-
docker && k8s 分布式压测 locust_boomer 方案 at October 16, 2020
你要明白一个问题,那就是为啥这里只有 max-rps 没有什么 min-rps 。。。
你说的
在 locust 中可以通过 Semaphore 来等待 2000 个 VU 起来boomer 不用等,开多几个 pod 开场就 2000 个 goroutine。。。
对于 go 来说,只要资源充足,你一开始就能直接产生 2000 个 goroutine,甚至能更多 。。。
--max-rps 是怕并发太多你系统撑不过来,用来限制协程并发数的。。。
你看看实现。
// Start to refill the bucket periodically. func (limiter *RampUpRateLimiter) Start() { limiter.quitChannel = make(chan bool) quitChannel := limiter.quitChannel // bucket updater go func() { for { select { case <-quitChannel: return default: atomic.StoreInt64(&limiter.currentThreshold, limiter.nextThreshold) time.Sleep(limiter.refillPeriod) close(limiter.broadcastChannel) limiter.broadcastChannel = make(chan bool) } } }() // threshold updater go func() { for { select { case <-quitChannel: return default: nextValue := limiter.nextThreshold + limiter.rampUpStep if nextValue < 0 { // int64 overflow nextValue = int64(math.MaxInt64) } if nextValue > limiter.maxThreshold { nextValue = limiter.maxThreshold } atomic.StoreInt64(&limiter.nextThreshold, nextValue) time.Sleep(limiter.rampUpPeroid) } } }() }你只要不设置
rampUpPeroidrampUpStep只设置maxThreshold资源充足的情况下马上就能触发这个逻辑。
if nextValue > limiter.maxThreshold { nextValue = limiter.maxThreshold }至于你说的
并发每隔一分钟来一次boomer 并发的是函数,你在函数结尾直接 sleep 一分钟,不就 2000 并发一次了吗。。。
-
录制线上流量做回归测试的正确打开方式 at October 15, 2020
具体例子已给出 ~ 见最佳回复
-
录制线上流量做回归测试的正确打开方式 at October 15, 2020

按日志格式造 request 实现不难,难的是把业务逻辑和规则融入进去,就比如你的第二个问题,才是第一个问题的核心。
举个例子:
线上日志
GET /product HOST prod.com PARAM token: old-token PARAM name: 1-prod-product发起 prod 请求前,复制一份到 test,更改 HOST 和 匹配规则
if host == "test.com" && "url == /product"匹配 替换类规则 RULE [1,2]RULE 1 代表登录类替换逻辑,若 PARAM 匹配到 token cookie ..., 替换成万能 token 或调用函数造 token。
RULE 2 代表关联类替换逻辑,若 PARAM 匹配到 name ... ,根据 get_product(host,token) 获取对应环境的值并替换。GET /product HOST test.com PARAM token: new-token PARAM name: 2-test-product然后同时发出,然后 diffy json(response_prod, response_test)
这里还可以做噪音匹配规则,这样对照组都能省,直接去噪。
比如增加 NOISE_RULE [1]
NOISE_RULE 1 代表通用类去噪音规则,diffy --ignore time, createtime, updatetime...最后,再借助 boomer 登记 diffy,就可以自己直接实现 diffy 归纳路由。
if diff := jsondiff.Diff(response_prod, response_test, diffopts.IgnorePaths([]string{"/time"})); diff != "": { boomer.RecordFailure("GET", "/product", 0, string(diff)) }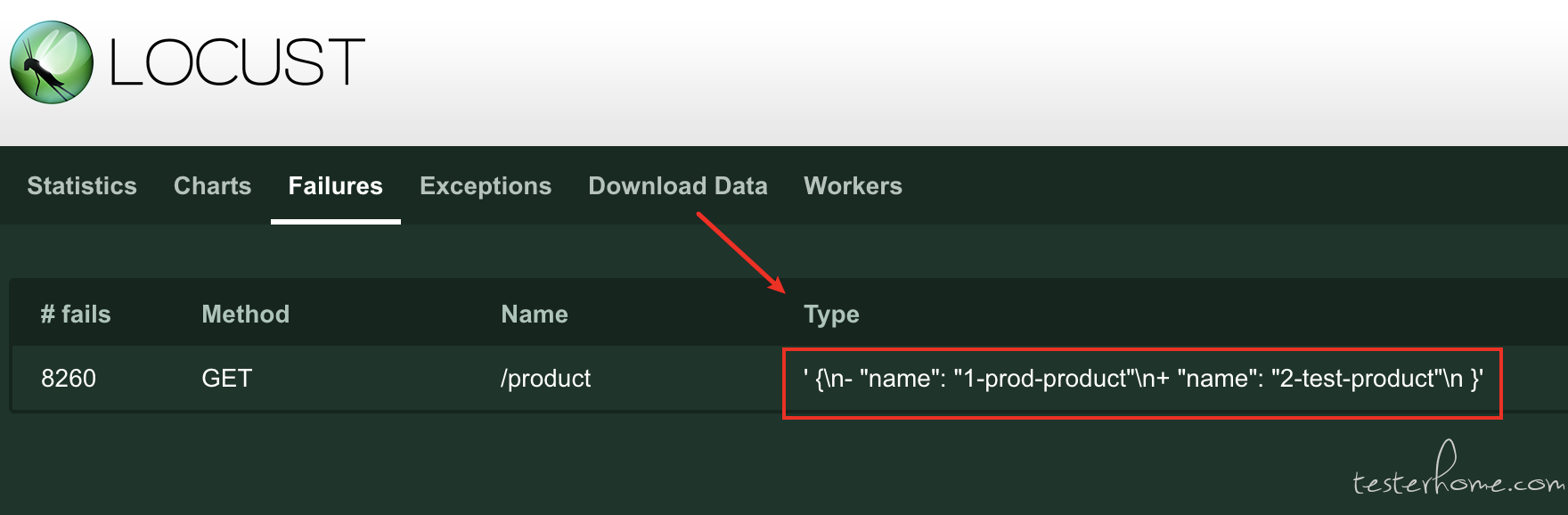
PS:
正确打开方式之前的两幅图,一个是 buger/goreplay 的回放,以及 opendiffy/diffy 的差异对比,这也是传统模式的
录制 + 回放,主要讲解传统模式录制 + 回放的原理,以及落地以后的一些缺陷。而后提出的优化,也是基于体验这个流程以后,弥补其中的一些不足,并提出优化实现方案。
-
录制线上流量做回归测试的正确打开方式 at October 15, 2020
可以理解为,把线上的流量录制成特定的日志格式,脚本是解析日志格式去发请求的,只要格式保持一致,就通用于大部分的项目。然后,涉及标记的动态数据得替换生成。
不过能理解成接口自动化 + 压测也对,原理都是把请求经过处理,同时对多个服务发出,并实时 diffy 响应。只不过一个是手写代码构造 request 一个是读线上日志构造 request。
-
docker && k8s 分布式压测 locust_boomer 方案 at October 15, 2020
boomer 里面直接就是协程并发跑函数了。
你可以设置 --max-rps = 2000 ,然后再在 task 函数结尾 time.Sleep 一下。 -
docker && k8s 分布式压测 locust_boomer 方案 at October 15, 2020
有,通过 --max-rps 控制
-
录制线上流量做回归测试的正确打开方式 at October 15, 2020
是啊。
其实我最后想表达的意思是,我们不应该只局限于
录制 + 回放这两个组合,能实现同样测试效果的组合,为什么不能组合使用呢?比如:
- 录制 + 规则校验(所需数据不同的测试,通过规则校验来实现)
- 造数据 + 回放(既然是我造的数据,又不是录的生产数据,那我 POST PUT DELETE 完全没毛病)
甚至可以两者按需组合。
-
录制线上流量做回归测试的正确打开方式 at October 14, 2020
是的,录制的限制太多了,所以用脚本快速构造流量,只追求 diff 的实现。

-
录制线上流量做回归测试的正确打开方式 at October 14, 2020
截图里面不是很清楚的有get /ping1么,header或者url里面不能直接拿得到吗diffy 设计里面不以 url 来归纳的,毕竟参数不同,所以是通过人为在回放前,自己在回放流量的 header 里面增加 Canonical-Resource 来实现归纳。
你测试新版版,不是以老版本的response作为对比的基准么,我是说接口入参改了新增了一个入参userId,老版本的response就不可靠了,这种情况不适用主要是看有哪些 diff,比如这个就是我想要的 diff,我要看的是,除了我预计之外的 diff,有没有什么我没有预计到的 diff,而不是追求没有 diff 。
-
录制线上流量做回归测试的正确打开方式 at October 14, 2020
没懂你想要干嘛?你改了是生效在新版本的,为啥还要让改动在老版本生效?你只能说改完大不了回放在旧版本里面会返回 error ,那也算 diff。
归类是同一个路由的归类,不带任何参数的归类。
-
录制线上流量做回归测试的正确打开方式 at October 14, 2020
简而言之,就是你后端服务的前后迭代,不需要前端去更改业务调度逻辑和更改接口的,都能用。或者,你只要确保同一个请求,传入的参数(比如一些随机生成和查数据库传入的不同的值)在前后版本都有逻辑可以处理,也能用。
-
录制线上流量做回归测试的正确打开方式 at October 14, 2020
本质上是 diff 接口,你接口路由不改,新旧版本都有解析路由参数的逻辑,都能用。要是你接口路由都改了,那就没有可比性了,都不是一个接口了。另外,这个主要是在接口路由不改的情况下,来快速测试一些优化代码版本,或者重构代码版本,或者升级架构如 rpc 版本的快速回归测试。
-
录制线上流量做回归测试的正确打开方式 at October 14, 2020
就是新旧版本的镜像对比,以旧版本镜像为基准,对比新版本镜像 response 的 diff。
-
录制线上流量做回归测试的正确打开方式 at October 13, 2020
-
为什么要做自动化? at October 12, 2020
可以做成录制抓包,然后自动转成 api 文档
-
致敬恩师,# 感谢你,那个当年带我入门的人!# 活动火热开启 at September 11, 2020
野路子型。。。
-
对容器云平台进行压测,大家有什么好的想法吗 at August 25, 2020
是鸭 hhh 太懒了好久没写 gitchat 了
-
对容器云平台进行压测,大家有什么好的想法吗 at August 25, 2020
-
[北京 / 杭州] BAT.TMD-新项目 招聘 测试开发 (测开紧急,要求放宽) at August 20, 2020
秀儿请坐
-
Go macaron (马卡龙) 库 (一) at August 12, 2020
赞~
-
Go macaron (马卡龙) 库 (一) at August 12, 2020
这个是用来写服务器吗,跟 gin echo 有什么区别吗
-
一次性能压测及分析调优实践 at August 06, 2020
赞~
-
如何提高 Locust 的压测性能 at August 05, 2020
并发用户数只是个压力线程,具体 Tps 根据公式来算。
连接数就是系统吞吐量(或者性能?)的一个衡量方式。
具体 pool 和 nonpool grpc 与 http 压测分析在: https://testerhome.com/topics/24967
-
如何提高 Locust 的压测性能 at July 31, 2020
问下 grpc 加池的意义?我测了一下,不加池原生的 grpc 连接,产生的 tps 会更高,加池限制了池大小,就算调好参数,也没有直接创建新连接来的那么快,因为 pool.put 在持续并发里面有点浪费时间。所以同等数量的压力线程,不加池发出的 tps 远超加池。
-
docker && k8s 分布式压测 locust_boomer 方案 at July 28, 2020
---------------- 2020.07.28 更新 ----------------
1.提供 grpc 压测的 docker-compose 部署方案。
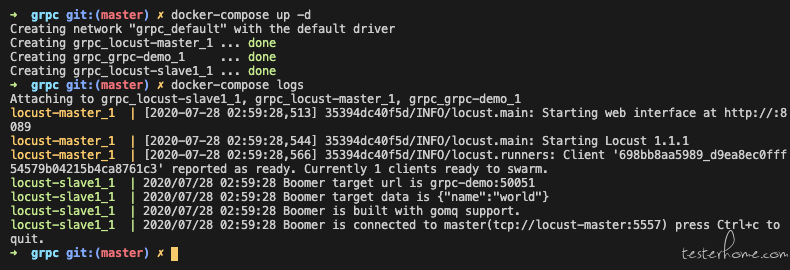
2.提供 shaonian/grpc-demo, shaonian/locust-slave-rpc 开源镜像。
locust-slave1: image: shaonian/locust-slave-rpc:latest command: - ./helloworld.pb - --master-host=locust-master - --master-port=5557 - --url=grpc-demo:50051 - --data={"name":"world"} links: - locust-master - grpc-demo3.优化 github README 文案。