前言
国内访问 chatgpt 太麻烦了,还是本地自己搭一个比较快,也方便后续修改微调啥的。
之前 llama 刚出来的时候在 mac 上试了下,也在 windows 上用 conda 折腾过,环境配置步骤太多,都没跑起来。最近网上看到有预编译的,对环境要求降低了非常多,所以早上试了下,终于跑起来了。
使用平台
系统:windows 10
硬件:i5 12400F + 32GB 内存 + RTX 3090 显卡
具体步骤
主要参考 https://pa.ci/248.html 。基本上使用的都是已经预编译好的软件,不用特别折腾环境配置。
因为用了 nvidia 的显卡,而且 cpu 本身也不强,所以主要配置为 gpu 加速为主
下载 cuda
直接到 https://developer.nvidia.com/cuda-downloads 下载对应自己系统的安装文件即可。
下载预编译 llama.cpp 软件
到 https://github.com/ggerganov/llama.cpp/releases ,下载 cuda 12 版本。下载完毕后,解压到一个文件夹里。我这里用的文件夹名字为 llama-bin-win-cuba-x64 ,下面也都用这个路径。
创建 prompt 文件
把 https://raw.githubusercontent.com/ggerganov/llama.cpp/master/prompts/chat-with-bob.txt 下载到 llama-bin-win-cuba-x64 根目录
下载量化模型
结合硬件配置,我用的是 13b 的模型 llama-2-13b-chat.Q5_K_M 。大家可以参考 https://pa.ci/248.html 选择合适自己的。
这里要注意,目前是无法直接访问 huggingface.co 网站的,我用的是 https://hf-mirror.com/ 镜像站点来解决。下载上面这个模型不需要 token 验证,所以可以直接打开 https://hf-mirror.com/TheBloke/Llama-2-13B-chat-GGUF/blob/main/llama-2-13b-chat.Q5_K_M.gguf ,点击 download 按钮直接下载
运行模型
在终端中打开 llama-bin-win-cuba-x64 目录,运行如下命令(模型 gguf 文件名,记得替换成自己用的)
.\main.exe -m .\llama-2-13b-chat.Q5_K_M.gguf -n -1 --repeat_penalty 1.0 --color -i -r "User:" -f .\chat-with-bob.txt --n-gpu-layers 1
注意,最后的 --n-gpu-layers 1 表示第一层让 gpu 计算,剩下给 cpu。运行后,会出现类似下面内容:
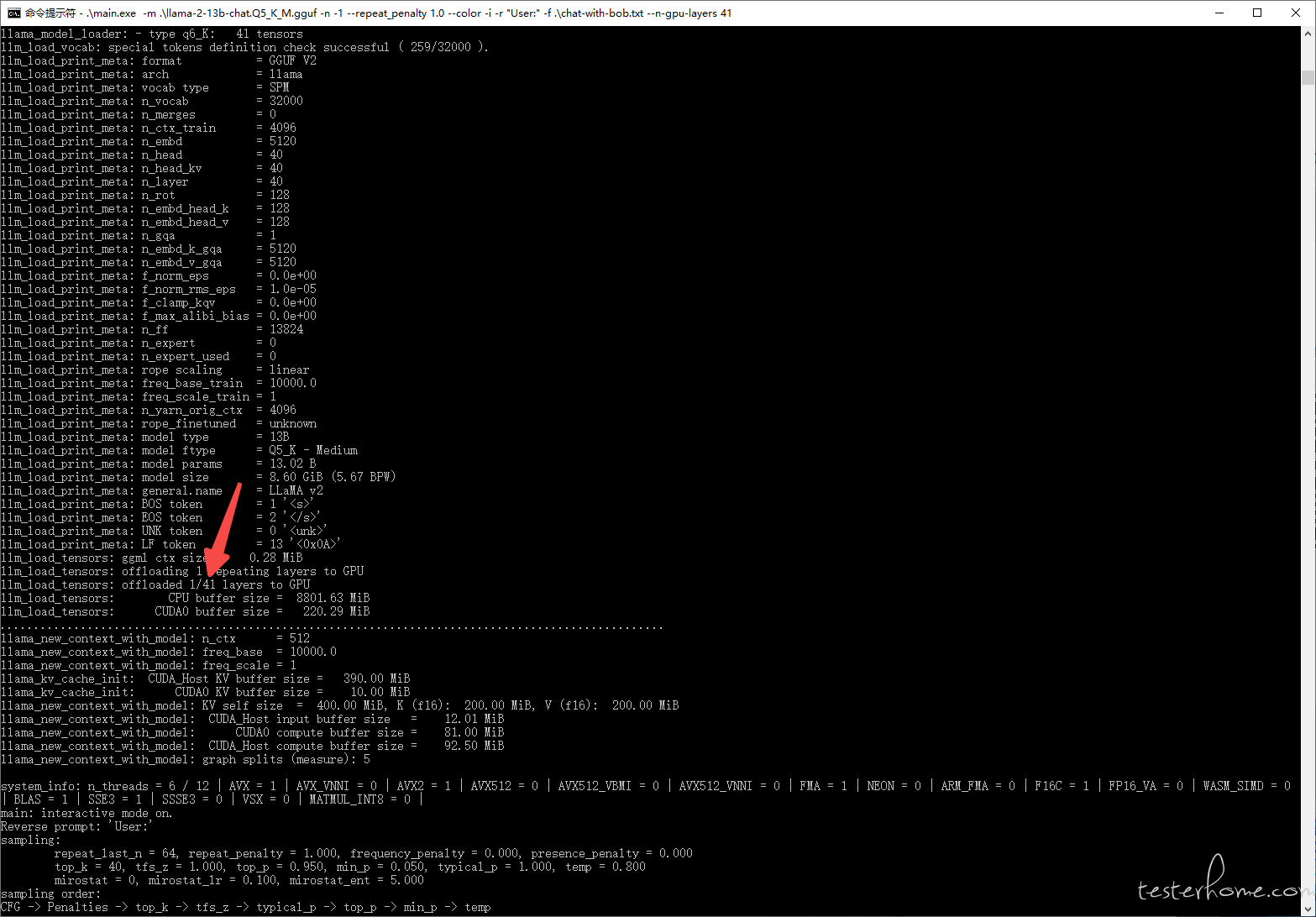
其中 llm_load_tensors: offloaded 1/41 layers to GPU ,说明一共有 41 层,gpu 运行第 1 层。后续想全部给 gpu 运行,把命令里的 --n-gpu-layers 1 改为 --n-gpu-layers 41 即可。
推荐大家可以尽量用 gpu 加速,运行速度比 cpu 快不少。
运行效果:
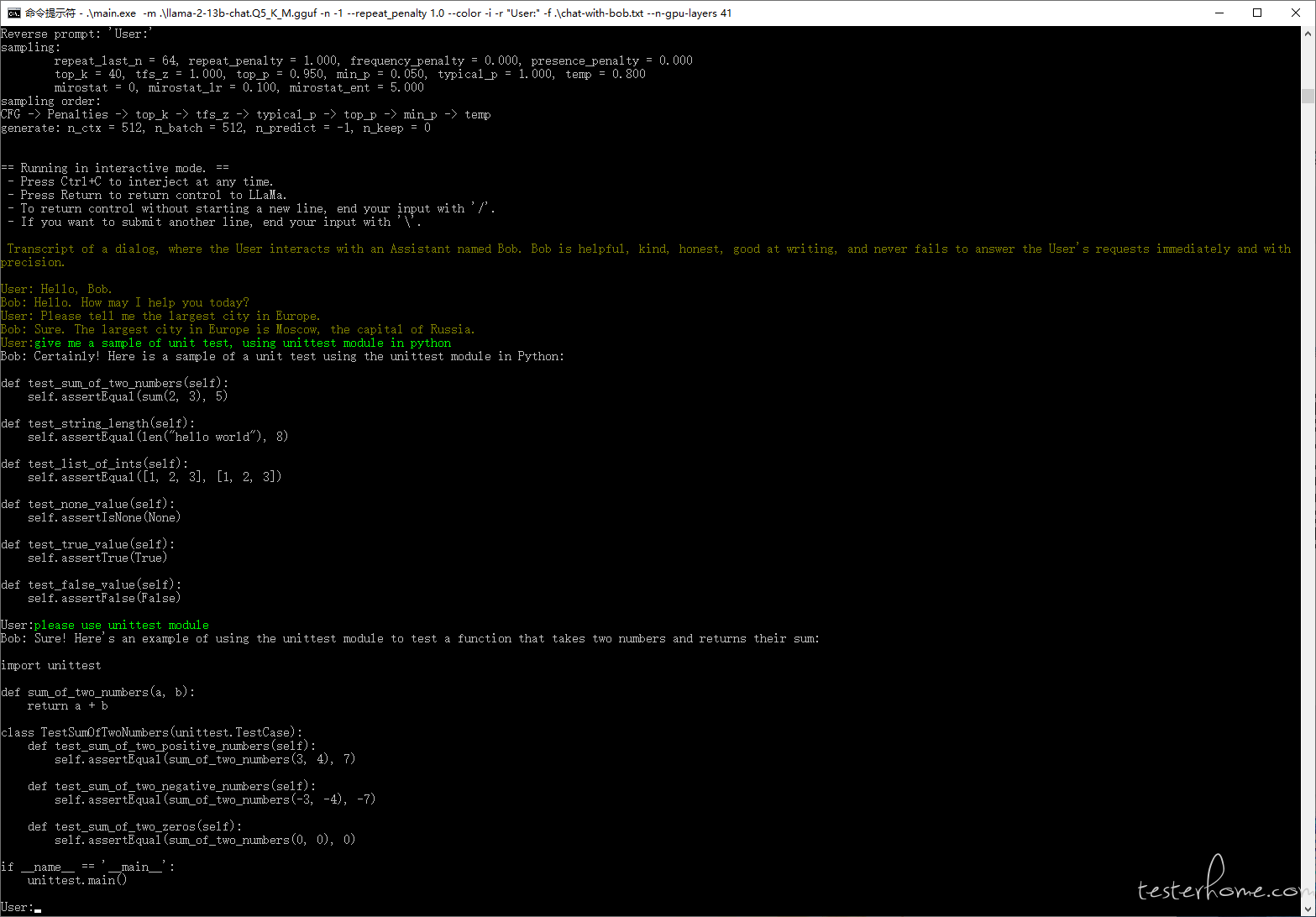
总结
初步在本地跑了起来,完成了第一步。后面继续折腾,把它变成 web 服务,上层再做更多事情。