-
jenkins 一个项目生成两个报告报错 at September 09, 2021
从截图上看,你
Archiving的第二个是把整个C:/都打包记录到指定目录,这范围太大了吧?
C 盘会有 windows 操作系统的很多相关文件,其中不少文件都是有进程长期占用的,所以遇到这个报错不奇怪。根本原因是你范围有问题,不应该打包整个 C 盘的内容到报告目录里。
-
大家觉得 app 的翻译测试要怎么测试呢 at September 09, 2021
人工查看是否有重叠等现象,场景比较多的时候,这块的工作任务会比较重
之前 mtsc 大会有见到过这方面的议题,通过把值设定为所有语言下翻译的最大长度 + 页面自动遍历 + 图像重叠检测来处理。具体的你可以到公众号发送 ppt ,找到存历年 ppt 的网盘,搜索 全球化 这类关键词
-
selenium 进行 web 的 UI 自动化测试时如何定位发现的问题 at September 09, 2021
你这块是排查定位所需数据的聚合方面的问题了,如果前后端本身有日志聚合服务(如 ELK ),记录下时间段,上去取即可。如果没有,只能因地制宜自己想办法弄。
前端到后端的,4 楼已经说了,就不重复了。
后端内部的,做个脚本 ssh 到各个服务器一个个去捞也是一种办法,当然直接聚合到 ELK 是最好的。本质上还是,作为一个人要从哪些地方定位,那就把那些地方的信息都聚合起来。这样聚合后,自动化或者手工测试,定位问题效率都能提高不少。
-
接口测试、自动化有必要去数据库捞数据校验么 at September 08, 2021
所以走查询接口在能查到需要字段的情况下,我觉得是更符合业务测试场景的一种方式
这里有一个点,校验数据库数据 != 不测试查询接口逻辑。只是把 写接口->读接口 ,进一步拆细为 写接口->数据库验证, 数据库数据->读接口验证 。拆细的好处校验的内容更独立,失败时排查范围也更小(读 + 写 fail 时,你还得通过查库来排查是写的问题还是读的问题)。
所以在符合业务测试场景方面,两个是没差别的,差别只是要不要多做数据库校验这一步。
在手工校验的阶段,是会人工去数据库比对一下数据的,但是写自动化脚本时还有没有这个必要
这个说实话,看实际业务和自动化脚本可以投入的成本有多少。从最严谨的角度说,查库会比不查库更独立,适用范围也更广(特别对于查接口没有那么完备,或者写和读并非一一对应的情况下),问题定位也更高效(比如 fail 时,可以把范围缩小到只是写接口有问题)。但如果说可投入成本有限,且查的接口也确认可以满足,外部业务都只会通过接口而不会通过数据库获取数据,那仅在接口层面确保写和读保持一致,不校验数据库的实际数据情况,也是可以的。
写自动化脚本有没有必要做数据库校验,取决于你是否信任没有校验数据库的脚本的执行结果,是否可以明确认为写 + 读组合逻辑的正确就可以认为功能正确。如果能信任,那就没问题。
-
接口测试、自动化有必要去数据库捞数据校验么 at September 08, 2021
个人理解:
1、根据你这个业务描述,mysql 和 es 都分别有存储,而查询接口很可能只是查其中一个库,另一个有可能就没提供查询接口?这种情况下,只通过查询接口,校验会不够完整。
2、我们以前是因为有一些入库操作是没有直接的查询接口可查的(比如日志表、流水表),或者查询接口查出来的不一定全(比如一些非业务系统用到,但大数据要用到的审计字段,创建时间、创建人之类的),所以要做数据库校验。
3、最主要的点,是数据库校验是对写接口逻辑最直接的校验方式,毕竟写接口的逻辑本质就是在写入数据库,而查询接口已经是另一段和写无关的读逻辑了,为了性能有可能先读缓存,后读库。在极端情况下有可能两个都错在一个位置(比如代码逻辑都映射为 1=false,实际数据库定义 1=true),反而最后看起来是对的结果。这种情况下可能会导致基于数据库数据进行处理的下游应用(比如大数据报表)出问题。
-
实时可视化 iOS 性能数据 tidevice+pyiosdevice+mysql+grafana at September 07, 2021
挺好,perfdog 付费了,这个也可以顶上。如果能附上完整的源代码,整个方案就更易用了。
-
【活动】MTSC 2021 深圳站议题征集 at September 07, 2021
问卷末尾有提到,如果有 ppt,ppt 可以单独提交邮件到 topic@testerhome.com 邮箱,邮件名为 公司 + 议题名称 。
-
职场 DIY at September 06, 2021
有点没看懂,这个文章想表达什么?职场 DIY 是啥意思呢?
-
那些年抓过的 “BUG”,你见过几只? at September 06, 2021
好有才
-
自动化是否被过度神话了? at September 06, 2021
我理解不是过度神话,可能是有很多人把它当做银弹了。把提高效率=自动化,没有根据实际项目去评估投入产出比。
其实视野大了后,提高效率的手段会多很多。比如多用靠谱的代码自动生成工具,有效减少手写代码的 bug,测试用例也可以精简不少;架构设计上减少重复,减少变更后要验证的范围,也能提高效率。只是确实会有一部分测试,视野只看到手工测试,提效想法就会局限在怎么让手工测试执行得更快,自然就会觉得能让执行速度大幅度提升的自动化非常好了。
我觉得不如楼主补充下,为何会觉得自动化被过度神话?是看了哪些资料产生这个感觉?
PS:金字塔的图印象中 2-3 年前已经改为菱形了,因为绝大部分互联网公司是不可能做那么完善的单测的,投入产出比相对高的是接口层的自动化。不知道你看的是什么时候的文章?
-
有没有一种工具能够对 APP/WEB 所有操作的页面进行录制保存,辅助元素抓取的 at September 06, 2021
嗯嗯,明白你的目的。从目前工具上,暂时没接触过有这样功能的工具。
建议你可以换一下思路,用类似 page object 的模式写用例。每个页面用到的元素记录到 page object 里面。你写用例的时候直接用就是了,也不用用例里各种 find element 。
-
有没有一种工具能够对 APP/WEB 所有操作的页面进行录制保存,辅助元素抓取的 at September 06, 2021
从功能上,你把 dump 下来的页面结构 + 截图保存起来,使用时代替实际实时抓取的值,发给元素抓取工具,是可以做到的。只是这个功能可能并不是核心功能,所以一般工具没做。
-
appium 报错,想问下是啥原因 at September 05, 2021
看下你环境变量里,JAVA_HOME 配置的到底是啥?appium 都是问系统拿的值,这个值不是凭空出来的,一定是某个地方配置出来的。
另外,也说明下,经过命令行敲
java和javac命令可以直接调用对应程序,是通过 PATH 这个环境变量来实现的。这个和 JAVA_HOME 这个环境变量是完全独立的,没有强依赖关系。java -version调用到的 java ,不一定是 JAVA_HOME 配置的java。举个 linux 里面写法的例子(忘记 windows 下环境变量的表示方式了):export JAVA_HOME=/user/jdk16 export PATH=$PATH:/user/jdk1.8这样配置下,你用命令行调用
java命令,用的是 1.8 的(PATH 里面配置的值),所以java -version也是 1.8 的。但 JAVA_HOME 却是 16 的。虽然很多教程都会教配置时 PATH 里面不要配置绝对路径,应该配置PATH=$PATH:$JAVA_HOME来引用 JAVA_HOME ,但如果是程序自己配置或者其他人配置的,这个就没法保障了。以前用 jdk8 的官方安装程序,貌似只会自动配置 PATH ,但不会配置 JAVA_HOME 的。其他版本的 jdk 没怎么用过,不清楚。shell 下面通过
env命令就可以列出所有环境变量的名称和值了,我排除环境变量的值是否有错误,经常用这个(shell 在不同运行模式下加载环境变量的顺序和位置都会有差异,命令行能正常调用的命令,jenkins 的 shell 下就是提示找不到,这个非常常见,需要用这个env命令列出所有环境变量的值供排查)。windows 不知道有没有类似的命令,其他人知道的话也可以分享下。 -
测试做算法题的意义是什么 at September 05, 2021
赞同 2 楼观点。我们的编程题很简单,把一个字符串按指定的符号转换为字典这种数据结构,大部分人不至于没有任何思路。考察的其实就是编码熟练程度,以及思维是否足够严谨(比如一些判空的点会不会遗漏)。
再者,测试作为一个技术岗,掌握一些技术岗要掌握的基础知识(数据结构、算法),也挺正常的吧。虽说大部分算法都被基础库封装好了,但有些特殊场景的算法还是得自己写的。比如通过遍历 xmind 所有节点获取测试用例数及测试结果统计,就需要懂遍历算法。有时候开发可能也会用一些算法,你不懂可能就看不懂开发逻辑,可能设计的测试用例就会遗漏一些重要的场景。
-
简历太糟糕找不到工作!!!!!! at September 03, 2021
从你这些回复看,你在测试这方面的工作经验接近于无,基本都是自学,没什么可列举的项目成果。
这种开发转测试,并且是通过找新工作转,是会很困难的。给几个小建议:
1、现有公司是否有机会转,有机会先在现有公司转,会方便许多。
2、稍微降低一些预期,外包也找个相对靠谱的去试试,先积累经验。一般非外包岗位,社招都是希望招到经验对标的、学习积极性强的,只有应届毕业生会相对不那么要求经验对标。没有实际工作经验和成果展示,这个始终是硬伤。
3、看你现有经历好像和图像识别算法之类的有关,如果确实有学到一定深度的话,可以项目里补充上你对这些算法的实际项目经验,试试一些大数据或者算法测试岗。这部分岗位有相关开发经验是很大的加分项。 -
软件测试怎么能提高研发的提测质量? at September 03, 2021
问几个问题:
1、最终质量上,有因为时间被压缩导致的线上故障什么吗?——如果有,可以借这个对上级多说下,原因是因为时间被压缩太厉害
2、研发周期长,是指经常超时提测吗?超时率多高?——这个看是否有项管或者这类管理项目进度的角色,没有就相当于你和研发的上级在关注,可以向这些干系人多反映下。这个情况我理解核心就是 1 楼说的,从上而下不重视质量这个观念是根本。多给上级和研发同级吹吹风,先思想上获得支持;然后是制度上,提测超时率(非需求变更引起)、提测打回率(提测后冒烟都跑不通的)统计一下,作为开发转正标准或者绩效的一部分,落到实处。
还有一个点,看研发团队里是否有一些比较有追求的人,自己会把控好自己工作的质量,这部分人可以多表扬,让大家多看到,让他们能发挥更大的影响力。
因为现在是理念上的差异,要改变要做好周期长、部分人消极应对、离职甚至反对的情况。所以得先和你的上级达成一致,才好继续往后推行。
-
基于 Jacoco 的二次开发【解决不同版本 exec 数据合并问题】 at September 02, 2021
这块没研究这么细。
-
简历太糟糕找不到工作!!!!!! at September 02, 2021
最后的工作经历有点没看懂,你最近这份工作做的是开发还是测试?项目描述像是专业做测试,但工作经历主要说的是开发,有点对不上号。
-
接口的性能测试应该怎么起步? at September 01, 2021
难道性能测试只能通过工具来做?
大部分情况下,用工具做会简单很多。写代码也可以,但你要写不少代码,比性能自动化多不少。而性能测试对于工具的要求其实比较通用,所以大部分工具本身可以满足,不需要从零写代码。
另外,性能测试工具,一般指的是发起压力的工具(如 jmeter)。实际完成性能测试,还需要监控排查的工具(如 jprofile、grafana)。你说的死锁什么的,要通过监控工具来找。
性能测试需要掌握一些什么?
你这个要了解的是 “性能测试怎么做” ,相当于一些基本概念和理论。楼上说了不少文章,可以去看看。
作为一个突然被告知做接口的性能测试的小白,有点不知道怎么下手了
想系统入门一个东西,不要靠搜索引擎。搜索引擎可以找到的是最热门的,但不一定是最系统的。一般技巧都是热门,但概念理论都不热门。所以你需要的是找一些系统点的课程或者书去学习。
-
小团队质量管理破局之路 (一篇来自 2019 年的笔记) at August 30, 2021
上次(2019 年)参加广州测试沙龙分享后最大的感触,就是大团队做的事情和我们小团队的很不一样
小团队做得好且愿意出来分享的真的很少。下半年广州计划再来一次沙龙,有兴趣来分享下么?
-
本人硕士应届生,想请教一下各位前辈,年轻时在一线城市大厂做测开拼搏赚几年钱,年纪大了以后去二三线城市的银行做测试,这条路好走吗? at August 28, 2021
这个我觉得不用担忧,你有一线大厂背景,不至于找不到工作,只是怎么找到适合自己(特别是薪酬待遇和发展空间)得花点时间。只是提醒一个点,要留意下除了使用大厂的提供的工具外,也留意下,即使不使用大厂给的,自己用外部开源工具也可以搞起来就行。一般外面其它中小厂面试大厂出来的,会特别关注这个。
另外,你如果后面计划是转开发,建议一开始就做开发。测开和开发虽然都会做开发相关工作,但测开关注的是整体方案和是否满足团队需要,要能给几百上千的测试团队乃至研发团队提效,相对更偏广度;开发会面临更多的系统复杂度和业务频繁变化挑战,要给千万甚至过亿用户提供服务,做到高可用和高性能,偏深度。两者往后走差别会越来越大。有可能到时候你的测开经历,到时候找开发岗位,会不如走开发好找。
不知道你 offer 是否会参与业务测试,还是专注做工具平台。如果是后者,估计你找业务测试也不一定好找,因为这方面经验比较少。有机会还是尽量也参与下业务吧,业务才是根本。
-
如何验证跨地域(城市/海外)网络对于服务的影响;qnet/云手机/找朋友帮忙各有利弊,期待更成熟方案 at August 27, 2021
从你的需求看,你不满足于模拟,对真实度要求很高。说实话,这么高的真实度,除了真实在那个地点有一个网点外,别无它法。然后手机能请求的,电脑一定也可以。这样就不局限于手机,可以看各家云厂商的机房都有分布在哪些城市的,在各个城市的机房都开一个虚拟机,当做当地网点。不过机房网络和移动网络的路由还是有差异的,无法真正做到一致。
但我觉得你是否可以换一个思路,不一定要主动发现(说实话,日活高的话,主动发现和监控发现差别也不过几十秒,甚至只要几秒。从发现问题角度,没啥差别,这几秒你也不可能完成回滚或者重新上线),而是在影响更小的情况下完成数据采集,以及快速响应解决问题?
如果按这个思路,数据采集可以这么做:
结合地域流量控制的灰度发布,只放指定城市(可以通过 ip 过滤)的 xx% 流量,看监控数据是否有波动预警解决问题可以这么做:
多准备几家 CDN 厂商,发布时同时发布。日常流量策略优先给在当地表现好的厂商,少量给表现一般一些的(作为监控手段),如果发现监控有问题,立马调整流量策略,增大到其他备份 CDN 厂商的比例。 -
各位大佬毕业后的一年能给小弟我参考参考吗 at August 27, 2021
还有后续吗?比如有找开发协助操作什么,开发有真的协助了吗?
-
各位大佬毕业后的一年能给小弟我参考参考吗 at August 27, 2021
你这个表达对于内部对背景情况啥的都清楚的可能有用,但对于对你经历一无所知的面试官或者外人,真的是一头雾水。。。比如为啥会有黑名单这个功能,使用场景是啥,要解决啥问题,和前端 Element-UI 框架又有啥关系?你这里只是一个 List 的循环,和你提到的
BFS 广度优先算法遍历节点作为引擎驱动各种 Action 事件,又有啥关系?你第二段介绍只是让问题增多,并没有解答疑惑。我们的 UI 自动化框架,有个设备白名单功能(别人做的哈,我只是拿来做示例),也很简单,只有白名单上有记录 udid 的设备才跑自动化,逻辑实现复杂度也不高。但要让其他人(比如面试官)能了解清楚,我会这么介绍:
S(situation,情景):随着 UI 自动化逐步推进,有的组已经建立起了 Jenkins 定时跑 UI 自动化的 job 。但由于目前自动化脚本主要适配的是固定机型(不同机型下 UI 布局会有一些变化,导致不稳定,兼容工作量不少,所以暂时先针对固定机型调优),而这个 Jenkins 有时候会接多个手机(有的用于跑 monkey,有的用于跑性能等)。当时 UI 自动化框架为了简便,driver 对象是自动生成,用例直接使用的。生成时会从已连接机器中随机选择对应平台的机器,缺少指定机器的能力,有时候会由于跑到了其他机器,UI 布局有差异,导致脚本不稳定。
T(task,任务):因此,经过和各个组沟通,确认通过设备白名单的方式提供这种能力。白名单可以让自动化框架只选择里面的设备运行,如果设备未连接,直接失败。
A(action,行动):在配置文件中,增加一个白名单配置项,类型为 list ,值为设备的 udid 。框架在初始化全局的 driver 对象前,增加一个确认是否有指定白名单的步骤。如果有,那就只使用白名单的。如果白名单只有一台,那就直接用。如果有多台,那就选里面有实际连上的其中一台。
R(result,结果):各组只需要增加一个配置项,和升级框架版本,就可以进行指定设备跑自动化,UI 自动化也不再出现由于跑在不同机器上导致不稳定的问题。 -
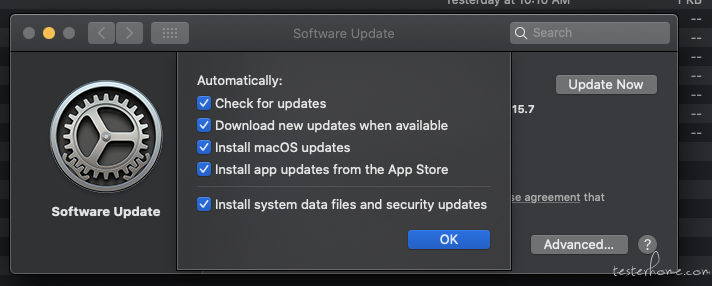
相对可以长期使用的阻止 ios 自动升级方法 at August 26, 2021
这个没研究过。不过我自己也用的 10.15.7 ,好像没怎么看到有升级弹窗骚扰。刚看了下,设置里好像可以关掉升级检查的,你可以试试?