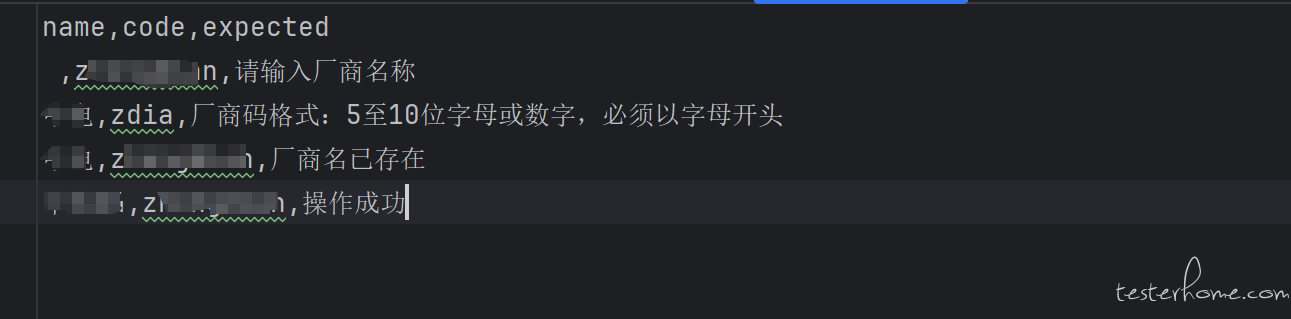
问答 python 读取 csv 文件出现解码失败,请问这是什么原因呢,求指点
打开文件时指定了 encoding='utf-8',但是运行脚本还是出现了报错,尝试用记事本另存查看 CSV 文件的真实编码也是 UTF-8 以及添加错误处理参数(errors='ignore'),运行还是出现相同的问题,有小伙伴遇到类似问题的吗,求指点~

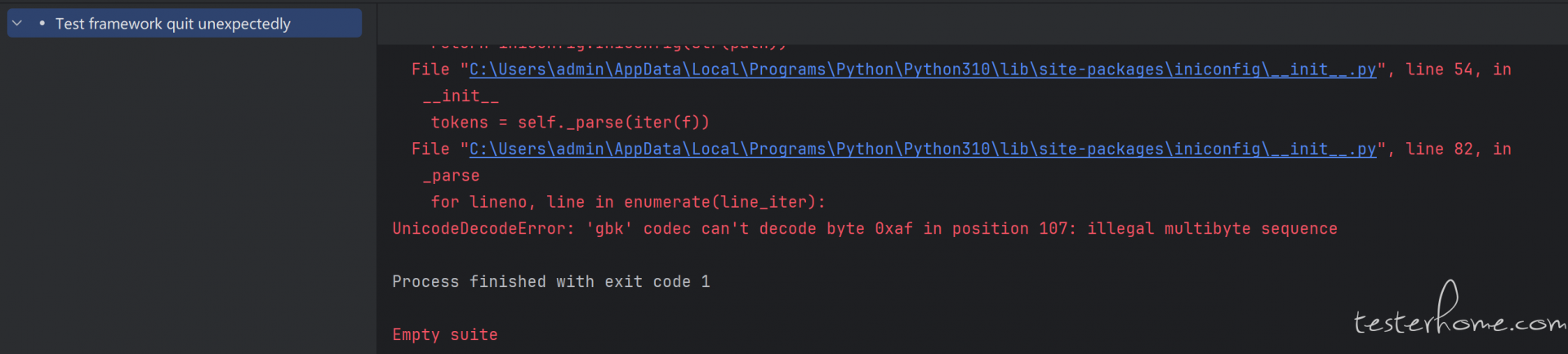
再次尝试读取文件使用绝对路径,并使用 chardet.detect() 获取文件实际编码,将检测到的编码应用到文本读取模式中,还是出现了相同的问题。

打开文件时指定了 encoding='utf-8',但是运行脚本还是出现了报错,尝试用记事本另存查看 CSV 文件的真实编码也是 UTF-8 以及添加错误处理参数(errors='ignore'),运行还是出现相同的问题,有小伙伴遇到类似问题的吗,求指点~
再次尝试读取文件使用绝对路径,并使用 chardet.detect() 获取文件实际编码,将检测到的编码应用到文本读取模式中,还是出现了相同的问题。