进。TCP 发送方每发送一个分段都会启动一个超时计时器,如果没能在特定时间内接收到相应分段的确认,发送方就假设这个分段在网络上丢失了,需要重发。这也是 TCP 用来估计 RTT 的测量方法。
快速重传就是基于以下机制:如果假设重复阈值为 3,当发送方收到 4 次相同确认号的分段确认(第 1 次收到确认期望序列号,加 3 次重复的期望序列号确认)时,则可以认为继续发送更高序列号的分段将会被接受方丢弃,而且会无法有序送达。发送方应该忽略超时计时器的等待重发,立即重发重复分段确认中确认号对应序列号的分段。
官方的介绍太过绕口,可以参考下图:
(3)、选择确认(SACK)
最初采取累计确认的 TCP 协议在丢包时效率很低。例如,假设通过 10 个分组发出了 1 万个字节的数据。如果第一个分组丢失,在纯粹的累计确认协议下,接收方不能说它成功收到了 1,000 到 9,999 字节,但未收到包含 0 到 999 字节的第一个分组。因而,发送方可能必须重传所有 1 万个字节。
为此,TCP 采取了 “选择确认”(selective acknowledgment,SACK)选项。RFC 2018 对此定义为允许接收方确认它成功收到的分组的不连续的块,以及基础 TCP 确认的成功收到最后连续字节序号。这种确认可以指出SACK block,包含了已经成功收到的连续范围的开始与结束字节序号。在上述例子中,接收方可以发出 SACK 指出序号 1000 到 9999,发送方因此知道只需重发第一个分组(字节 0 到 999)。
这个功能不是默认开启的,需要在 SYN 包中验证 TCP 包中 Options 字段中是否有 kind=4 的字段,当双方都支持 SACK 后,其结构如下图所示,其 kind 为 5,内容长度是可变的,已 8 个字节为一对数据出现,前 4 个字节为左边界,后 4 个字节为右边界。
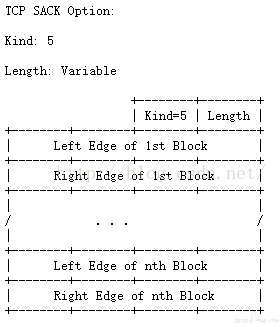
例如,客户端已收到 a+1000 确认的情况下,发送时丢失了 seq=a+1000,data length=1000 的包,服务端返回的 ACK 包的 SACK 依次为:
第一次重复 ACK 的 SACK:a+2000 ~ a+3000
第二次重复 ACK 的 SACK:a+2000 ~ a+4000
第三次重复 ACK 的 SACK:a+2000 ~ a+5000
这样客户端就能判断服务端丢失了 a+1000 ~ a+2000 分段。
(4)、重复 SACK(duplicate-SACK)
TCP 发送方会把乱序收包当作丢包,因此会重传乱序收到的包,导致连接的性能下降。重复 SACK 选项(duplicate-SACK option)是定义在 RFC 2883 中的 SACK 的一项扩展,可解决这一问题。接收方发出 D-ACK 指出没有丢包,接收方恢复到高传输率。D-SACK 使用了 SACK 的第一个段来做标志,
D-SACK 旨在告诉发送端:收到了重复的数据,数据包没有丢,丢的是 ACK 包;或者 “Fast Retransmit 算法” 触发的重传不是因为发出去的包丢了,也不是因为回应的 ACK 包丢了,而是因为网络延时导致的 reordering。
D-SACK 用于接收到重复包的回复,因为其和 SACK 复用一个 kind,所以判断 D-SACK 的方法有两种:
- SACK 的右边界 < acknowledgementNumber
- SACK 的范围在下一个段的范围之内:例如,一个 SACK 为 2 个,[(a+1000, a+2000), (a+1000, a+4000)],其中第一个为 D-SACK,第二个为 SACK。
3、滑动窗口
首先思考这样一个问题,如果每次发送后,要等到收到回应再发下一个包是不是更可靠?
这样一问一答的方式可靠但效率非常差,在不出现丢包的情况下,第二个包的发送要等到 1 个 RTT 之后,第三个包要等到 2 个 RTT 之后....
以此类推,RTT 越长,这种方式的效率就越低。
在 TCP 中,使用滑动窗口可以提高效率的同时,保证数据的完整性。TCP 滑动窗口分为接受窗口,发送窗口。
(1)、发送窗口
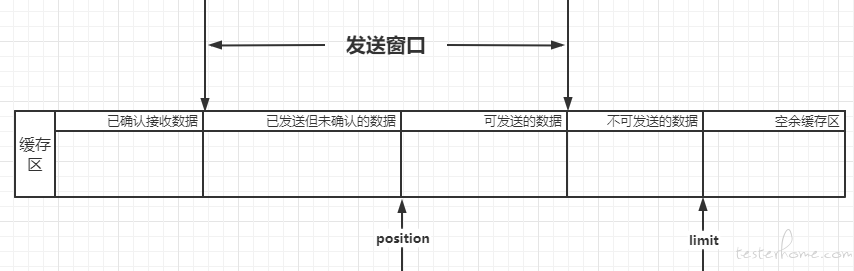
如上图所示,发送缓存区一般分为 4 个部分:
- 已经确认收到的数据,即已经收到 ACK 的数据。
- 已经发送,但还未确认的数据,这部分数据在窗口内存在的时间最长。
- 可发送的数据,需要将数据拆分成客户端可接受的 MSS 后再发出。【注:MSS(最大分段大小)自身的 MSS 一般为 VPN 的 MTU - ip 包头长度 - tcp 包头长度,可在 option 中指定自身可接受的 MSS 大小】。
- 不可发送的数据,窗口之外的数据。
当收到确认后,发送窗口的左边界和右边界会往右移动,这样就将原不可发送的数据变成了可发送的数据。
可发送数据的存在时间非常短,发送完就转变成了已发送但未确认的数据。
不可发送的数据可能不存在,取决于窗口是否包含了剩余所有数据。
代码中我们使用 ByteBuffer 充当缓存区,并将 position 固定在可发送数据的开始,limit 是不可发送数据的结尾。
// 以下非真实项目代码
private final ByteBuffer sendBuffer = ByteBuffer.allocate(65535); //发送缓存区
private int rwnd; // 客户端告知的接收窗口,用作发送窗口大小
public void sendFromSendBuffer() {
int canSendLength = (Math.min(this.rwnd, this.sendBuffer.limit()) - this.sendBuffer.position()); // 可发送的内容可能小于窗口
byte[] data;
int len;
while (canSendLength > 0) {
if (canSendLength > this.getMss()) { // 根据MSS大小封装包
len = this.getMss();
data = new byte[len];
this.sendBuffer.get(data);
this.sendToClient(this.createSendPackage(TCPHeader.ACK, data));
} else {
len = canSendLength;
data = new byte[canSendLength];
this.sendBuffer.get(data);
this.sendToClient(this.createSendPackage((byte) (TCPHeader.ACK | TCPHeader.PSH), data));
}
canSendLength -= len;
}
}
public synchronized boolean addToSendBuffer(ByteBuffer buffer) {
// 空余缓存区放不下想加入的buffer,返回false,让使用端等待空间释放
if (this.sendBuffer.limit() + buffer.limit() > this.sendBuffer.capacity()) return false;
// 当前位置为已发送和未发送的临界点,添加完数据后需要归位
this.sendBuffer.mark();
this.sendBuffer.position(this.sendBuffer.limit());
this.sendBuffer.limit(this.sendBuffer.position() + buffer.limit());
this.sendBuffer.put(buffer);
this.sendBuffer.reset();
// 可能添加后存在了可发送的数据,触发发送方法。
this.sendFromSendBuffer();
return true;
}
// 收到ACK包,更新缓存区,将已确认的数据移除,这样操作相当于窗口位置不变,将缓存区往左移动
public synchronized void updateSendBuffer(int releaseSize) {
int mark = this.sendBuffer.position() - releaseSize;
this.sendBuffer.position(releaseSize);
this.sendBuffer.compact();
this.sendBuffer.limit(this.sendBuffer.position());
this.sendBuffer.position(mark);
this.sendFromSendBuffer(); // 更新窗口的同时,检查是否有新数据能发送
}
(2)、接收窗口
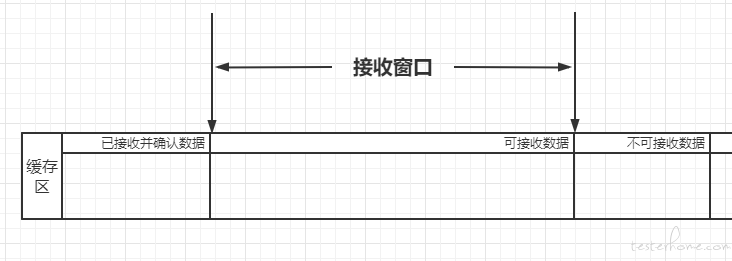
接收窗口相较发送窗口来说更为简单,只要负责可接受数据即可。项目中不像发送窗口一样单独设立一个缓存区,而是使用上文提到的双向链表进行接收数据,对数据的接收处理可以参考下文作为接收端时,如何返回正确的 ACK。
4、流量控制
流量控制用来避免主机分组发送得过快而使接收方来不及完全收下,一般由接收方通告给发送方进行调控。
TCP 使用滑动窗口协议实现流量控制。接收方在 “接收窗口” 域指出还可接收的字节数量。发送方在没有新的确认包的情况下至多发送 “接收窗口” 允许的字节数量。接收方可修改 “接收窗口” 的值。
当接收方宣布接收窗口的值为 0,发送方停止进一步发送数据,开始了 “保持定时器”(persist timer),以避免因随后的修改接收窗口的数据包丢失使连接的双侧进入死锁,发送方无法发出数据直至收到接收方修改窗口的指示。当 “保持定时器” 到期时,TCP 发送方尝试恢复发送一个小的 ZWP 包(Zero Window Probe),期待接收方回复一个带着新的接收窗口大小的确认包。一般 ZWP 包会设置成 3 次,如果 3 次过后还是 0 的话,有的 TCP 实现就会发 RST 把链接断了。
在此项目中,需要维护的是接收窗口的大小,而实际上能够接收的大小是由操作系统决定的,也即虚拟网口的文件描述符。但可以借助此选项控制客户端发送数据的频率。
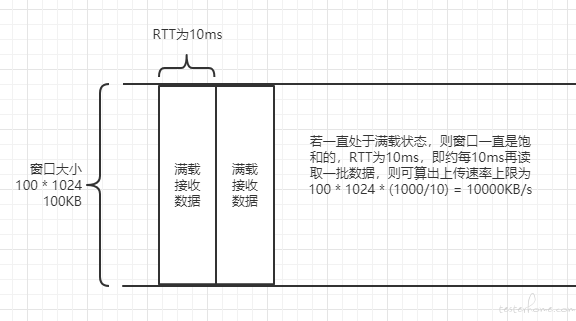
以上只是理想情况,实际上,RTT 的值是随时变化的,不可能控制如此精准,但的确能起到控制上传速率的效果。
5、拥塞避免
除了要控制自己的接收速度,还需要控制自己的发送速度:拥塞控制算法。
cwnd是拥塞窗口(congestion window),其大小是动态变化的,初始为 1MSS。
刚建立连接时,拥塞窗口处于慢启动状态,每当收到客户端回包后,就进行cwnd += MSS,直到cwnd >= ssthresh,ssthresh初始值一般设为 65535(max unsigned short)。
这个过程中,由于每个 ACK 都会增加cwnd,且一个 MSS 内能收到多个 ACK,cwnd增长又会增加发送的数据,导致获取的 ACK 增加,所以其增长是指数增长。
当cwnd >= ssthresh后,拥塞窗口进入拥塞避免状态,cwnd的增长变为线性,即单位时间内(RTT)增长一个 MSS,也即增长的系数为MSS/RTT。
当发生丢包后(收到 3 次重复 ACK),
Tahoe 算法(超时重传触发)
对于 TCP Tahoe 算法,当发生丢失时,会进入 “快速重传” 机制,cwnd变为初始 MSS,ssthresh变为cwnd的一半,并重新进入慢启动状态。
Reno 算法(快速重传触发)
TCP Reno 算法实现了一个名为 “快速恢复” 的机制,ssthresh设为之前cwnd的一半,和作为新的cwnd,并跳过慢启动阶段,直接进入拥塞控制阶段。
完整过程如下图所示:
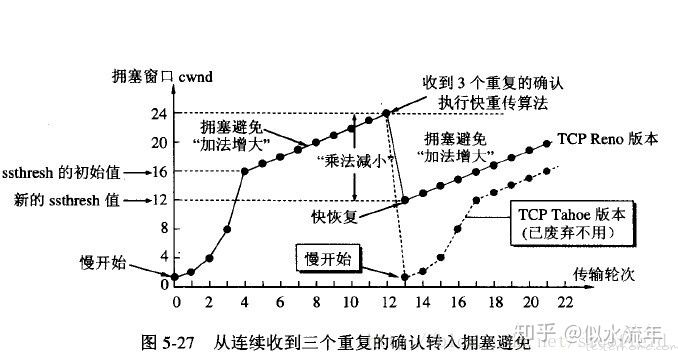
拥塞窗口 cwnd
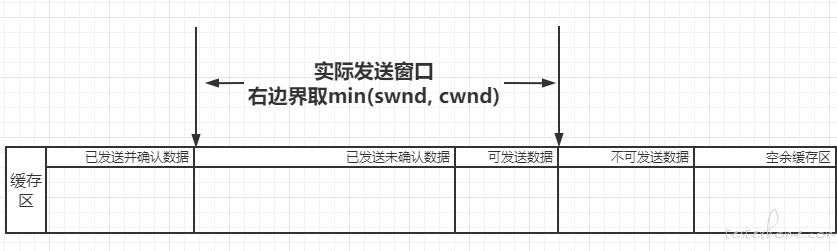
在上文发送窗口中读取数据时,要在min(swnd, cwnd)中获取窗口右边界。另外收到 ACK 后加上拥塞窗口的变化。另外,还需在超时重传时触发快速重传,快速重传时触发快速恢复
public void sendFromSendBuffer() {
// int canSendLength = (Math.min(this.rwnd, this.sendBuffer.limit()) - this.sendBuffer.position()); // 可发送的内容可能小于窗口
int canSendLength = Math.min(Math.min(this.cwnd, this.rwnd), this.sendBuffer.limit()) - this.sendBuffer.position();
....后续省略,参考上文
}
public synchronized void updateCongestionWindow(int releaseSize) {
switch (this.currentCongestionStatus) {
case SlowStart:
this.cwnd += this.MSS;
if (this.cwnd > this.ssthresh) this.setCurrentCongestionStatus(congestionStatus.CongestionAvoidance);
break;
case CongestionAvoidanceReno: // Reno算法快恢复状态
case CongestionAvoidance:
this.cwnd += (System.currentTimeMillis() - this.CongestionAvoidanceStartTime) * this.slope;
this.CongestionAvoidanceStartTime = System.currentTimeMillis();
break;
}
....后续省略,参考上文
}
public void setCurrentCongestionStatus(congestionStatus currentCongestionStatus) {
switch (currentCongestionStatus){
case CongestionAvoidance:
// 进入拥塞避免状态
this.CongestionAvoidanceStartTime = System.currentTimeMillis();
this.slope = this.MSS / this.SRTT; // 使用当前SRTT作为RTT MSS/RTT
break;
case SlowStart:
// 快速重传
this.cwnd = this.MSS;
this.ssthresh /= 2;
break;
case CongestionAvoidanceReno:
// 快速恢复
this.cwnd = this.cwnd / 2;
this.ssthresh = this.cwnd;
break;
}
this.currentCongestionStatus = currentCongestionStatus;
}
6、作为接收端时,如何返回正确的 ACK?
由于可能接收到乱序包和延迟确认机制,不能简单的返回收到数据包的 seq+payload len 作为 ack,而是检查通过之前收到的数据,并返回合适的 ack。
上文提到使用了双向链表保存了收到的数据,代码如下:
public class TcpPacketListNode {
long sequenceNumber; // tcp序列号
byte[] payload; // 该tcp包所包含的数据
long exceptNextSequence; // 期待的下一个包的序号
TcpPacketListNode next; // 下一节点
TcpPacketListNode prev; // 上一节点
public TcpPacketListNode(long sequenceNumber, byte[] payload) {
this.sequenceNumber = sequenceNumber;
this.payload = payload;
this.exceptNextSequence = sequenceNumber + payload.length; // 期待的下一个包应该是seq+data len
}
// 获取链表头部
private TcpPacketListNode getHeader() {
TcpPacketListNode ptr = this;
while (ptr.prev != null) {
ptr = ptr.prev;
}
return ptr;
}
// 将新获取的数据添加到链表中
private void insertPacket(long sequenceNumber, byte[] payload){
TcpPacketListNode newNode = new TcpPacketListNode(sequenceNumber, payload);
TcpPacketListNode ptr = this;
if (sequenceNumber > ptr.sequenceNumber) {
while (ptr.next != null) {
if (ptr.next.sequenceNumber < sequenceNumber) {
ptr = ptr.next;
} else if (ptr.next.sequenceNumber == sequenceNumber) { // TODO:重复包,需要补充D-SACK
return;
} else {
break;
}
}
newNode.next = ptr.next;
newNode.prev = ptr;
ptr.next = newNode;
if (newNode.next != null) newNode.next.prev = newNode;
} else if (sequenceNumber < ptr.sequenceNumber) {
while (ptr.prev != null){
if (ptr.prev.sequenceNumber > sequenceNumber) {
ptr = ptr.prev;
} else if (ptr.prev.sequenceNumber == sequenceNumber) { // TODO:重复包,需要补充D-SACK
return;
} else {
break;
}
}
newNode.next = ptr;
newNode.prev = ptr.prev;
ptr.prev = newNode;
if (newNode.prev != null) newNode.prev.next = newNode;
}
}
//插入数据同时返回接收包的ack,需要知道上一次序号到哪了,用于检测头节点是否正确
public long insertAndGetAck(long exceptSequence, IPPacket packet) {
this.insertPacket(packet.tcpHeader.sequenceNumber, packet.payload); // 先插入数据
TcpPacketListNode header = this.getHeader(); // 从头开始检查
while (header != null) {
if (exceptSequence > header.sequenceNumber) { // 一些情况下已经回复ACK,但数据还未发出,需要跳过之前的数据
header = header.next;
continue;
}
if (header.sequenceNumber != exceptSequence) return exceptSequence;
exceptSequence = header.exceptNextSequence;
header = header.next;
}
return exceptSequence;
}
}
当获得新数据时,插入链表,并检查链表,当下一个节点 sequenceNumber 不等于当前节点的 exceptNextSequence 就是有丢失数据,如果从头至尾都是连续的,则代表数据没有丢失。两种情况下直接用当前节点的 exceptNextSequence 当作 ACK 包的 ack num即可。
7、作为发送端,如何保证数据的可靠传输?
首先,所有发出去的数据都不应该立马删除,而是维护在一个 Queue 中,发送后加入队尾以及加入全局的超时重传 DelayQueue,当收到 ACK 包时,检查 Queue 的队头包的 seq+payload len 是否小于等于 ACK 包的 ack num,如果是的话则将队头包弹出,同时将该包中的 HasACK 置为 true,这样当延迟时间到后,将不触发超时重传,同时等待此包被垃圾回收即可,然后继续检查 Queue 下一个队头,直到不满足条件。
/**
TCP session中的方法
*/
// 发送给客户端的包,用于确认客户端是否收到
private ConcurrentLinkedQueue<IPPacket> sentPackets = new ConcurrentLinkedQueue<>();
public synchronized void sendToClient(IPPacket packet, boolean needAck){
this.sentPackets.offer(packet); // 添加到Queue中
switch (this.getStatus()){
case SYN_RECEIVED: // 收到Syn包,进入SYN_RECEIVED状态,回复SYN ACK,等待ACK,此阶段被利用于DDOS攻击
this.waitAckTasksQueue.offer(new WaitAckTask(packet, 1000, TCP_SYNACK_RETIRES, this, (delay -> { return delay * 2; })));
case ESTABLISHED:
this.waitAckTasksQueue.offer(new WaitAckTask(packet, this.RTO == 0 ? 1000 : this.RTO, TCP_SYNACK_RETIRES, this, (delay -> { return delay * 2; })));
}
// 下载延时
if (!this.outputQueue.offer(new DelayMessage(packet, VpnRunnable.getReceiveDelay()))) Log.e(TAG, "send to client ERROR!!!!! fail write to outputQueue");
}
/**
TCP线程中收到ACK包,部分代码
*/
private void acceptAck(IPPacket packet, TcpSession session){
ConcurrentLinkedQueue<IPPacket> sendPacketsQueue = session.getSentPackets();
IPPacket sendPacket;
while (true) {
sendPacket = sendPacketsQueue.peek();
if (sendPacket == null) break;
if ((sendPacket.tcpHeader.sequenceNumber + sendPacket.payload.length) <= packet.tcpHeader.acknowledgementNumber) {
sendPacketsQueue.poll();
sendPacket.setHasAck(); // 将该数据包置为HasAck
session.updateCongestionWindow(sendPacket.payload.length); // 更新拥塞窗口
continue;
}
break;
}
}
七、弱网功能的实现
1、延迟
从上一节的设计中已经可以看出,延迟是通过DelayQueue(延迟队列)实现的,通过推迟处理线程收到数据包的时间来模拟上行延迟,通过推迟 OutputStream 获取数据的时间来模拟下行延迟。
由于数据在处理过程中难免会消耗一些时间,所以正常情况下,误差能控制在 10ms 以内。
除此之外,ICMP 包不像 TCP 包一样能立刻返回 ACK,它需要等待服务端响应,所以它的延迟时间应该减去等待响应的时间。
2、限流 (带宽)
关于限流我想到两种做法:
(1)、控制 IO
在结构设计中,流经 vpn 的数据只通过两个 Stream 控制,只要限制读取/写入的速度就能限制上传/下载速度。
常见的测速软件速度单位一般为 kb/s 或者 kB/s,而我们读取到的 size 一般是 Bytes 为单位,所以只要控制单位时间能通过的数据量就能达到限速的效果,且时间粒度越小越精准。
例如,想要限速 1000kB/s:
// 以下并非实际项目代码
FileChannel vpnInput = new FileInputStream(mParcelFileDescriptor.getFileDescriptor()).getChannel(); // 读取channel
ByteBuffer mPacket = ByteBuffer.allocate(VpnMTU);
int readLength = 0;
long startTime = System.currentTimeMillis();
int speedLimitPerSecond = 1000 * 1024; // 1000 KB
int interval = 100; // 100ms为一次判断间隔 ,理论上粒度越小越准确
long currentTime;
while (true) {
currentTime = System.currentTimeMillis()
if ((currentTime - startTime) >= interval) {
readLength = 0;
startTime = currentTime;
}
size = vpnInput.read(mPacket);
readLength += size;
if (readLength >= (speedLimitPerSecond / interval)) {
Thread.sleep(interval - (currentTime - startTime)); // 等待下个间隔
}
}
这样的限制可以用于下行流量控制,但对于上行流量就不太合理,参考上文流量控制,一般通过向对端发送接收窗口大小来控制流量。
(2)、控制窗口
为了确保接收窗口在满载情况下,释放时间都是恒定的,还是采用了延时任务的方式,读取数据后,全局的总体接收窗口大小减去数据长度,一段固定时间后再将减去的部分补回。
// TCP Session类中
public class TcpSession extends Session {
private static long totalRecvWindow;
private DelayQueue<DelayMessage> queue;
....其他方法变量省略
public void setTotalRecvWindow(int size){
this.totalRecvWindow -= size;
queue.offer(new DelayMessage(size, this.RTT)); // 到期后会重新加上
}
public IPPacket createPacket() { // 创建并发送IP数据包的方法
IPPacket newSendPackage;
short scale = 0;
long windows = Math.max(this.totalRecvWindow, 0); // window为0即告知对方不要再发送数据
// 计算窗口缩放,window只有2字节
while (windows > 65535){
windows = windows >> 1;
scale += 1;
}
newSendPackage.tcpHeader.window = (int) windows;
newSendPackage.tcpHeader.windowScale = scale;
.....省略其他步骤
}
}
3、丢包和抖动
- 丢包
丢包操作最简单的就是随机丢包模式,在出口和入口使用 Random 方法决定是否丢弃,因为完善了 TCP 的细节,所以在丢包后能表现出真实的网络反应。
但真实的丢包一般都是伴随着高延迟,高负载、或者随着网络抖动而出现的,所以其具体出现节点还有待斟酌。
- 网络抖动
抖动可能由网络上的许多因素引起,其中最主要是由于分组交换网络无法确保所有的数据包都经由相同的传输路径。
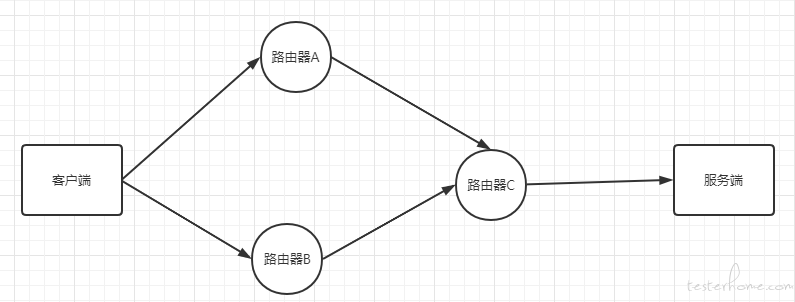
如上图,例如,数据包 1 经由路由器 A -> 路由器 C -> 服务端,但由于路由器 A 负载较高发生了阻塞,导致数据包 1 的上传延时为 100ms,而数据包 2 走的线路是路由器 B -> 路由器 C -> 服务端,过程中没有阻塞,最终上传延时是 10ms。
此处只是简单举例,真实情况可能会复杂的多,因为分组交换会将数据包拆成更小的数据包发送,就是说一个数据包可能会经由多种路由到达目的地。
这种情况下,会导致后发的包可能会先于先发的包到达,对于实时性要求比较高的场景影响会比较大,比如实时视频。而对于 TCP 连接来说,本身就拥有乱序收包的能力,会将这种抖动转换成丢包、延迟处理。
在项目中实现延迟随时间波动的效果,需要每次的延时都通过当前时间和一个指定的周期函数生成。

例如,想实现如下图所示的周期性网络抖动,其模拟的是周期性网络阻塞:
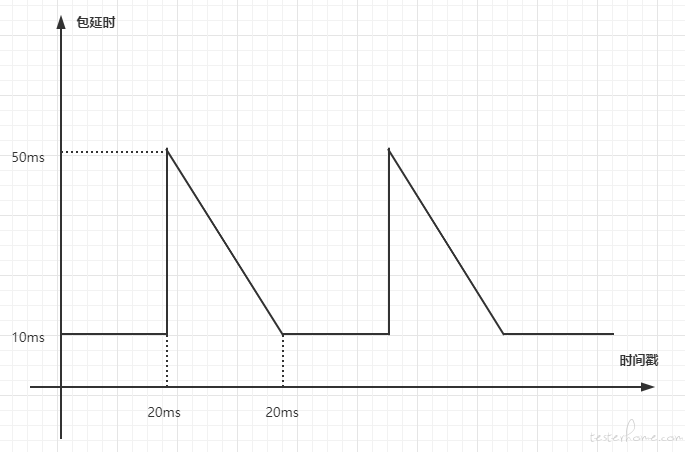
可以观察出在每 40ms 的后 20ms 会发生网络抖动,即周期 T 为 40ms,建立以下函数计算延时:
public static int startTime; // vpn开启时间
public static int getCurrentDelay(){
int period = 40; // 周期为40ms
long currentTime = System.currentTimeMillis() - startTime;
int remainder = currentTime % period; // 取余数
if (remainder < 20) {
return 10;
} else {
// 一元函数
return (-2 * remainder) + 90;
}
}
八、总结与思考
1、拓展功能
对于弱网工具后续发展方向,我自己的一些想法。
- 弱网场景录制:一些弱网场景只能通过网上提供的参数进行配置,对于一些特殊的实际场景并不能满足,而录制功能能够通过测速获取当前的网络环境配置,应该是一个比较实用的功能。
- 弱网流量回放:一些由于弱网导致的问题在测试环境难以复现,可以通过此工具录制线上弱网下的流量并回放到测试环境中进行测试。
2、目前还存在的问题
- 高负载下程序性能消耗较大。
- 对数据包处理不够健全,无法应对一些特殊情况,例如:除 TCP、UDP、ICMP 以外的包、ICMP echo 包以外的包、处理 IP 分片及其余 TCP 的 Options。
3、我想说的
限于篇幅还有很多东西没讲,比如各个数据包的 checksum、DNS 数据包的拦截等,另外东西也比较多,写的比较乱。
后续有机会会申请开源,敬请期待。
