各位大佬好,我是某传统行业的一个小测试,先说一下项目情况。
- 我们组内人员均为功能测试。
- 项目时间长,没有任何的接口文档,也没有人愿意编写 swagger。
在干了一段时间之后,我发现了一个很严重的问题,回归用例过多。
我们的回归用例是,在平时的版本用例中,会有一部分 smoke 用例,把这部分用例挑出来,塞到回归用例库中。这就使得回归用例越来越多。然后又因为用例库只做增量,不怎么进行删减,而且需要覆盖多个版本,造成了每次的回归测试都很痛苦。
在某次 VCEV 沙龙,京东的熊老师建议我去看看能不能做到精准测试圈定每次回归重点范围,并推荐了我本不测的秘密,我就开始了我的精准测试之路。
我的代码水平,用我一个测试群里的大佬的话来说 “榨菜,豆腐乳,咸鸭蛋,腌黄瓜,你的代码,共通点是都很下饭。” 所以大家见笑
解析业务代码
首先是参考的论坛上这个帖子:
https://testerhome.com/topics/23819
先把拉到的代码编译成.class 文件,再通过 ASM 框架去进行解析,这里我碰到了我第一个难题。。。观察者模式看不懂。。。
幸好,ASM 也提供了普通的面向对象模式,感觉简单不少
FileInputStream fileInputStream = new FileInputStream(path);
ClassReader cr = new ClassReader(fileInputStream);
ClassNode cn = new ClassNode();
cr.accept(cn, 0);
然后我把他的类对象转化成了我自己的类对象,方便处理。
MyClassNodeNew myclassnode = new MyClassNodeNew();
//解析类信息
myclassnode.setClassName(cn.name.replace("/", "."));
List<AnnotationNode> classAnnotations = cn.visibleAnnotations;
List<MethodNode> methodNodes = cn.methods; //这里是获取到了类成员方法
boolean isController = false;
String firstPath = "";
if(classAnnotations != null && !classAnnotations.isEmpty()) {
for (AnnotationNode classAnnotation : classAnnotations) {
if (classAnnotation.desc.contains("Controller")) {
isController = true; //为真则为Controller层类
myclassnode.setController(true);
}
firstPath = getAnntationValue(classAnnotation); //获取类的注解中的接口地址
}
}
然后开始转化其中的 method 方法
if (isInit(methodNode.name)) { //这里是筛掉了init构造函数
//新建方法对象
MyMethodNodeNew method = new MyMethodNodeNew();
method.setMethodName(methodNode.name);
method.setOwner(cn.name);
method.setControllerMethod(isController);
myclassnode.addMethod(method);
如果当前类为 controller 层类的话,name 他的方法为接口方法,
if (isController) { //为controller层,则获取接口地址
List<AnnotationNode> methodAnnotations = methodNode.visibleAnnotations;
if(methodAnnotations != null && !methodAnnotations.isEmpty()){
for (AnnotationNode methodAnnotation : methodAnnotations) {
String anntationvalues = getAnntationValue(methodAnnotation);
if (anntationvalues.length() != 0) {
String interfacePath = firstPath + anntationvalues;
//获取接口表
myclassnode.addInterFace(interfacePath);
method.setInterFaceName(interfacePath);
}
}
}
}
因为公司用的 mybatis,所以我希望将表与逻辑代码也进行关联。
先去根据表信息,生成表对象,这个很好解决。
获取到 mapper.xml 里的 namespace,id 信息,将这个 xml 与和他同名的接口对象看做同一个,同时又能与表对象进行关联。
SAXReader reader = new SAXReader();
Document doc = reader.read(path);
Element rootelement = doc.getRootElement();
List<Element> list = rootelement.elements();
for (Element element : list) {
if (element.getText().toUpperCase().contains(" " + tableName) ||
element.getText().toUpperCase().contains(tableName + " ") ||
element.getText().toUpperCase().contains(tableName + "\n")) {
String functionName = element.attributeValue("id");
String className = rootelement.attributeValue("namespace");
String parameterType = element.attributeValue("parameterType");
String resultType = element.attributeValue("resultType");
这里的转换其实我有一些问题,我现在罗列一下,希望有大佬指点一下。
- 我在处理的时候,发现我生成了大量的 getset 方法,怎么去对这些方法进行过滤?
- 对于通过反射实例化的类是不是就没有什么好的解决方法了?
存储
拿到了类信息和方法信息,下面是如何将其保存,留作查询呢?
特别复杂的数据库设计我也不会,毕竟下饭。。。不过我搜到了一个好东西,Neo4J,图数据库。
于是我将我整理出的类对象和方法对象转化为了类节点和方法节点,用 cql 写入 neo4j 库。
这里的逻辑是:
读取类信息 A
判断有无类 A,如果没有则创建类 A 的节点
在读取到类 A 中的方法 B 时,创建节点,并与类 A 关联
在读取到方法 B 内调用的其他类 C 的方法 D 时:
判端类 C 是否存在,如果不存在,创建类 C 的节点
判断方法 D 是否存在,如果不存在,创建方法 D 的节点
判断类 C 与方法 D 的关系是否存在,如果不存在,创建关系
创建方法 B 与方法 D 的关系
//创建类节点
private void createClassNode(Neo4jTools neo4jTools, String name){
//检查类节点是否存在
if(!isExistClassNode(neo4jTools, name)){
String insertClassNode = String.format("CREATE(n:class{ClassName: \"%s\", appId: \"%s\"}) return n", name.replace("Impl", ""), APPID);
neo4jTools.executeCQL(insertClassNode);
};
}
//创建方法节点
private void createMethodNode(Neo4jTools neo4jTools, MyMethodNodeNew method){
if(!isExistMethodNode(neo4jTools, method)){
String insertClassNode = String.format("CREATE(n:method{MethodName: \"%s\"," +
"isControllerMethod: \"%s\", interfaceName: \"%s\", Owner: \"%s\", appId: \"%s\"}) return n",
method.getMethodName(), method.isControllerMethod(), method.getInterFaceName(), method.getOwner().replace("Impl", ""), APPID);
neo4jTools.executeCQL(insertClassNode);
}
}
//创建关系
private void createCMShip(Neo4jTools neo4jTools, boolean isController, String className, MyMethodNodeNew methodnode){
String classType = "class"; /// TODO: 2021/6/3 不能只是根据iscontroller来判断
if(!isExistClassRelationship(neo4jTools, className, methodnode)){
if(isController){
classType = "controllerclass";
}
String cql = String.format(
"match(n:%s),(m:method) where n.ClassName= \"%s\" and n.appId= \"%s\" and m.MethodName= \"%s\"" +
"and m.Owner= \"%s\" and m.appId= \"%s\"create(n)-[r:include]->(m)",
classType, className, APPID, methodnode.getMethodName(), methodnode.getOwner(), APPID);
neo4jTools.executeCQL(cql);
}
}
最终的结果,在 neo4j 上的展示如下图:
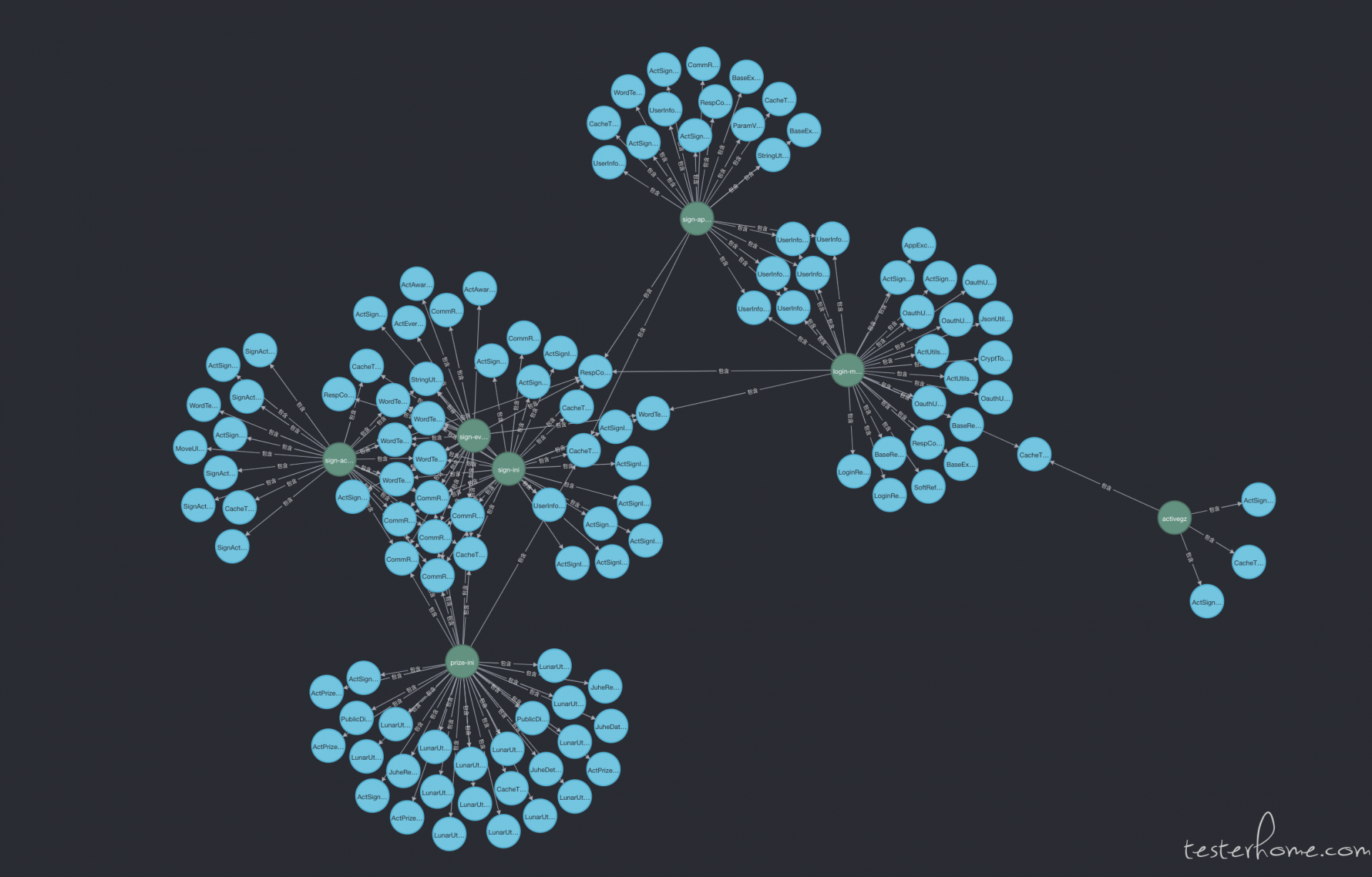
有种瞬间爆炸的感觉,看的人密集恐惧症都来了。
筛选一下,好很多。
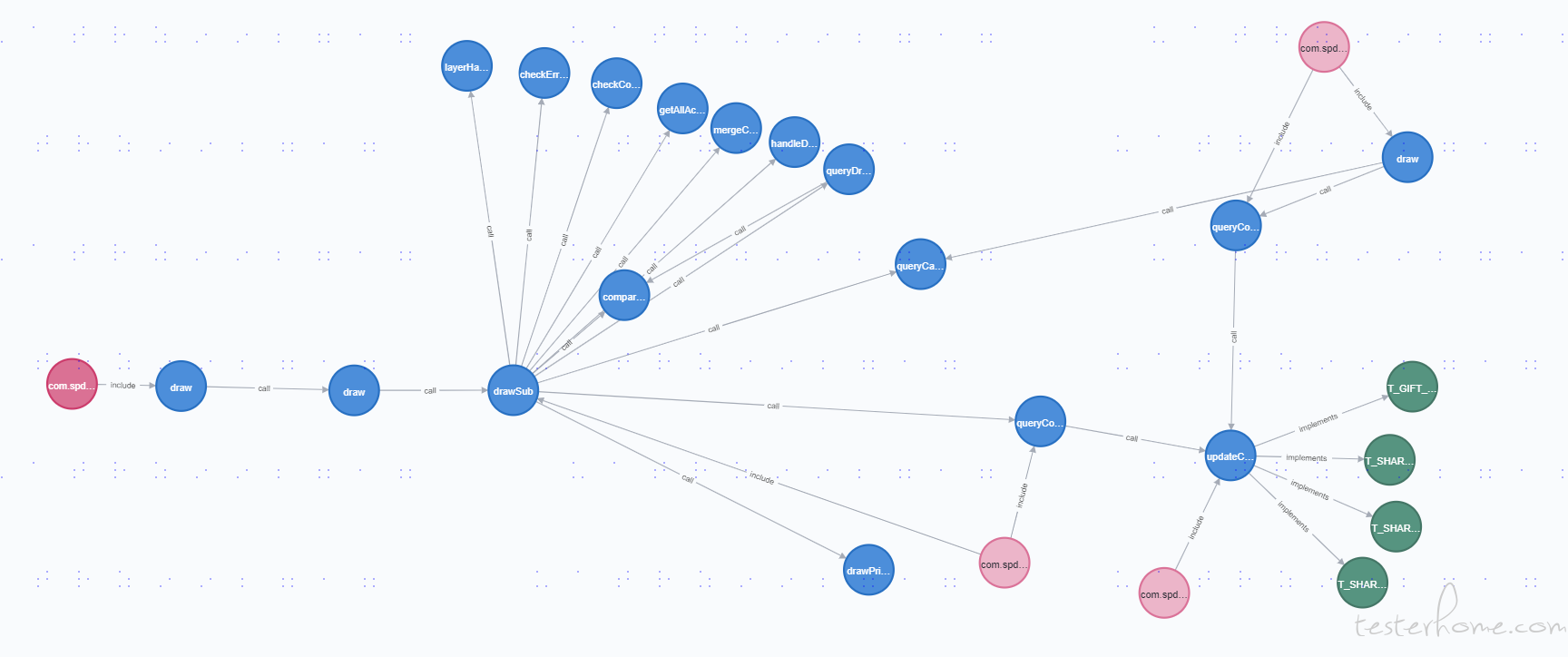
从最外层的接口信息,到最内层的表,调用关系基本就打通了。具体的结构可能还需要打磨,但是摇摇欲坠的大楼已经可以住人啦!~
实战
很快,我迎来了一个实战的机会,一次系统优化需要优化某些表内字段的长度,上下游统一起来。但是表太多,无法给出影响的功能。
这正好是一个很好的机会,先让开发和需规提供一版,我再自己从我的调用链路表中根据表名反推接口一波。
我比他全,大成功!
以下是还未实施的空想,等我做了再来更新。
与用例的关联
看了前辈们的经验,都觉得用例的维护会是精准测试的一个很大的成本,因为只能人工维护。所以我目前的想法如下:
能否根据前端代码,将增量的用例与前端的页面进行绑定?
举例:
1.根据前端代码,获取一个页面上会调用哪些接口(这个我看安卓好像可以这么玩?我不懂前端开发。。。)
2.在知识图谱中新增页面节点,将这个页面节点和有关联的后台接口做关联。
3.页面节点关联用例集。
4.这样新增的用例还是会对应到用例集里面。好处是,功能用例照写,普通测试关联功能用例和页面的关系,较为简单,服务端接口改动和前端页面关联关系自己生成。以页面为单位,颗粒度不至于太细,也不至于太粗。当然只是我的想法。
版本的对比
每次回归之前,拉取当前 sit 代码,生成新的知识图谱。
将 master 版本和当前 sit 版本的代码进行对比,找出改动的方法或者是新增的方法。
就是 jgit,这个没啥好说的。
以上就是我自己的精准测试实践,欢迎大家斧正。

