问题发现
中午同事过来反馈测试平台的某个执行计划一直处于执行中,但是无结果返回。起初不以为意,认为和前天一样是某个测试用例出现脏数据导致,遂去看后台日志,发现并无报错。
鉴于过往总是被坑,便不死心让同事将计划下的每个测试集合都单独执行一遍,均无问题,此时有些疑惑,但仍认为和平台无关,系使用问题。查看过往执行记录,发现昨日还是好的,首次出现无法执行在今日凌晨。
问题排查
于是不得不再次本地启动引擎,添加控制台输出,进行观察。发现任务创建后,要过三四十秒才被执行,一开始我认为是任务调度问题,但本地引擎本身并未有其他执行任务。一头雾水下再去看引擎控制台,结果又发现执行任务下发成功后引擎并未收到,最后查看引擎执行日志才看到连接超时。而超时时间我设置了 30s,一个三百多条用例的执行计划没有道理会要这么长的任务计算时间,这种奇怪现象是平台上线三年来首次遇见。
本着先恢复使用的原则,我先调大了任务获取的超时时间。又再三确认同事昨天并未修改测试用例后,便开始仔细回顾昨天自己对于平台的操作,看看是否会影响任务下发时间变长。
而昨日我只做过两件事,一是昨日下午清理了一张有 175G 的测试报告表,并使用 OPTIMIZE TABLE 语句进行重整理(虽然执行失败),但是该表在上传报告才会使用,下发任务理论上不会影响。
二是昨晚上线一个新功能,将原有的 case 表中的 tags 字段,转存到 case_branch 表中,因为平台兼容了一些原来的自动化代码用例,而自动化代码有分支管理,所以 case 表对于 case_branch 表数据是一对多的关系。但平台自身的测试用例没有分支管理,走的代码逻辑也不同,我也并未修改此处代码,况且 case_branch 表是其他同事因另一个需求加的,在上周就已经上线,我只是复用了该表,因此断定与本次发版内容也无关系。
那么究竟问题出在哪,我陷入迷茫,甚至一度怀疑是否昨天清理表数据搞坏了数据库。就这样纠结半小时后,突然想起来报问题的同事说,任务下发变慢有好几天了。于是我又从下发任务过程开始逐步排查 sql 执行日志,最先发现的是某个每秒执行的定时任务有个 sql 较慢,耗时 0.45s 左右,本着尝试原则,调大了定时任务周期,但于事无补。
于是继续排查,又发现任务计算过程中,获取用例详情的 sql 竟需要 0.1s,那三百多条用例可不就要三四十秒。但以前并未有这个问题,昨日也未修改该 sql 相关的内容。去看 git 中该 sql 的修改记录,发现该 sql 上周修改过,正是其他同事在发布 case_branch 表时修改的,修改内容如下:
# 修改前
select xx from case c where c.id=#{id}
# 修改后
select xx from case c
left join case_branch cb on cb.case_id=c.id
where c.id=#{id} limit 1
前面说过,case 表对于 case_branch 表是一对多的关系,因此即便用主键查询,也会返回多条,所以为了结果唯一性,又加入了 limit1。那为何此处会影响性能,又为何在刚上线没有影响呢。
我又去看了这两个表的数据,发现 case 表不过一万多条数据,而 case_branch 表有二十七万条数据,这样一对多的连接,从而导致了查询性能变差。如果去掉此处表连接,那么查询时间仅需 0.005 秒,性能差了几十倍。
那又为何直到今天才会引起明显的性能问题呢,其实也和昨天上线有一定关系。上线后我对 case_branch 表刷了数据,原本同事上线后该表只有几千条数据,而我因为另一个功能需要记录更多的数据,从而导致该性能问题最终在今天暴露。
问题解决
后续让同事重新写了新的 sql,还原了这条 sql,因为他用这条查询 sql 是针对极少数的特有数据,且处理逻辑不同,因此单条 sql 即使在 0.1 秒也能接受。
重新上线后,再次执行该计划,果然在一秒多就完成了任务计算并下发,至此问题得到解决。
是什么样的魔鬼数据结构设计才会让你在 OLTP 应用里面敢随便用 left join 的
遇到这种问题我第一反应就是干死这种 sql,干不死就要重新设计数据结构
主要是测试平台出了报告相关的表,数据量都不会太大,而测试平台本身对实时性要求也没那么高。
而表结构设计我认为本身问题也不大,或许有更好的设计,但是正常是满足使用的。
这个问题主要还是协作问题,没有注意到其他人修改了这个 sql。
获取用例详情的 sql 竟需要 0.1s,那三百多条用例可不就要三四十秒
这个不能批量查么,怎么看着是循环去查的
老代码了,确实不该在循环里查询的,因为这块代码特别多,而且处理的数据也很复杂,一直懒得优化。
另外如果批量查询,遇到一个计划上万条 case 的情况,对内存消耗也会很大。单个主键查询其实是很快的。
测试平台可能找不到什么问题,但是容易爆发问题,改完测试平台的问题也计不上任何功劳
我们的测试平台逻辑是用户点击执行或者定时触发执行的时候服务端异步查询所有用例数据并解析成 json 数据储存到文件,然后由专门的定时器分发任务 ID 到空闲的执行客户端,客户端通过 HTTP 拉取执行数据文件并解析执行。
问一下 AI 就知道了,LEFT JOIN 的作用一般来说仅在于 返回左表所有行,右表部分无匹配,帖子里的场景 case_branch,起码会有个 main、master 或 base,必然会有匹配(如果没有,那就是数据结构问题了),为啥要用 LEFT JOIN?
在联表查询中,INNER JOIN 和 LEFT JOIN 的效率对比需结合具体场景分析,但通常 INNER JOIN 效率更高,原因如下:
1. 结果集大小
- INNER JOIN:仅返回匹配的行,结果集更小。
- LEFT JOIN:返回左表所有行(即使右表无匹配),结果集可能更大。处理更多数据会增加内存和计算开销。
2. 索引与过滤
- 若连接键有索引,两者效率接近。但若右表无匹配时,LEFT JOIN 需额外处理 NULL 值,可能略微增加开销。
- 若右表无索引,LEFT JOIN 可能触发全表扫描,导致性能显著下降。
3. 执行计划优化
- 数据库优化器可能将 LEFT JOIN 转换为 INNER JOIN(当左表所有行在右表均有匹配时),此时效率相同。
- 但若优化器无法确定匹配情况,LEFT JOIN 可能选择保守执行计划(如哈希连接),增加内存使用。
4. 数据分布影响
- 若左表大部分行在右表有匹配,两者效率差异较小。
- 若左表大量行在右表无匹配,LEFT JOIN 因处理更多 NULL 值而更慢。
总结
- 优先选 INNER JOIN:若只需匹配数据,效率通常更高。
- 谨慎用 LEFT JOIN:仅在需要保留左表所有行时使用,并确保右表连接键有索引。
- 实际验证:通过 EXPLAIN 分析执行计划,观察是否触发全表扫描或低效操作。
-
示例:若左表有 1000 行,右表有 100 万行且无索引:
- INNER JOIN 可能通过索引快速过滤,仅匹配少量数据。
- LEFT JOIN 可能需扫描右表全部 100 万行,导致性能骤降。
GPT o1 模型给出的答案,似乎不是很认可总结中的示例
在 mysql 中,这个说法有道理吗
示例:若左表有 1000 行,右表有 100 万行且无索引:
INNER JOIN 可能通过索引快速过滤,仅匹配少量数据。
LEFT JOIN 可能需扫描右表全部 100 万行,导致性能骤降。
简短回答:
那种 “一旦用 LEFT JOIN,MySQL 就会被迫扫右表全部数据,而用 INNER JOIN 就能快速过滤只读少量数据” 的说法往往是过度简化甚至不准确的。具体是否要扫右表所有行,取决于是否有可用索引、连接条件、以及优化器能否调整执行计划等多重因素,而不只是句型(LEFT 还是 INNER)本身。
为什么会出现这种说法?
-
连接顺序受限
- 对于
INNER JOIN,MySQL 优化器通常可以自由地对多表进行 重排(reorder),选择最优的连接顺序(也就是决定谁先作为驱动表、谁后作为被驱动表)。
- 对于
LEFT JOIN,逻辑上要求 “左表中的每一行都必须出现在结果集中”,所以 MySQL 不能随意重排,必须先读取左表,再去匹配右表。
- 在极端情况下,如果左表很小、右表很大,但是因为没有合适的索引,导致对右表的匹配只能全表扫描,就会出现性能问题;而如果是
INNER JOIN,有时优化器能把 “大表” 放在前面过滤掉大部分无关行(或用其他执行策略),从而减少总的扫描量。
- 对于
-
没有索引时的 Nested Loop Join
- MySQL 常用的执行方式是 嵌套循环连接(Nested Loop Join):对 “驱动表” 的每一行,去 “被驱动表” 中找出匹配的行。
- 如果没有索引,就只能对 “被驱动表” 做全表扫描,这样会非常耗时。
- 由于
LEFT JOIN限制了连接顺序,可能导致大表总是放在后面被 “一行一行” 地嵌套查找,性能糟糕。
- 但是,如果两张表都没有索引,实际上无论是
INNER JOIN还是LEFT JOIN,都可能导致大量扫描,不见得一定是谁就一定更快。
- MySQL 常用的执行方式是 嵌套循环连接(Nested Loop Join):对 “驱动表” 的每一行,去 “被驱动表” 中找出匹配的行。
实际上该怎么理解?
-
是否能用到索引才是关键
- 只要在右表(无论你是
LEFT JOIN还是INNER JOIN中被当作 “被驱动” 一方)上的连接字段上建有索引,通常就能利用该索引快速定位匹配行,而不会傻傻地扫整个大表。
- 如果右表真的 “没有任何合适的索引”,那么即使是
INNER JOIN,也有可能被优化器选成 “左表” 的角色——然后对另一张表做多次的全表扫描,同样卡得飞起。
- 只要在右表(无论你是
-
优化器对
INNER JOIN和LEFT JOIN的选择空间不同-
INNER JOIN时,MySQL 通常可以根据代价估算,动态调整表的读取顺序以及连接方式,因此有时可以 “先扫大表并过滤掉无效行” 或 “先扫小表做索引查找” 等等。
-
LEFT JOIN时,原则上必须保证左表所有行都会输出(包括右表匹配不到时的NULL),因此 MySQL 在决定执行计划时,不能把右表排到前面 去先做过滤。
- 这就导致某些场景下确实会出现:同样的两张表、同样的连接条件,用
INNER JOIN相对更快,而LEFT JOIN可能会慢。
-
-
有没有外部过滤条件、统计信息等
- 如果结合了其他
WHERE条件,或者联结字段有不同的选择性,优化器就可能采取完全不同的执行策略。
- 另外 MySQL 优化器会根据统计信息估算 “有多少行能够匹配” 来决定执行计划,一旦统计信息不准确,执行计划也可能跑偏。
- 如果结合了其他
经验和建议
-
给连接列加上合适的索引
- 这是最重要、也是最通用的建议。只要你的连接列上有索引,再大的表,通常也不会出现 “全表扫描 + 嵌套循环” 的最糟糕情况。
- 有索引后,无论
LEFT还是INNER,都比较容易走到比较高效的执行路径。
- 这是最重要、也是最通用的建议。只要你的连接列上有索引,再大的表,通常也不会出现 “全表扫描 + 嵌套循环” 的最糟糕情况。
-
尽量用能表达业务需求的 JOIN 类型
- 如果你的业务确实需要 “即便右表无匹配也要保留左表行”,那就用
LEFT JOIN。
- 如果只关心匹配到的行,用
INNER JOIN就可以。不要为了 “也许会快一点” 而改动语义。
- 如果你的业务确实需要 “即便右表无匹配也要保留左表行”,那就用
-
分析执行计划(EXPLAIN)
- 不要只看 “LEFT JOIN” 和 “INNER JOIN” 就猜测性能好坏。最好使用
EXPLAIN看实际的 “各表的读取顺序”“是否用到索引”“预估的扫描行数” 等。
- 如果发现某些表走了全表扫描,或连接顺序很不合理,就可以通过建索引或者优化写法来改善。
- 不要只看 “LEFT JOIN” 和 “INNER JOIN” 就猜测性能好坏。最好使用
-
注意 MySQL 版本
- MySQL 的优化器在不断演进;老版本里,它不会做 “哈希连接” 或 “BKA(批量索引访问)” 之类的高级优化,主要是基于嵌套循环。
- 新版本则可能引入更多执行策略,某些场景下就算是
LEFT JOIN,MySQL 也能做得不错。
- MySQL 的优化器在不断演进;老版本里,它不会做 “哈希连接” 或 “BKA(批量索引访问)” 之类的高级优化,主要是基于嵌套循环。
小结
-
在没有任何索引的场景下,确实有可能出现 “
LEFT JOIN很慢、INNER JOIN快不少” 的情况,但它更多是执行计划和索引缺失的问题,而不只是字面上的 “左连接一定会扫右表”。
- 真正要避免性能炸锅,最好在连接列上建索引,并通过
EXPLAIN确认优化器是否走到了正确的索引访问路径。
- 不要盲目地因为一两次测试就认定 “以后都用 INNER JOIN 才快”,那样可能会掩盖真正的问题(缺索引,或写法不当),也可能错误地改变了查询的语义。
https://chatgpt.com/share/67f29f7e-38a8-800b-91bf-dda853d03fe0
这种为了杠而杠的问题,针对性太强了,GPT 显然在扮演理中客,强行否定……甚至为了杠而假定出对方说过某个错误言论,比如:
那种 “一旦用 LEFT JOIN,MySQL 就会被迫扫右表全部数据,而用 INNER JOIN 就能快速过滤只读少量数据” 的说法往往是过度简化甚至不准确的
“一旦用 LEFT JOIN,MySQL 就会被迫扫右表全部数据” 这句话谁说的呢?
在我看来,或许 GPT 连 “可能” 和 “一旦” 都理解不清楚,就没必要参与中文的逻辑解答了,要不你问问它 “INNER JOIN 和 LEFT JOIN 有什么区别”,看它怎么回答呢?
额外说一句,用任何厂家的 AI,问问题的时候都不要带上倾向性甚至拉踩的方式,不然你得到的答案慢慢的、越来越接近你已经知道的信息,这是自己给自己创造信息茧房,而且这些 AI 很容易被 “投毒”,使用时更需小心。比如你要问:“格力空调比大金空调好在哪里”,不如问 “格力空调和大金空调各自有什么优缺点”。你预设了自己想要的答案,他们就会变成一种新的竞价排名工具……
首先,没有任何抬杠的意思;因为回答中说了问 AI,我就顺手问 AI。
仅仅是复制了原文给 gpt,让它来判断。因为我确实不知道这两者的区别,也不知道这个结论的正确性。
另外,我不确定你说得抬杠是我抬杠,还是 gpt 抬杠。
实战结果
实践出真知,那就跑起来吧。
先说结论
有索引的情况下
耗时绝对值都是比较小的。
INNER JOIN 执行时间: 0.0093 秒
LEFT JOIN 执行时间: 0.0078 秒
性能差异: LEFT JOIN 比 INNER JOIN 慢 0.84 倍
无索引情况
无索引 INNER JOIN 执行时间: 0.2907 秒
无索引 LEFT JOIN 执行时间: 24.5531 秒
无索引性能差异: LEFT JOIN 比 INNER JOIN 慢 84.47 倍
$ python test_inner_join_left_join.py
数据库创建成功
表结构创建成功
正在生成左表数据...
左表已插入 0 行
...
左表数据生成完成:1000行
正在生成右表数据...
右表已插入 10000 行
....
右表已插入 980000 行
右表已插入 990000 行
右表已插入 1000000 行
右表数据生成完成:1,000,000行
为右表的join_key添加索引...
索引添加成功
测试 INNER JOIN:
执行计划分析:
(1, 'SIMPLE', 'l', 'ALL', 'join_key', None, None, None, '1000', 'Using where')
(1, 'SIMPLE', 'r', 'ref', 'idx_join_key', 'idx_join_key', '5', 'test_inner_join_left_join.l.join_key', '50', '')
INNER JOIN 匹配记录数: 100051
INNER JOIN 执行时间: 0.0093 秒
测试 LEFT JOIN:
执行计划分析:
(1, 'SIMPLE', 'l', 'ALL', None, None, None, None, '1000', '')
(1, 'SIMPLE', 'r', 'ref', 'idx_join_key', 'idx_join_key', '5', 'test_inner_join_left_join.l.join_key', '50', 'Using where')
LEFT JOIN 匹配记录数: 100051
LEFT JOIN 执行时间: 0.0078 秒
性能差异: LEFT JOIN 比 INNER JOIN 慢 0.84 倍
测试移除索引后的性能:
已移除右表索引
测试无索引的 INNER JOIN:
执行计划分析:
(1, 'SIMPLE', 'r', 'ALL', None, None, None, None, '997003', 'Using where')
(1, 'SIMPLE', 'l', 'ref', 'join_key', 'join_key', '5', 'test_inner_join_left_join.r.join_key', '1', '')
无索引 INNER JOIN 匹配记录数: 100051
无索引 INNER JOIN 执行时间: 0.2907 秒
测试无索引的 LEFT JOIN:
执行计划分析:
(1, 'SIMPLE', 'l', 'ALL', None, None, None, None, '1000', '')
(1, 'SIMPLE', 'r', 'ALL', None, None, None, None, '997003', 'Using where; Using join buffer (flat, BNL join)')
无索引 LEFT JOIN 匹配记录数: 100051
无索引 LEFT JOIN 执行时间: 24.5531 秒
无索引性能差异: LEFT JOIN 比 INNER JOIN 慢 84.47 倍
Prompt
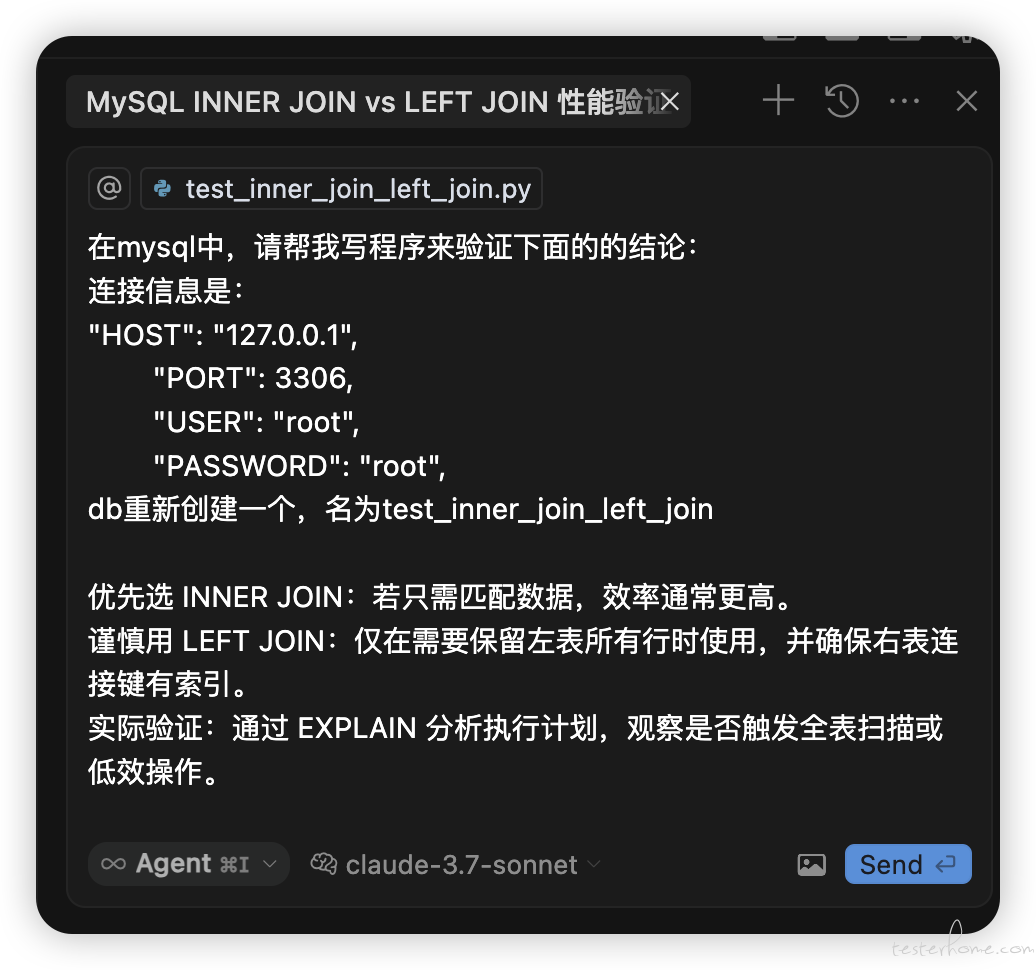
使用 Cursor + sonnet3.7 模型
在mysql中,请帮我写程序来验证下面的的结论:
连接信息是:
"HOST": "127.0.0.1",
"PORT": 3306,
"USER": "root",
"PASSWORD": "root",
db重新创建一个,名为test_inner_join_left_join
优先选 INNER JOIN:若只需匹配数据,效率通常更高。
谨慎用 LEFT JOIN:仅在需要保留左表所有行时使用,并确保右表连接键有索引。
实际验证:通过 EXPLAIN 分析执行计划,观察是否触发全表扫描或低效操作。
实际代码
import pymysql
import time
import random
# 数据库连接信息
DB_CONFIG = {
"host": "127.0.0.1",
"port": 3306,
"user": "root",
"password": "root",
}
def create_database():
"""创建新数据库"""
conn = pymysql.connect(**DB_CONFIG)
cursor = conn.cursor()
try:
# 删除已存在的数据库(如果有)
cursor.execute("DROP DATABASE IF EXISTS test_inner_join_left_join")
# 创建新数据库
cursor.execute("CREATE DATABASE test_inner_join_left_join")
print("数据库创建成功")
except Exception as e:
print(f"创建数据库失败: {e}")
finally:
cursor.close()
conn.close()
def setup_tables():
"""创建表结构"""
# 连接到新创建的数据库
conn = pymysql.connect(
**DB_CONFIG,
database="test_inner_join_left_join"
)
cursor = conn.cursor()
try:
# 创建左表 - 较小的表 (1000行)
cursor.execute("""
CREATE TABLE left_table (
id INT AUTO_INCREMENT PRIMARY KEY,
join_key INT,
data VARCHAR(100),
INDEX (join_key)
)
""")
# 创建右表 - 较大的表 (100万行)
cursor.execute("""
CREATE TABLE right_table (
id INT AUTO_INCREMENT PRIMARY KEY,
join_key INT,
data VARCHAR(100)
)
""")
print("表结构创建成功")
conn.commit()
except Exception as e:
print(f"创建表结构失败: {e}")
conn.rollback()
finally:
cursor.close()
conn.close()
def generate_data():
"""生成测试数据"""
conn = pymysql.connect(
**DB_CONFIG,
database="test_inner_join_left_join"
)
cursor = conn.cursor()
try:
# 为左表生成1000行数据
print("正在生成左表数据...")
for i in range(1000):
join_key = random.randint(1, 2000) # 随机生成连接键
data = f"Left data {i}"
cursor.execute(
"INSERT INTO left_table (join_key, data) VALUES (%s, %s)",
(join_key, data)
)
if i % 200 == 0:
conn.commit()
print(f"左表已插入 {i} 行")
conn.commit()
print("左表数据生成完成:1000行")
# 为右表生成100万行数据
print("正在生成右表数据...")
batch_size = 10000
for i in range(1, 1000001):
join_key = random.randint(1, 10000) # 随机生成连接键
data = f"Right data {i}"
cursor.execute(
"INSERT INTO right_table (join_key, data) VALUES (%s, %s)",
(join_key, data)
)
if i % batch_size == 0:
conn.commit()
print(f"右表已插入 {i} 行")
conn.commit()
print("右表数据生成完成:1,000,000行")
except Exception as e:
print(f"生成数据失败: {e}")
conn.rollback()
finally:
cursor.close()
conn.close()
def add_index_to_right_table():
"""为右表的连接键添加索引"""
conn = pymysql.connect(
**DB_CONFIG,
database="test_inner_join_left_join"
)
cursor = conn.cursor()
try:
print("为右表的join_key添加索引...")
cursor.execute("CREATE INDEX idx_join_key ON right_table(join_key)")
conn.commit()
print("索引添加成功")
except Exception as e:
print(f"添加索引失败: {e}")
conn.rollback()
finally:
cursor.close()
conn.close()
def test_join_performance():
"""测试两种连接方式的性能差异"""
conn = pymysql.connect(
**DB_CONFIG,
database="test_inner_join_left_join"
)
cursor = conn.cursor()
try:
# 测试INNER JOIN
print("\n测试 INNER JOIN:")
print("执行计划分析:")
cursor.execute("""
EXPLAIN SELECT l.id, l.data, r.data
FROM left_table l
INNER JOIN right_table r ON l.join_key = r.join_key
""")
explain_result = cursor.fetchall()
for row in explain_result:
print(row)
# 测量INNER JOIN执行时间
start_time = time.time()
cursor.execute("""
SELECT COUNT(*)
FROM left_table l
INNER JOIN right_table r ON l.join_key = r.join_key
""")
inner_count = cursor.fetchone()[0]
inner_time = time.time() - start_time
print(f"INNER JOIN 匹配记录数: {inner_count}")
print(f"INNER JOIN 执行时间: {inner_time:.4f} 秒")
# 测试LEFT JOIN
print("\n测试 LEFT JOIN:")
print("执行计划分析:")
cursor.execute("""
EXPLAIN SELECT l.id, l.data, r.data
FROM left_table l
LEFT JOIN right_table r ON l.join_key = r.join_key
""")
explain_result = cursor.fetchall()
for row in explain_result:
print(row)
# 测量LEFT JOIN执行时间
start_time = time.time()
cursor.execute("""
SELECT COUNT(*)
FROM left_table l
LEFT JOIN right_table r ON l.join_key = r.join_key
""")
left_count = cursor.fetchone()[0]
left_time = time.time() - start_time
print(f"LEFT JOIN 匹配记录数: {left_count}")
print(f"LEFT JOIN 执行时间: {left_time:.4f} 秒")
# 计算性能差异
print(f"\n性能差异: LEFT JOIN 比 INNER JOIN 慢 {left_time/inner_time:.2f} 倍")
# 测试没有索引的情况
print("\n测试移除索引后的性能:")
cursor.execute("DROP INDEX idx_join_key ON right_table")
print("已移除右表索引")
# 再次测试INNER JOIN (无索引)
print("\n测试无索引的 INNER JOIN:")
print("执行计划分析:")
cursor.execute("""
EXPLAIN SELECT l.id, l.data, r.data
FROM left_table l
INNER JOIN right_table r ON l.join_key = r.join_key
""")
explain_result = cursor.fetchall()
for row in explain_result:
print(row)
# 测量无索引INNER JOIN执行时间
start_time = time.time()
cursor.execute("""
SELECT COUNT(*)
FROM left_table l
INNER JOIN right_table r ON l.join_key = r.join_key
""")
inner_count_no_idx = cursor.fetchone()[0]
inner_time_no_idx = time.time() - start_time
print(f"无索引 INNER JOIN 匹配记录数: {inner_count_no_idx}")
print(f"无索引 INNER JOIN 执行时间: {inner_time_no_idx:.4f} 秒")
# 测试无索引的LEFT JOIN
print("\n测试无索引的 LEFT JOIN:")
print("执行计划分析:")
cursor.execute("""
EXPLAIN SELECT l.id, l.data, r.data
FROM left_table l
LEFT JOIN right_table r ON l.join_key = r.join_key
""")
explain_result = cursor.fetchall()
for row in explain_result:
print(row)
# 测量无索引LEFT JOIN执行时间
start_time = time.time()
cursor.execute("""
SELECT COUNT(*)
FROM left_table l
LEFT JOIN right_table r ON l.join_key = r.join_key
""")
left_count_no_idx = cursor.fetchone()[0]
left_time_no_idx = time.time() - start_time
print(f"无索引 LEFT JOIN 匹配记录数: {left_count_no_idx}")
print(f"无索引 LEFT JOIN 执行时间: {left_time_no_idx:.4f} 秒")
# 计算无索引情况下的性能差异
print(f"\n无索引性能差异: LEFT JOIN 比 INNER JOIN 慢 {left_time_no_idx/inner_time_no_idx:.2f} 倍")
except Exception as e:
print(f"测试连接性能失败: {e}")
finally:
cursor.close()
conn.close()
def run_test():
"""运行完整测试流程"""
create_database()
setup_tables()
generate_data()
add_index_to_right_table()
test_join_performance()
if __name__ == "__main__":
run_test()
相关配置


总结
- inner join 确实比 left join 性能更好,尤其是在没有右表索引时,都有索引时,100 万数据时,个人认为性能差距可忽略
- 不管 inner join 和 left join,想要更好性能,都应该注意创建对应的索引