【关键导读】
结合一次重保活动的性能压测需求,详解了整体的性能测试策略及性能分析思路,并在实施过程中有效利用了 NPT 性能测试平台完成了压测场景设计、执行、业务指标监控、性能指标分析,结合监控找出了性能瓶颈并给出了相应的性能优化解决方案
0.背景说明
A 业务有大促活动,对 B 业务有依赖,要求 B 业务对于 X 场景能够持续稳定支撑 1.4w TPS 5min, 如此要对 B 业务进行性能压测,完成对应的性能需求。
1.性能测试策略
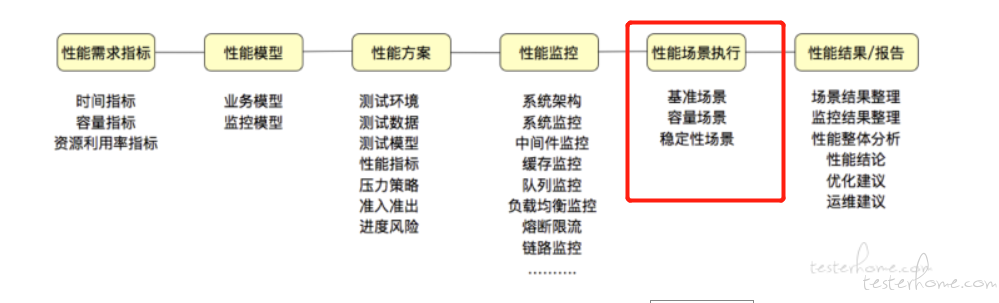
如下所示,接下来按照这个思路去分析下整个性能测试实践的流程。
1.1 性能需求指标
容量指标:X 场景支撑 1.4W TPS 持续 5min
1.2 性能模型建立
【业务模型】
涉及的场景包含 A-》B-》C-》D 共 4 个接口,按照真实业务分析流量比例为 3:1:1:1
【监控模型】
监控对象
– 测试活动中的所有服务器,测试机、应用服务器、数据库服务器、缓存服务器、依赖服务等资源监控
– 所有被测的应用服务监控,Nginx、tomcat、MySQL 等。

监控内容
业务指标:吞吐量、响应时间、失败率
资源监控:CPU、内存、磁盘、网络、IO
日志信息:错误、异常、关键业务日志
进程监控:CPU、内存、进程状态、线程状态
一个典型的 linux 性能监控工具图:
1.3 性能方案设计
测试环境:线上真实业务集群
测试数据:场景是从客户端 APP 发起调用接口,考虑到线上数据样本不涉及隐私及敏感数据且可以复用,不会对用户造成数据污染。故从线上捞取了 100 万用户数据样本。
压力策略:
1)先摸高,按照一定的线程递增策略,根据预期目标是否有性能瓶颈
2)峰值容量持续压测,观察系统的承受及处理能力
2.性能测试执行及分析
利用 NPT 性能压测平台完成整个性能压测活动https://www.163yun.com/product/npt?fromyice=M_testerhome_25016
2.1 容量场景:TPS 摸高
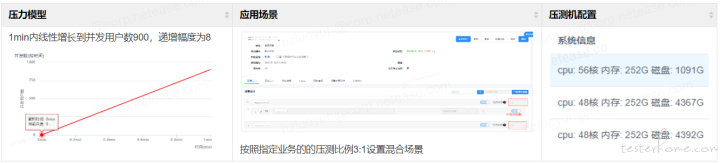
经过压测在 NPT 平台中压测后的 TPS-RT 曲线如下
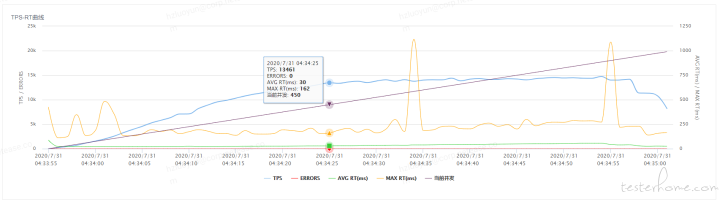
接下来按照性能分析的典型思路给大家逐一介绍下:

【瓶颈的精准判断】
很多情况下,在分析系统性能瓶颈的时候,我们总是想找到性能瓶颈的那个 “拐点”,但是实际上大部分系统其实是没有明确的拐点的。在实际操作中需要按照固定递增幅度增加并发线程数,进而对于 TPS 的增加控制得更为精准,实际业务中 TPS 的增加是有一个有清晰的弧度,而不是有一个非常清晰的拐点。
从上图业务真实 TPS-RT 曲线中可以做出以下判断:在线程逐步递增的过程中,TPS 按照固定比例上升与线程数呈现线性增长,达到一定的压力的情况下,TPS 的增长幅度在衰减,最后逐步趋于平稳。以此可以判断出业务在一定的压力情形下出现了性能瓶颈。为了更加清晰判断性能瓶颈,接下来分析下性能衰减的过程。
【性能衰减的过程】
所谓的性能衰减可以通过每线程每秒请求数在逐渐变少来反应,即使 TPS 仍在增加,如下针对压测业务采用 3 个点,计算每线程每秒请求数
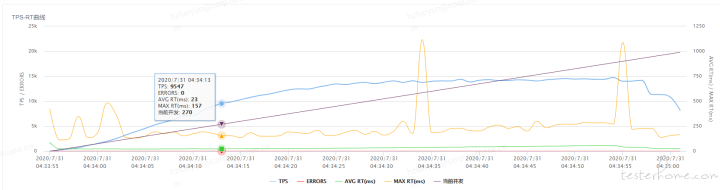
采样点 1:每线程每秒请求数=9547/270=35.3
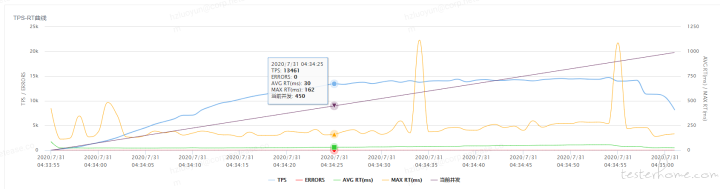
采样点 2:每线程每秒请求数=13461/450=29.9
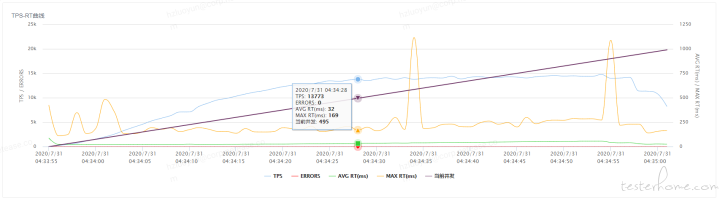
采样点 3:每线程每秒请求数=13773/495=27.8
由此可以得到如下结论
只要每线程每秒的请求数开始变少,就意味着性能瓶颈已经出现了。但是瓶颈出现之后,并不是说服务器的处理能力(这里我们用 TPS 来描述)会下降,应该说 TPS 仍然会上升,在性能不断衰减的过程中,TPS 就会达到上限。
在这个场景的测试过程中,在性能瓶颈出现后,继续保持递增的压力,让瓶颈更为明显,可以看如下 TPS-RT 的曲线,我们会更加清晰的看到压力还在逐步增加,但 TPS 已经趋于平稳,而平均 RT 却在不断上升
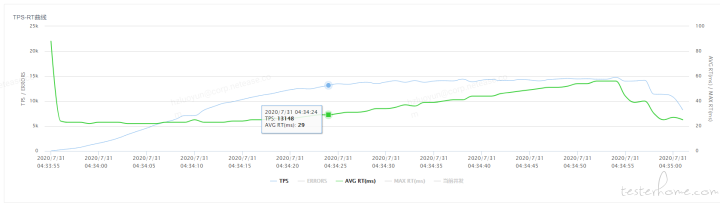
【响应时间的拆分】
基于性能瓶颈的出现,接下来就需要分析在性能瓶颈出现时,哪个链路耗时增加明显导致请求 RT 变长。那么首先需要做的是画出请求的整个业务链路。这里的策略是:先粗后细,先从较粗的粒度划分,确认耗时较长的链路节点,然后再细分粒度可能到某个方法。我们先来看一个典型的响应时间 RT 的分布链路
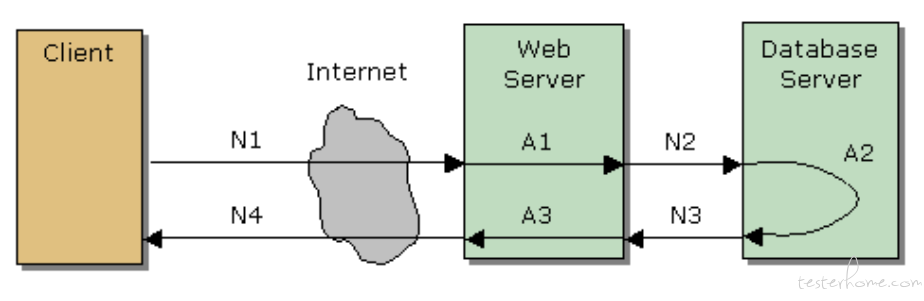
响应时间 = (N1+N2+N3+N4)+(A1+A2+A3),一般我们优先关注的是 A1、A2、A3,对于网络传输处理,在这里优先默认它表现良好
基于业务场景的链路:

第三方依赖服务采用了 hystrix 降级熔断组件实现了独立线程池隔离调用。
1)首先要排除发压端是否有瓶颈,查看发压端服务器监控,CPU 利用率和负载都还不到 10%
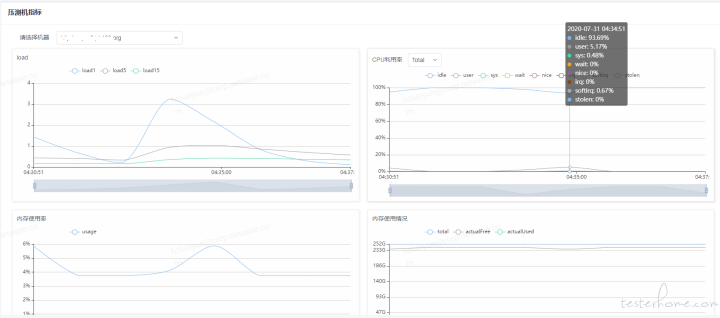
压测机指标
2)分析下调用第三方依赖服务的平均 RT,对比如下
单应用实例 20 并发 平均 rt 19.25
单应用实例 50 并发 平均 rt 38.25
由此看来在并发用户数一直往上增时,调用第三方依赖服务 RT 上涨明显,进而初步需要排查的是第三方依赖服务在大并发用户数下的处理能力,并发用户数增加,处理能力下降,导致 RT 边长
这里优先说下在第一轮性能压测时发现的问题并调整,同样是 TPS 摸高,从下图可以看出 TPS 还未达到性能瓶颈时,已经出现失败请求
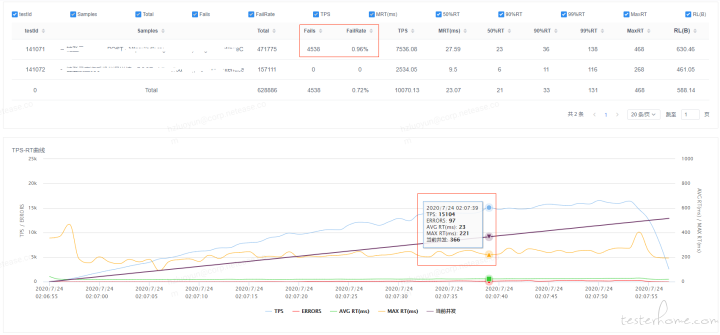
经过分析调用第三方的线程池被打满抛异常,采用的 hystrix 实现的业务降级熔断,配置了独立的线程池,线程池配置为核心和最大线程数为 20,队列为 0
异常日志:
Task java.util.concurrent.FutureTask@66339c68 rejected from java.util.concurrent.ThreadPoolExecutor@303bf923[Running, pool size = 20, active threads = 20, queued tasks = 0, completed tasks = 2071934]
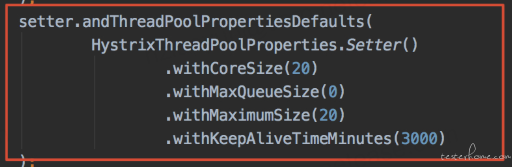
代码实现配置如下,进而优化调整线程池,核心线程数和最大线程数都调整为 50
【构建决策分析树】
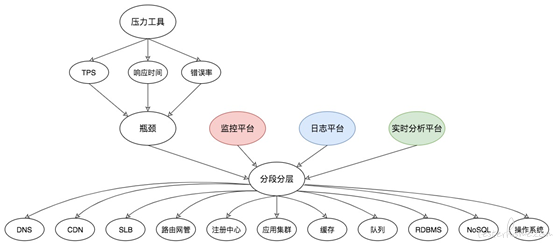
从压力工具中,只需要知道 TPS、响应时间和错误率三条曲线,就可以明确判断瓶颈是否存在。再通过分段分层策略,结合监控平台、日志平台,或者其他的实时分析平台,知道架构中的哪个环节有问题,然后再根据更细化的架构图一个一个拆解下去。因为这里业务很明显找到了影响 RT 变长的原因,在此没有进一步分析下去。
2.2 峰值稳定性压测
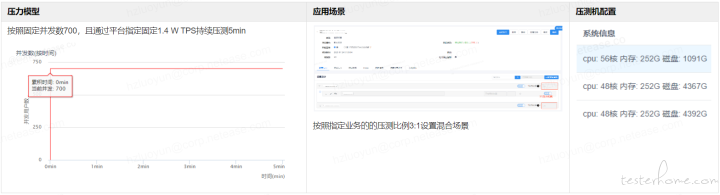
性能压测模型及场景设计
【性能分析】
针对 precheck 压测恒定压力 1.4W 持续 3min 后,中间突然 TPS 陡增,初步分析是因为服务器端口耗尽了,看了下 TCP 连接状态,大量 Time_wait,调用第三方依赖服务接口监控中可以看到对应时间点开始抛异常
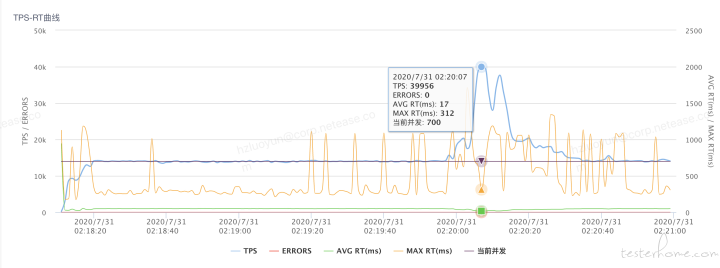
峰值稳定性场景:TPS-RT 曲线
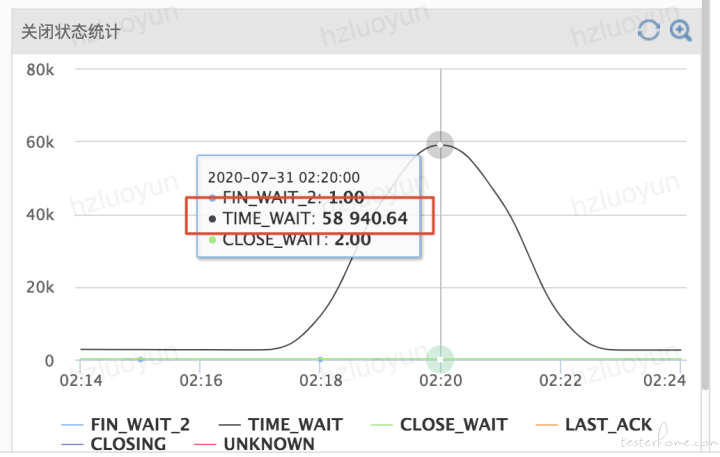
TCP 状态监控
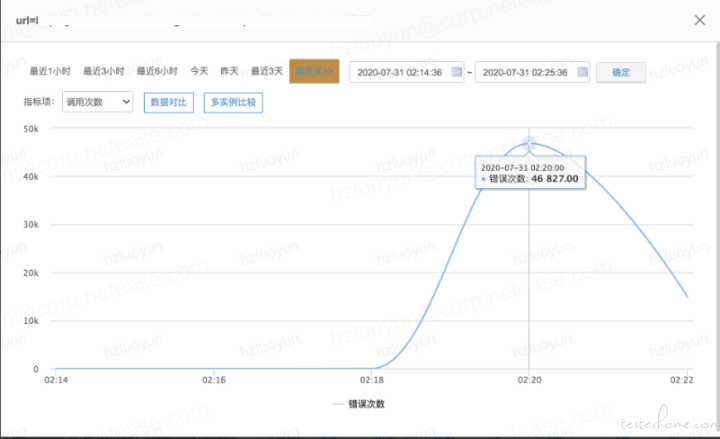
错误次数监控

连接异常堆栈信息
看了下服务器的相关配置,对于端口的回收、复用、超时都未进行优化配置
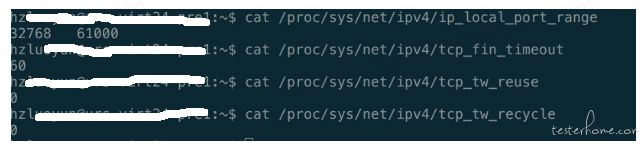
性能优化解决方案:
1)调整应用服务器对于端口的回收、复用、超时进行优化配置
2)将 B 业务作为客户端调用第三方依赖服务的连接改为长连接,避免短连接每次请求都会占用一个端口
扩展延伸
几种典型的异常波动:
• tps 持续下降
• tps 频繁波动
• tps 陡升陡降
• tps 剧烈下降
在此感谢下一位性能测试专家 - 高楼的一些关于性能测试方向的总结思考,实践过程中有借鉴其思路
【关键总结】
性能测试是针对系统的性能指标,建立性能测试模型,制定性能测试方案,制定监控策略,在场景条件之下执行性能场景,分析判断性能瓶颈并调优,最终得出性能结果来评估系统的性能指标是否满足既定值。