1、背景
在技术群里面有个讨论,枚举字段是否需要增加索引的问题
有人说必须要,有人说加了索引没什么用。
talk is cheap, show me the data.
讨论那么多,还是得先有数据来验证。
说到这里,你可以先猜猜哪种最快,是储存过程最快的吗?
2、建表语句
数据库字段使用字符串代替枚举,由程序控制字段的值
create table users ( id int auto_increment primary key, name varchar(255) not null, age int not null, gender varchar(10) not null );
# 3、插入数据对比
## 3.1 存储过程
```sql
CREATE PROCEDURE GenerateData()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
INSERT INTO users (name, age, gender)
VALUES (
CONCAT('User', i),
FLOOR(18 + RAND() * (100 - 18)),
CASE
WHEN i % 3 = 1 THEN 'male'
WHEN i % 3 = 2 THEN 'female'
ELSE 'unknown'
END
);
SET i = i + 1;
END WHILE;
END
CALL GenerateData();
3.2 python 生成 insert 语句批量提交
import pymysql
import random
# 连接数据库
conn = pymysql.connect(host='localhost',port=3306, user='root', password='root', db='my_database', charset='utf8mb4')
cur = conn.cursor()
try:
# 开启事务
conn.begin()
for i in range(1, 1000001):
name = f'User{i}'
age = random.randint(18, 100)
gender = 'male' if i % 3 == 1 else 'female' if i % 3 == 2 else 'unknown'
# 执行插入语句
cur.execute("INSERT INTO users (name, age, gender) VALUES (%s, %s, %s)", (name, age, gender))
# 提交事务
conn.commit()
except Exception as e:
print(f"An error occurred: {e}")
# 发生错误时回滚
conn.rollback()
finally:
# 关闭游标和连接
cur.close()
conn.close()
3.3 使用文件导入
3.3.1 生成 csv 文件
import csv
import random
# 生成包含1,000,000条用户记录的CSV文件
with open('users.csv', 'w', newline='') as file:
writer = csv.writer(file)
for i in range(1, 1000001):
name = f'User{i}'
age = random.randint(18, 100)
gender = 'male' if i % 3 == 1 else 'female' if i % 3 == 2 else 'unknown'
writer.writerow([name, age, gender])
3.3.2 导入文件
# 数据库需要能读取到这个路径,否则会报错
# [2023-07-26 23:08:28] [HY000][13] (conn=151) Can't get stat of '/tmp/users.csv' (Errcode: 2 "No such file or directory")
# 如果使用的容器,需要把宿主机上的文件拷贝到容器
# 下面的例子是把宿主机/local/users.csv 拷贝到容器的根目录/
# docker cp /local/users.csv db-docker-compose-db-1:/
LOAD DATA INFILE '/users.csv'
INTO TABLE users
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
(name, age, gender);
如果数据库不在本地,不方便拷贝。可以使用 IDEA 自带的 database 导入功能
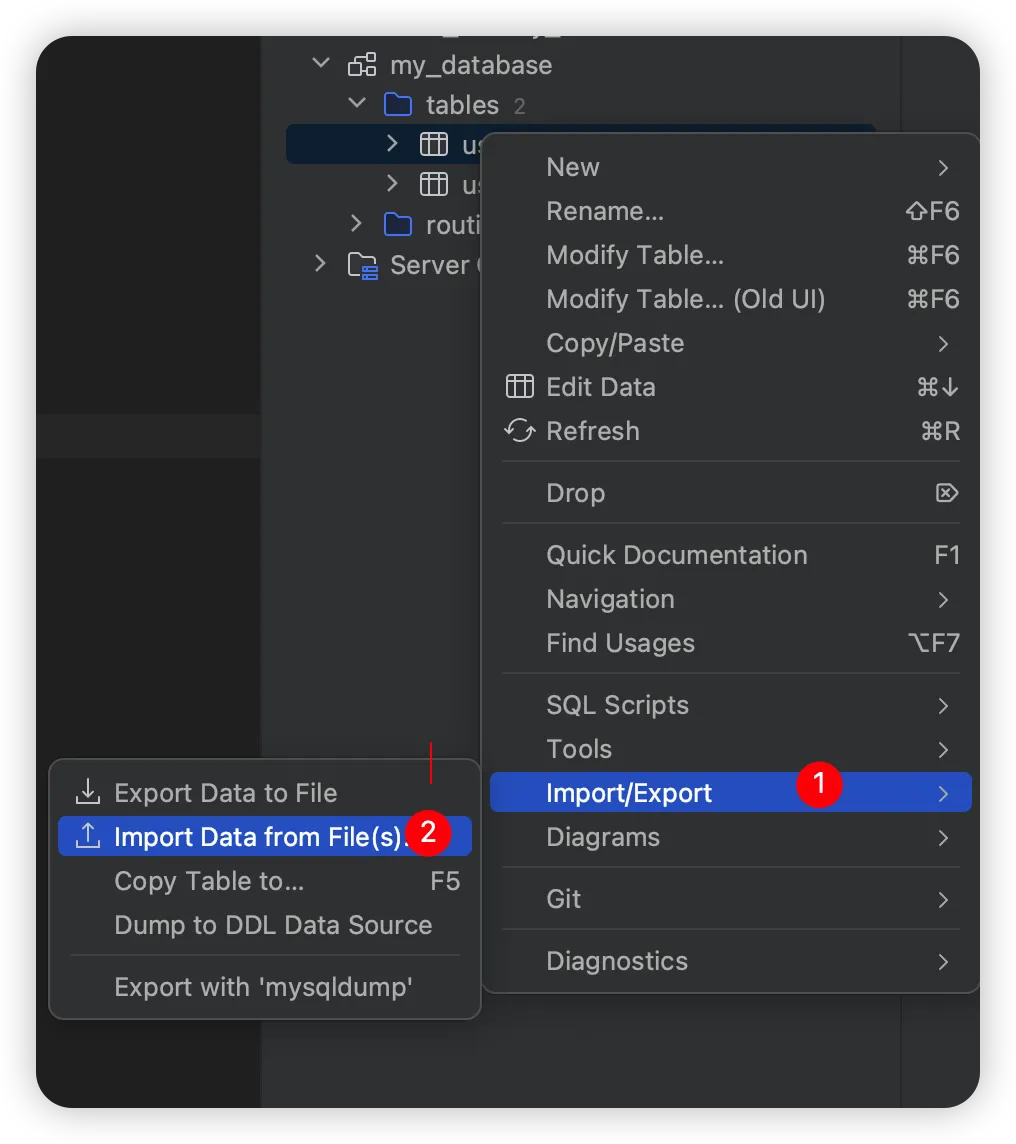
3.4 从已有的表中拷贝
INSERT INTO user_has_index SELECT * FROM users
4、耗时对比
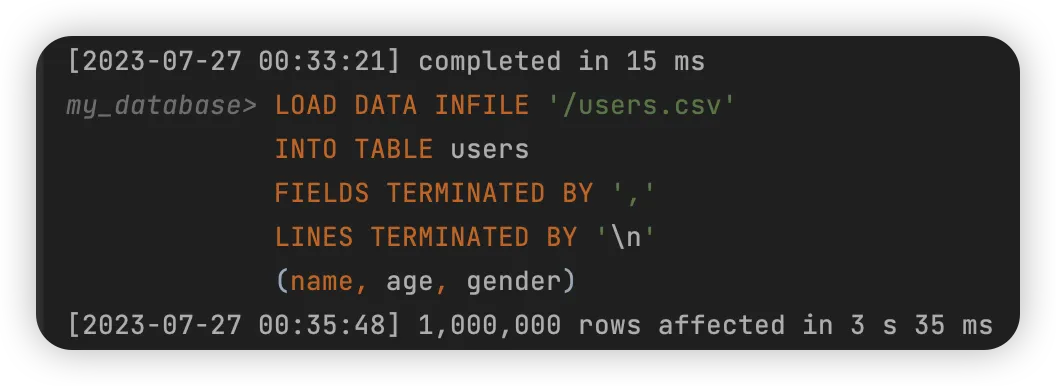
4.1 文件导入
所有字段均无索引
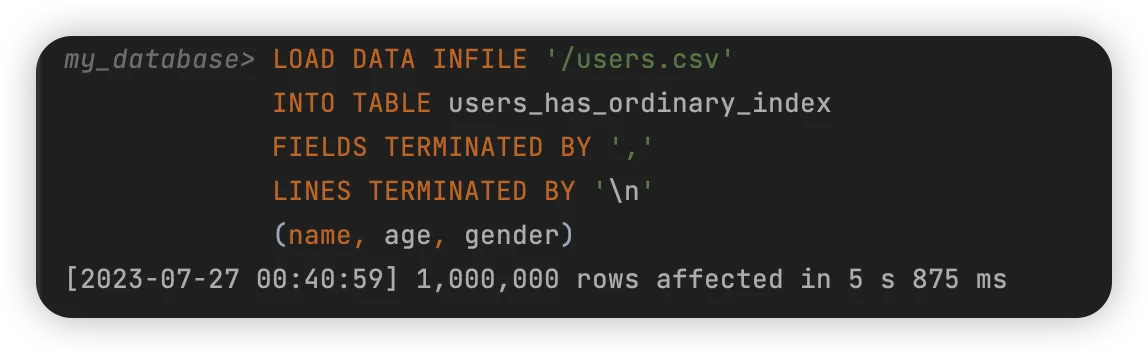
gender 字段有索引
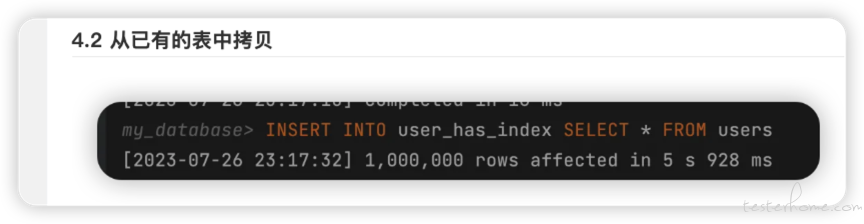
4.2 从已有的表中拷贝

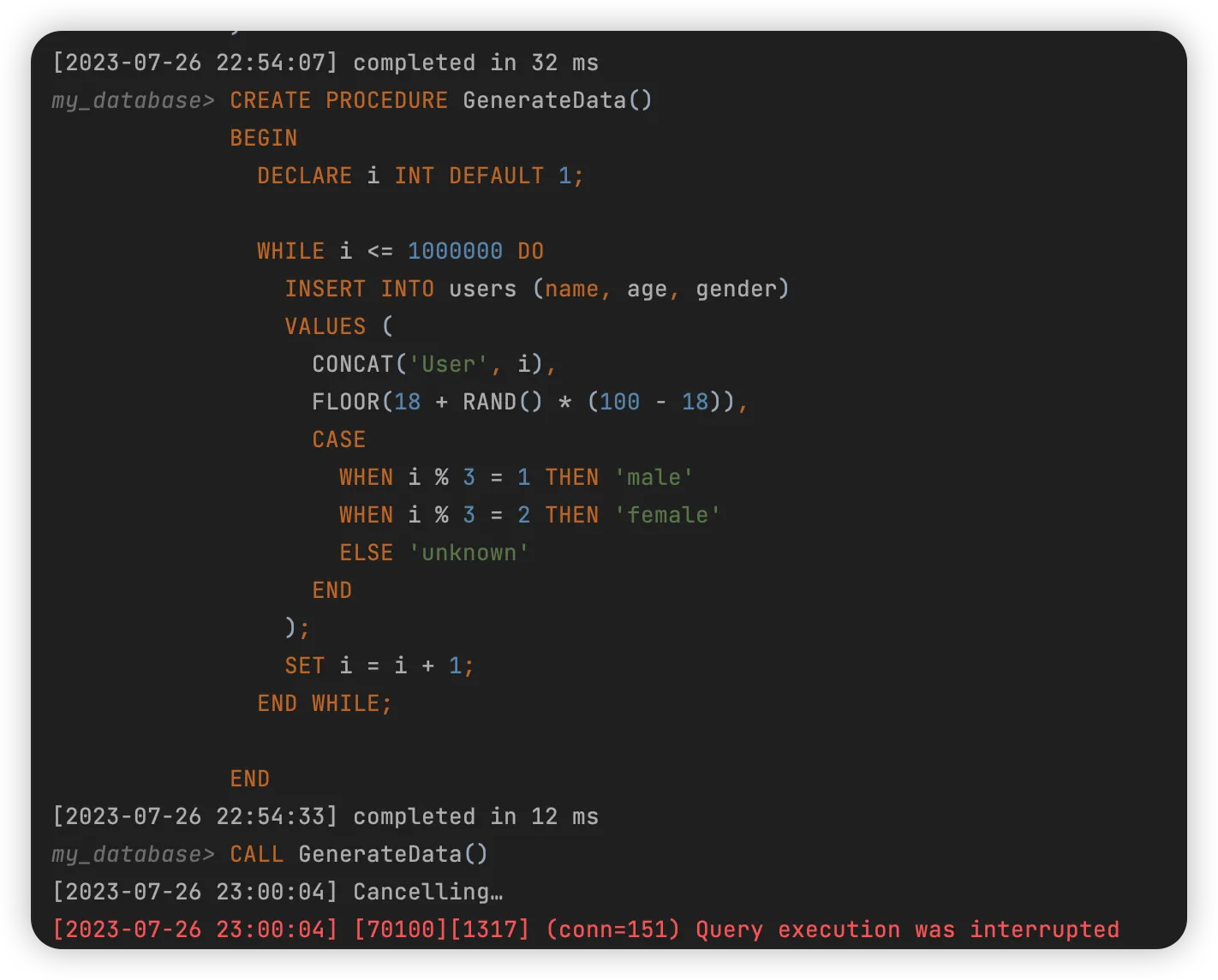
4.3 储存过程
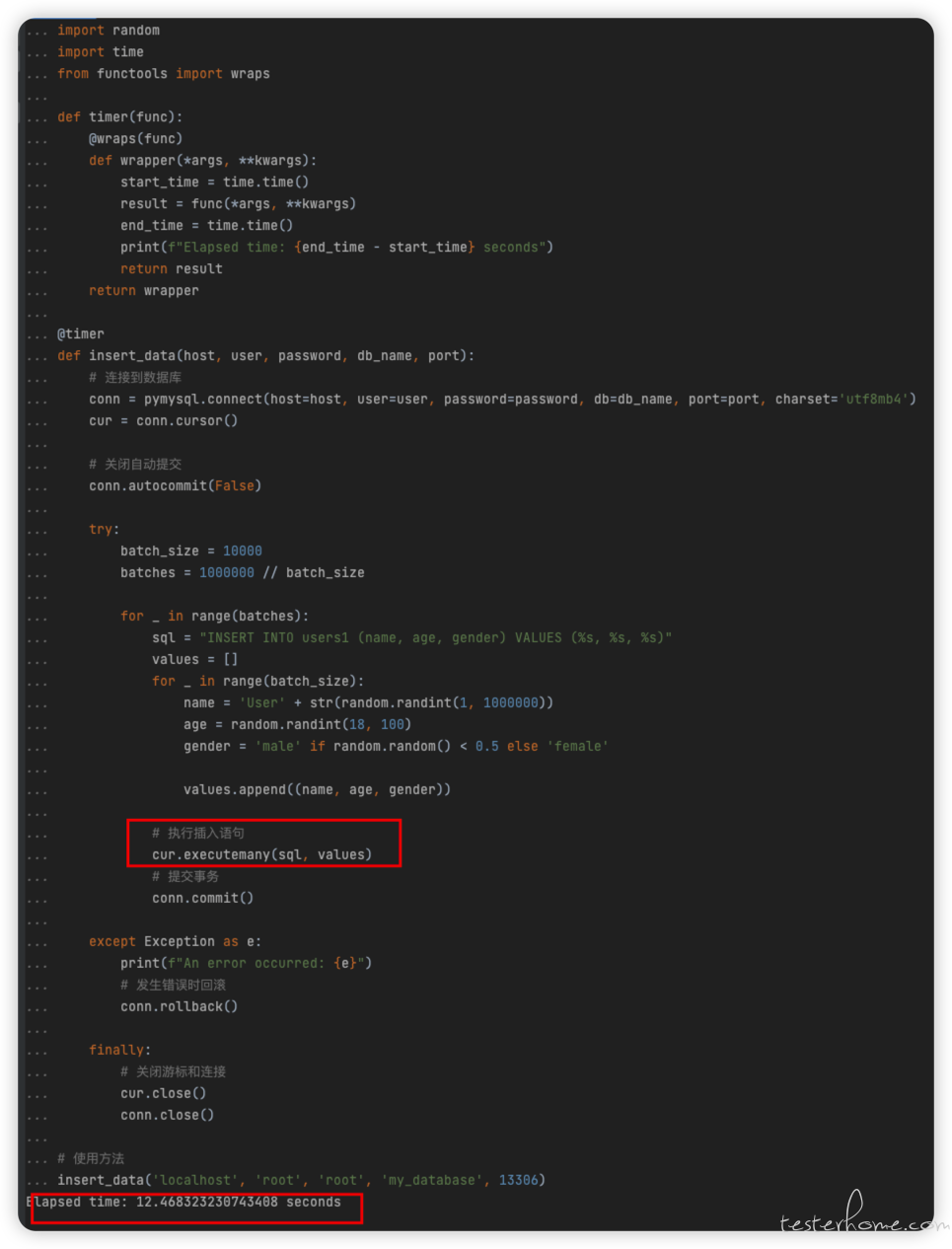
4.4 python 批量插入
python 批量插入(没计算时间,等了也有几分钟,很慢)
5、总结
- 存储过程并不是最快的,甚至很慢
- 文件导入是最快的
- 使用 Python 直接批量 insert 不可取
你猜对了吗?
或者还有更快的方案,比如说分批 + 事务。
欢迎留言和我交流。
「原创声明:保留所有权利,禁止转载」