接口测试 自动化落地过程记录
1.前言
首先感谢 testerhome 这样一个平台,因为我在二线城市,相对一线互联网有些弱,让我能学习和见识到工作中没接触的很多知识,从最开始不会自动化相关的任何东西,慢慢自学 python,期间偶然进入这个论团,从此就开启了一扇大门,见识到测试工作原来也可以这样丰富多彩,有这么多优秀的同行。
学了 python 后,最开接触 AutomatorX 项目,自己写造轮子用 pyqt5+appium+python+opencv 写了一个客户端的编写 appium 的脚本工具,后面学习 docker 的系列文章,到后面使用 httprunner,模仿 fastrunner 写的 web 工具,还有很多技术之外的东西,跟着里面的大神一起学习了很多。
言归正传,因为这篇主要是记录下最近这段时间的自动化落地情况,更想向大家交流学习下。如果对你有用,我会很开心,如果觉得这个写的很呵呵,你一定比我厉害,我也想后面哪天再看这篇文章的时候,也觉得很呵呵~~
2.背景
公司的产品是大数据相关的中台产品,主要服务对象是企业和政务。大数据平台包括多个子平台,每个子平台负责数据加工的 ETL 过程的管理统计安全维护等工作,今年产品很多地方投入使用,公司虽然是 CICD 线上统一部署,但是 CICD 也是刚刚起步,也存在很多问题,每部署一套环境都是需要去进行冒烟测试,政务的部署一般都在现场的内网环境,部署验证都需要通过跳板机或者远程操作去完成,每次测试数据准备,测试验证都要花费很多时间和精力,尤其是多个项目同时进行时。
3.自动化过程
首先简单说下准备的数据和大致的场景,这里只展示部分的。
3.1 数据准备
T_DJ_QYXX(企业基本信息)
| 字段 | 字段类型 | 字段长度 | 注释说明 |
|---|---|---|---|
| DJXH | NUMBER | 20 | 唯一 ID |
| QYSHXYDM | VARCHAR2 | 20 | 企业社会信用代码 |
| QYMC | VARCHAR2 | 300 | 企业名称 |
| FDDBRXM | VARCHAR2 | 150 | 法人代表姓名 |
| FDDBRSFZJHM | VARCHAR2 | 30 | 法人代表身份证件号码 |
| HY_DM | VARCHAR2 | 4 | 行业代码 |
| ZCDZ | VARCHAR2 | 300 | 企业注册地址 |
| DJRQ | DATE | 7 | 登记日期 |
| XGRQ | DATE | 7 | 修改日期 |
| DQ_DM | VARCHAR2 | 12 | 地区代码 |
T_DM_HY(行业代码表)
| 字段 | 字段类型 | 字段长度 | 注释说明 |
|---|---|---|---|
| HY_DM | VARCHAR2 | 4 | 行业代码 |
| HYMC | VARCHAR2 | 68 | 行业名称 |
T_DJ_ZRRXX(自然人基本信息)
| 字段 | 字段类型 | 字段长度 | 注释说明 |
|---|---|---|---|
| DJXH | NUMBER | 20 | 自然人唯一 ID |
| XM VARCHAR2 | 75 | 姓名 | |
| SFZJHM | VARCHAR2 | 20 | 身份证件号码 |
| CSNF | VARCHAR2 | 8 | 出生年月 |
| XB_DM | CHAR | 2 | 性别代码 |
| DQ_DM | CHAR | 6 | 地区代码 |
| XLQK | VARCHAR2 | 10 | 学历情况 |
| HYZK | CHAR | 4 | 行业代码 |
| NSRE | NUMBER | 0 | 年收入额 |
| LRRQ | DATE | 7 | 录入日期 |
| XGRQ | DATE | 7 | 修改日期 |
T_DM_XB(性别代码表)
| 字段 | 字段类型 | 字段长度 | 注释说明 |
|---|---|---|---|
| XB_DM | VARCHAR2 | 255 | 性别代码 |
| XBMC | VARCHAR2 | 255 | 性别名称 |
T_NSXX(企业 (或自然人)纳税信息)
| 字段 | 字段类型 | 字段长度 | 注释说明 |
|---|---|---|---|
| ZSUUID | NUMBER | 20 | 纳税流水 UUID |
| DJXH | VARCHAR2 | 20 | 企业或自然人 ID |
| NSRQ | VARCHAR2 | 300 | 纳税日期 |
| NSE | VARCHAR2 | 150 | 纳税额 |
| CJSJ | VARCHAR2 | 30 | 创建时间 |
| CZLX | VARCHAR2 | 4 | 创建类型 |
T_DM_DQ(地区代码表)
| 字段 | 字段类型 | 字段长度 | 注释说明 |
|---|---|---|---|
| DQ_DM | CHAR | 6 | 地区代码 |
| DQMC | VARCHAR2 | 150 | 地区名称 |
3.2 大致场景:
离线加工部分
1.初始化上面公安局和税务局样例表数据到测试 mysql 数据库。
2.在平台创建组织角色用户账号以及 mysql 外部数据源。
3.将公安局和税务局 mysql 数据通过集成平台接入 hive 贴源。
4.通过标准平台将 T_TY_DJ_ZRRXX(自然人基本信息)中性别代码进行码表标准化处理。
5.通过资产数据模型创建 T_ZT_FDQQYHSTJ(分地区企业户数统计表)。
6.通过离线平台加工数据获取分地区企业户数统计数据写入 T_ZT_FDQQYHSTJ,并通过同步任务将 T_ZT_FDQQYHSTJ 数据下云到 mysql。
7.通过数据质量平台对 T_TY_DJ_QYXX,T_DM_HY,T_TY_DJ_ZRRXX,T_TY_NSXX 全表数据质量检核。
8.通过 API 平台对 T_ZT_FDQQYHSTJ 的数据进行 API 创建。
9.标签平台通过字段映射,mysql 语句,拖拽形式进行标签加工。
实时计算部分
1.实时计算人员数据量变化:准备一个 mysql 存储过程往一个表不停写入数据,然后从 mysql 实时采集到 kafka,运用 flink 实时计算。(实时计算平台完成)
4.自动化实施
4.1 从 0 开始
xx 的一句话:我们需要开始实施自动化了。
1.人力投入
1 人,好吧就我自己,那就干吧!
2.主要目标
首先整理要实现自动化的场景,第一版数据和场景都很随意,自己随便造的测试数据,场景也是之前组织组内同事按照每个人的平台去定一个数据处理的要求,然后每个人各自编写测试步骤,组成的测试场景。定的目标就是就是把每个平台串起来,验证数据流转加工正常,每个平台只验证一个核心流程,确保每个平台间的依 赖,配置正确。
3.工具
工具使用 Httprunner,为啥,因为是同行写的,牛逼!
4.过程
一顿操作,因为还有每个版本的测试任务,前前后后花了将近一个月的时间,把主要流程自动化用例写好了,勉强能跑。为啥勉强能呢?这脚本只有我自己能跑,给别人跑,跑不了。因为脚本,里面的限制太多,比如 env 里面的参数太多了,每次切换环境要改很多参数(要配置外部 mysql,kafka 以及其他的数据源连接信息,要更换平台访问地址,要更改角色配置,要配置很多 hadoop 组件的连接信息,类似很多。。。。。。)。
5.问题
除了运行起来麻烦,还有很多其他问题,比较突出的:
- 期间不断重复操作页面点击,charles 抓包,转成脚本,参数化。。。很多重复劳动耗时耗力。
- 用例只能一次从头执行到结束,几百个接口,有一个报错,就得从头开始。
- 用例执行多轮完后,很多测试数据遗留在上面没有清理。
- 用例颗粒度需要细化。
这个过程我觉得最重要的是把自动化场景确定,要求对业务比较熟悉,场景能覆盖到核心流程,明确自动化脚本要干啥,有一个目标;工具适合自己或者团队就行,不必过于纠结;先把核心的流程实现,脚本能跑出东西来才可能有价值,少说多做,这个过程技术上可能坑多些,多百度,多思考,更多的是驱动自己去完成。
#### 4.2 从 0 到 0.5
很多 xx 的话:我们需要好用的自动化。
1.人力投入
3 人,主干的流程实现了,现在多投入 3 个人来维护丰富用例!那就改吧!
2.主要目标:
- 减少脚本配置,增加场景业务含义
- 编写工具减少重复劳动,提升效率
- 优化脚本逻辑
2.工具
开发:主要 drf+vue+httprunner+tornado
管理:主要 git+jenkins+docker
3.过程
因为有同事参与进来,冒烟脚本跟随版本迭代在 git 进行版本控制,集成到 jenkins,构建 docker 镜像,和应用一起进行交付。一部分工作可以安排同事去完成,很大程度减少了工作压力,同事也积极配合,分配的任务都能按计划实施,还是很开心的。
首先增加场景业务含义,之前线上部署,都是开发冒烟,测试验证,产品上去创建给客户演示的场景。那既然自动化也是去跑场景,那就去跑产品创建的那套场景,一举两得。就和产品确定了场景和测试数据,然后拆分转为自动化脚本任务。
减少脚本配置,应用部署都是注册在 nacos 上,用 python 去解析 nacos 获取参数,一些外部组件的参数,也通过 cicd 他们部署后,写入 nacos 去获取,脚本的参数最终只需要配置 nacos 的连接就行。
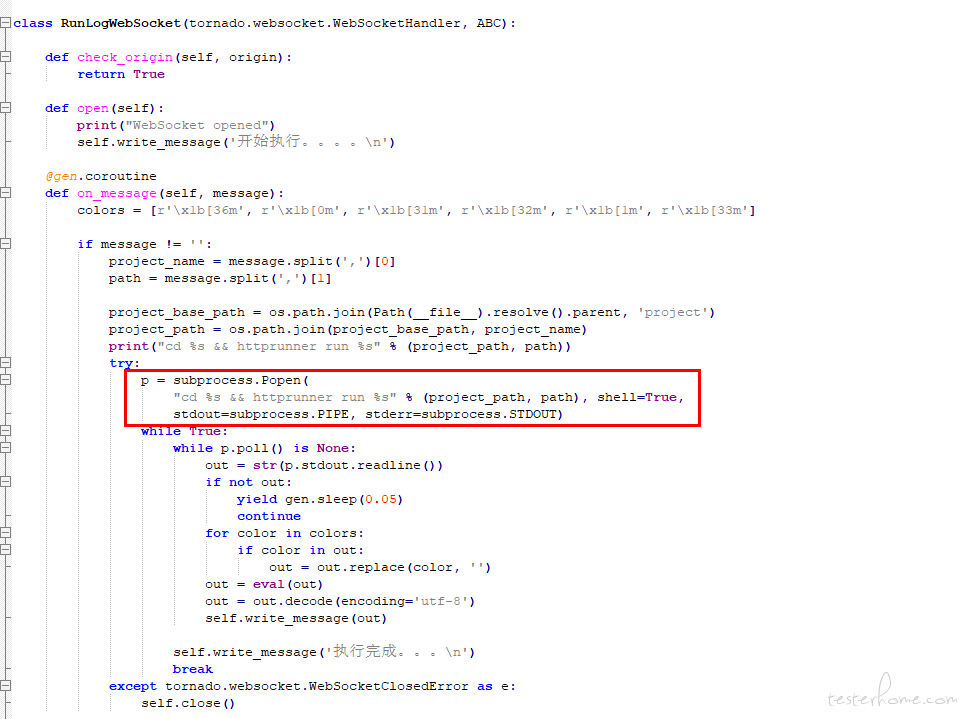
提升编写效率,最小的开发成本编写了一个在线的 httprunner 编辑器,主要解决 :
提供一个公共脚本运行环境,免去安装脚本运行环境,减少使用成本
charles 抓包导出的 har 包转化脚本的时候自动参数化变量
不敲命令,在线调试和查看报告
能上传和导出脚本
多人维护的时候在线合并脚本等
细化用例颗粒度,将脚本按照每个子平台去维护用例,然后每个子平台的用例可以独立执行。
优化脚本逻辑,持久化 extract 参数(重点),如果想每个子平台独立执行,这里面涉及到参数化的传递,extract 传递的变量只能在执行的那个 session 里面使用,但是每个子平台的数据是关联的,比如资产平台新加一个数据源,集成平台就需要这个数据源的 id 和连接的信息。每个平台独立执行的话,单独执行资产创建数据源,然后再执行集成平台无法用 extract 获取变量。解决的办法就是把数据源的 id 和信息持久化到 env 文件里面,数据源的信息就能共享给其他的脚本。就是再 teardown_hooks 将 $respons 里面需要的参数写入到 env 文件里面。后面接口使用变量都从用 ${ENV(xx)}去参数化。
有什么好处呢?你可以调试单个的参数化的 api 接口,接口出错不用重头开始,前面平台接口完成后,后面的平台用例可以从 env 里面读取需要的参数单独重复跑。还能解决每个子平台用例参数的依赖。
解决执行后的遗留数据问题,因为新环境很难保证脚本能一次成功执行,脚本里面新增的接口中涉及命名的都加上一个批次号的变量,避免重复执行的 ‘重复命名’ 报错。多次执行后,就有很多遗留数据。
有 2 种方案:
脚本里面增加删除的接口,之前的接口为正向接口脚本加上 skipif 关键字判断 env 文件里面的变量 skip,teardown_hooks 都加上判断逻辑,判断 $respoen 里面的业务代码是否 200,如果不是 200,就将 env 文件里面的 skip 变量设置成 True,删除接口的脚本加上 unskif 关键字判断 env 文件里面的变量 skip。这样只要正向接口报错,就会跳过剩下正向接口,执行删除接口。保证执行多次只有一个批次的遗留数据,用于演示。
铲库,重置数据库,然后再执行一遍脚本,用于演示(只能适用于新环境部署)。
这个过程技术上的也基本没啥阻碍了,更多的在于沟通,组内组外的推广,这个是落地非常重要的一环,脸皮厚点,只要别人在用了,就算说的再烂,只要有需求反馈,我就很开心,不断完善,可能做的多错的多,但是使每次犯错都有它的价值,都是提升自己的一次机会,自动化可能更多的是去契合外部的需求。
4.2 努力到 1
经过和同事的努力,虽然自己还是觉得很多地方不太好,但是线上确实能产生价值了,自动化也上了迭代流程。最后交由交付的同事去使用,从开发,产品,交付的得到了很多很好的反馈,他们不用再去糟心验证的事了。
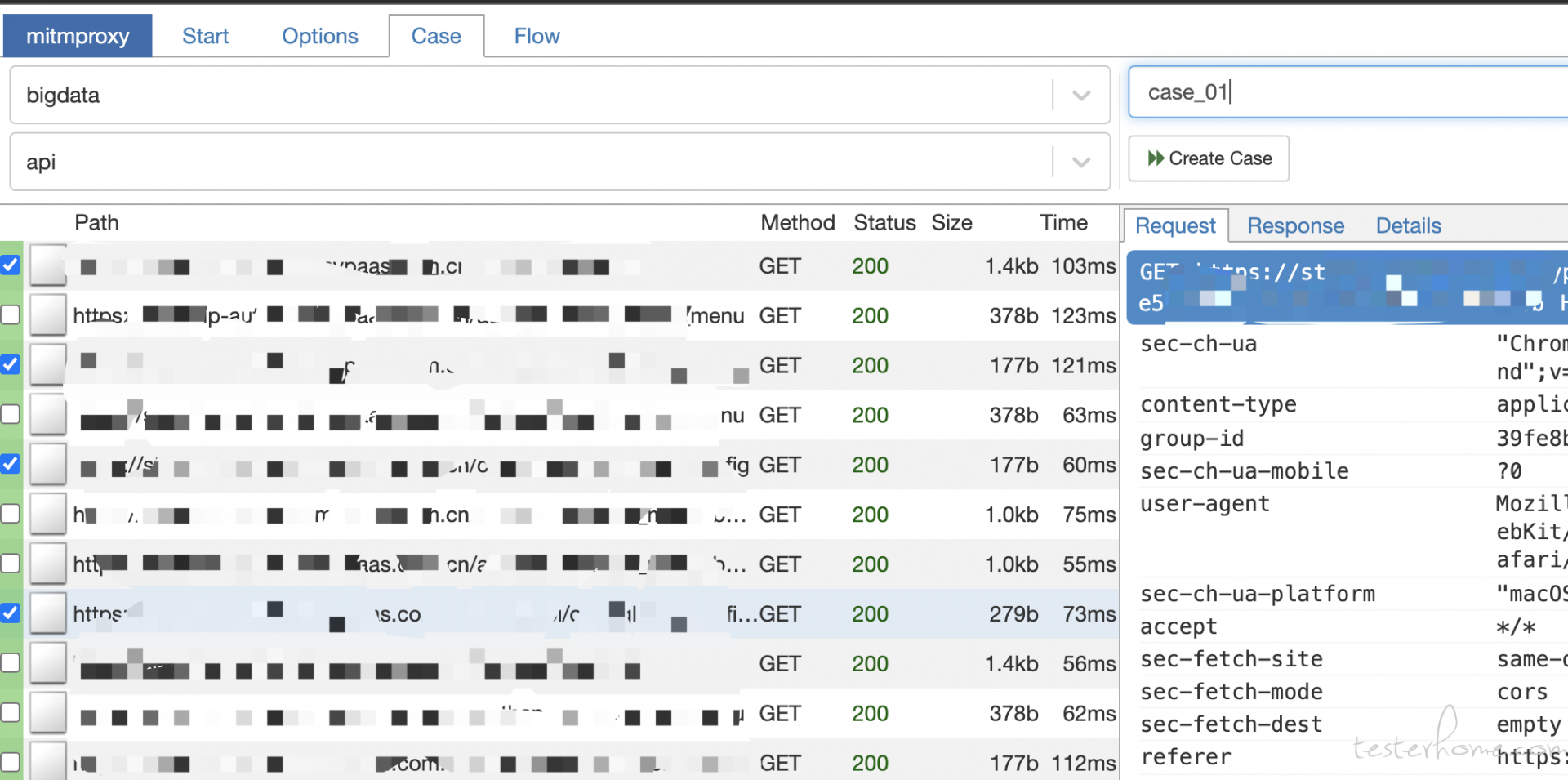
当然还有很多东西需要去做,比如使用 mitmproxy 去结合现有工具开发一个在线抓包的工具,能直接勾选接口转化用例。省去使用 charles 工具;继续优化 web 编辑工具,修复 bug;增加 nacos 里面配置项的验证,如 xx 平台需要使用 es 的某个 index,但是部署的时候 es 的 index 没有初始类似的;丰富更多的用例,不单单是冒烟用例。。。
这个过程也发现,工作中的沟通很重要,从自动化场景的确立,脚本的编写方案,组内维护脚本的工作,脚本的推广使用等,技术和能力是很少的一部分,工作中的良好沟通和配合才是一件事情干成的关键。
管理经验需要提升,现在组内每个人都参与自动化的维护了。组里面每个人技术,兴趣可能不一致,目前还是培训全流程业务和技术,增加绩效考核的手段,虽然组内同事都很支持,配合,但是很多工作都是要安排到具体的事情,缺少主动去发现问题的积极性,后面更多的重心放在这上面吧。
后话
上面说的都很粗,想到哪写到哪,这里做个记录,和大家一同进步~
放一些截图
wiki 归档
git 代码
jenkins 构建
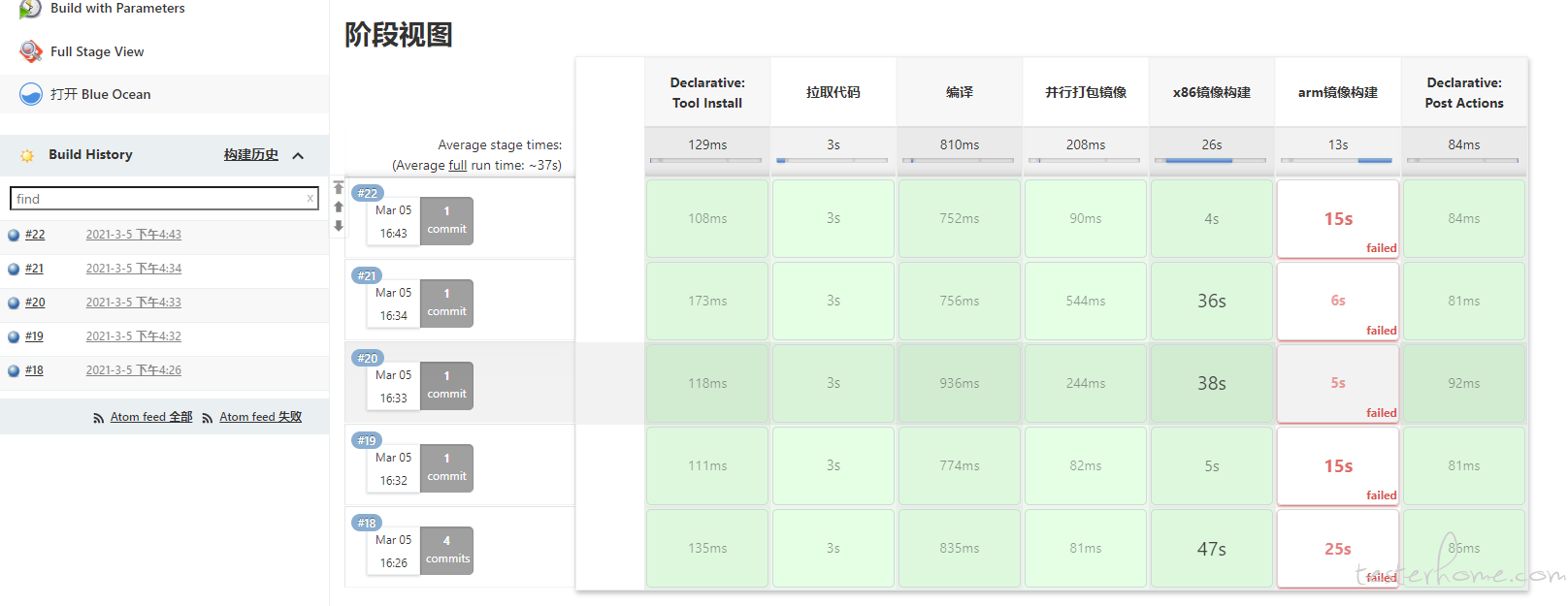
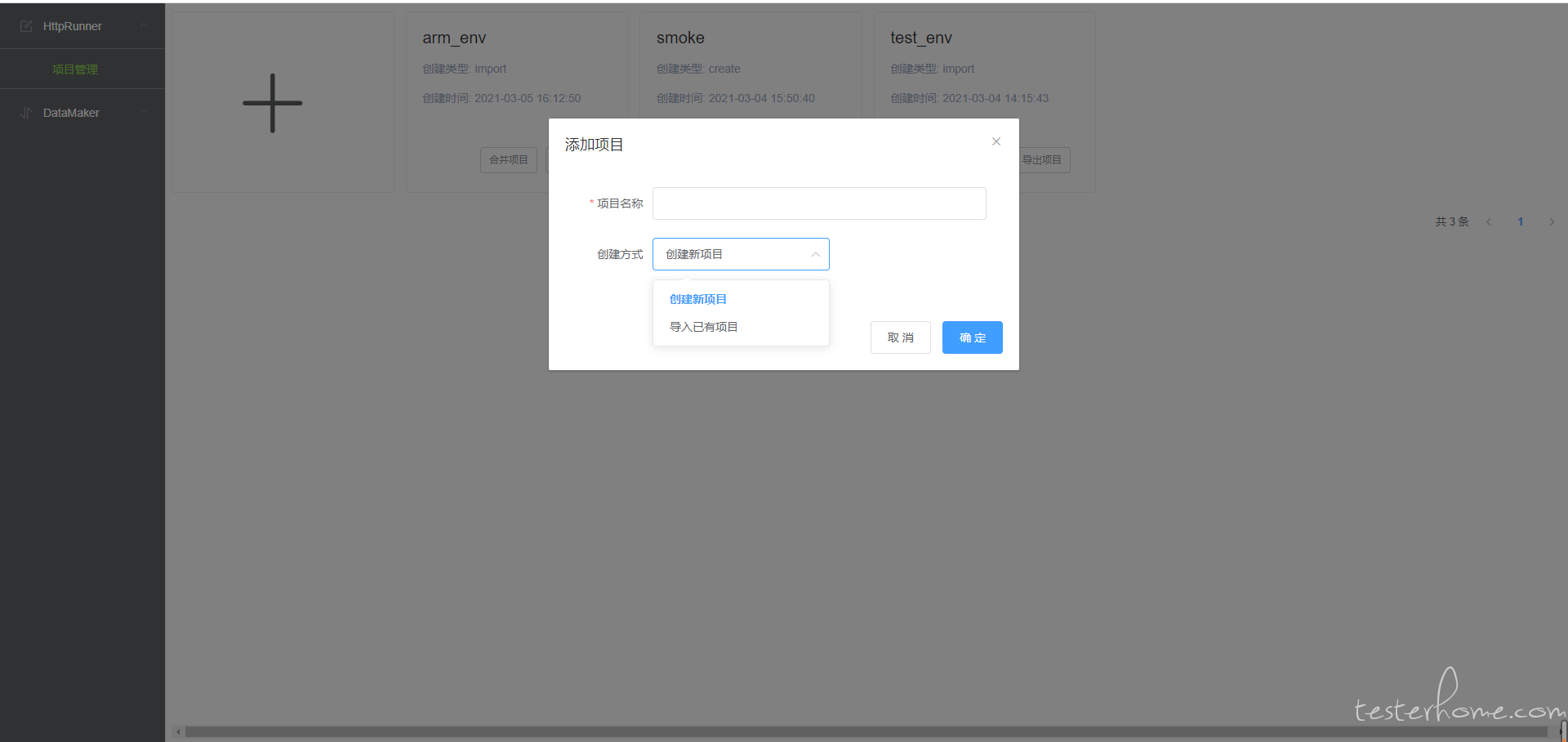
新建/导入项目
运行当前 tab 页用例
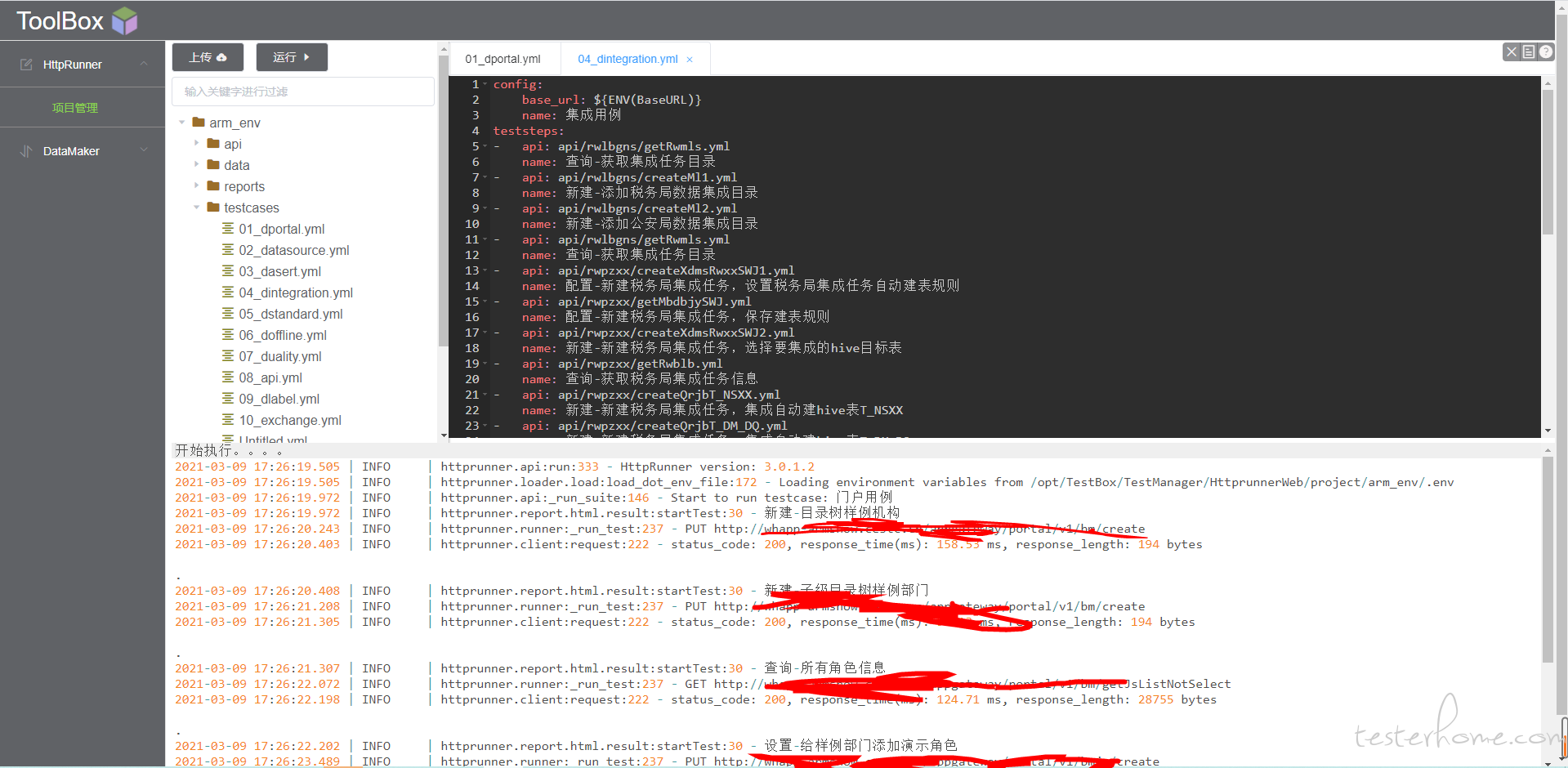
快捷键:保存所有:Ctrl+S 跳转到 API:鼠标选中 testcases 中 api 关键字中的 api 完整路径,按 Ctrl+Q 跳转跳转到函数方法:鼠标选中脚本中的 python 方法,按 Ctrl+Q 跳转运行:执行当前选中的 tab 页脚本,运行完后,右上角会出现查看报告的按钮关闭全部:关闭所有 tab 页,按 Ctrl+F 搜索替换
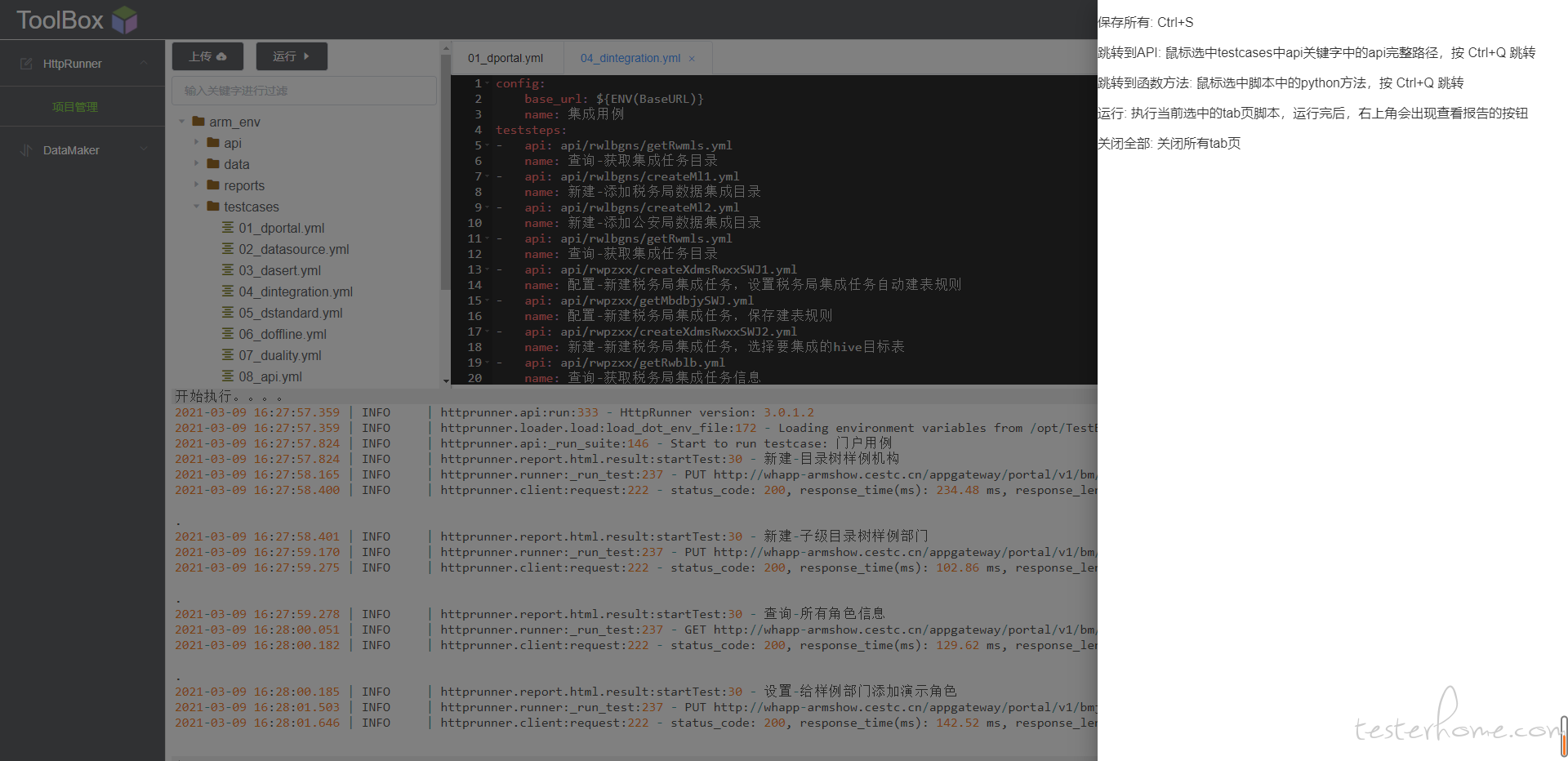
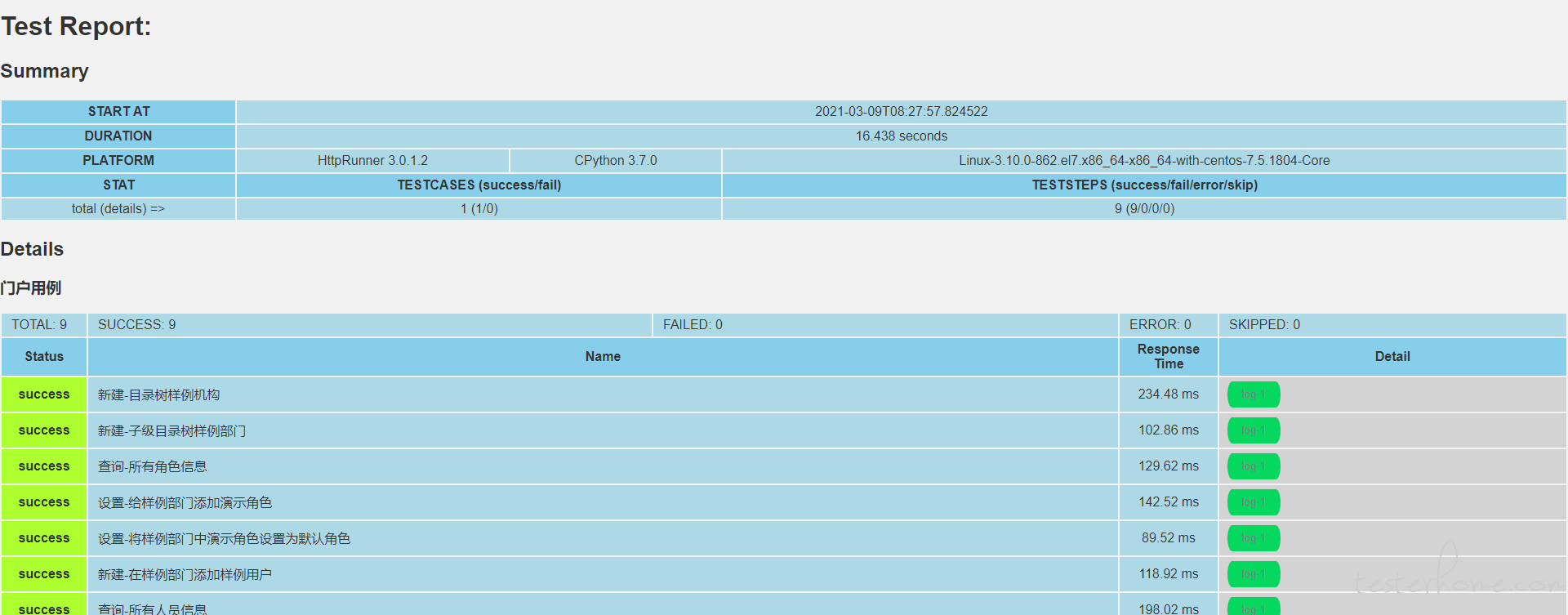
运行完出现报告查看按钮,点击进入报告查看
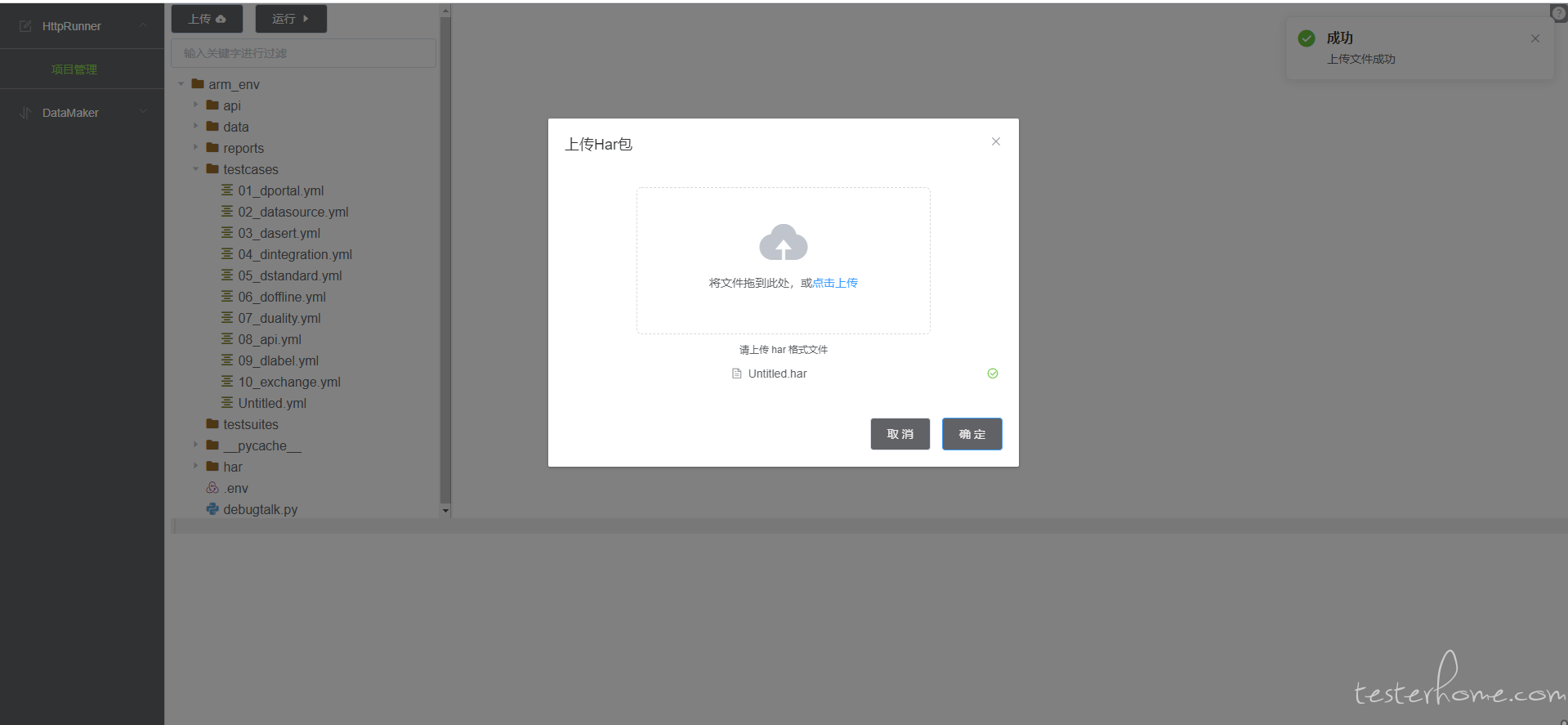
上传 har 包,自动解析生成 yml 用例,自动参数化。
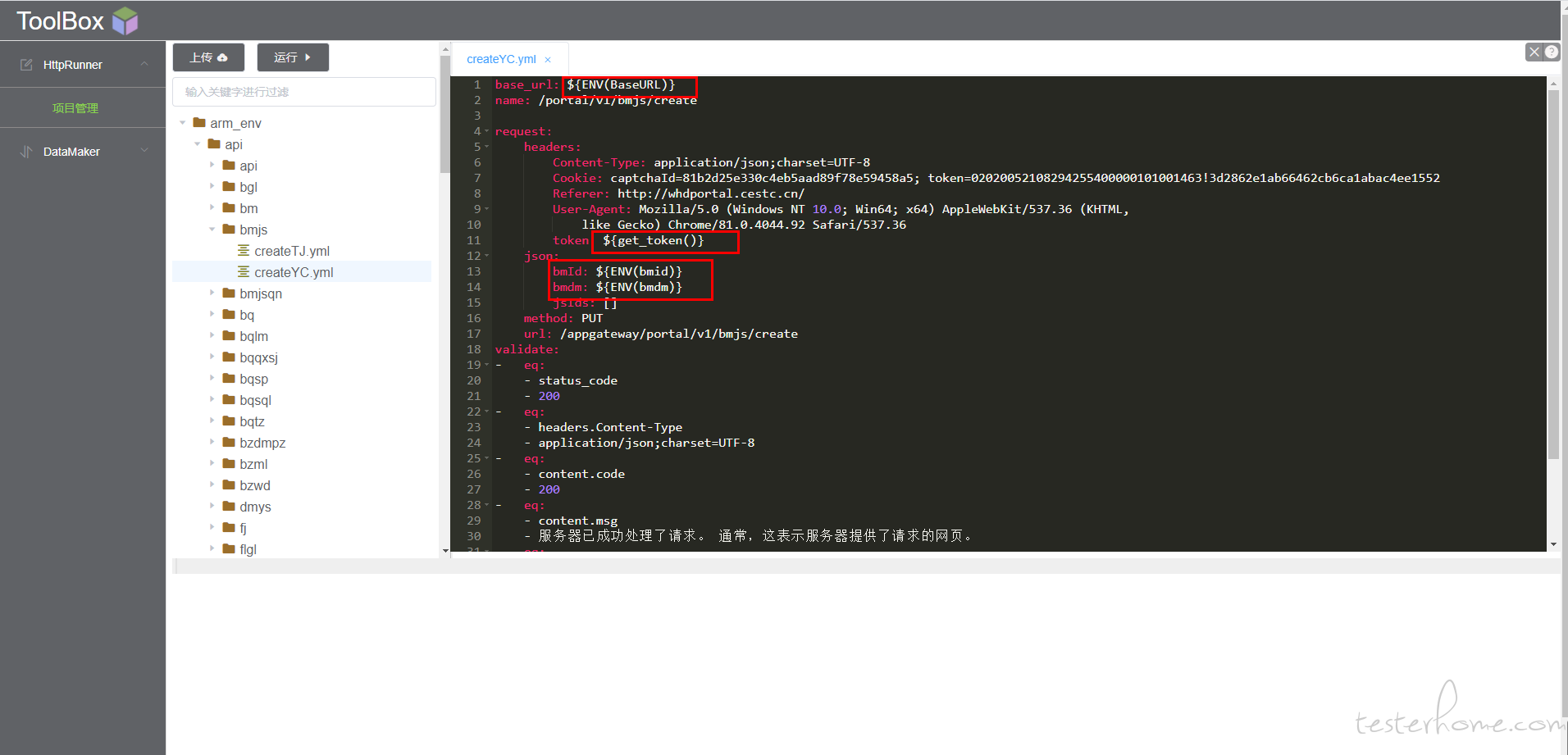
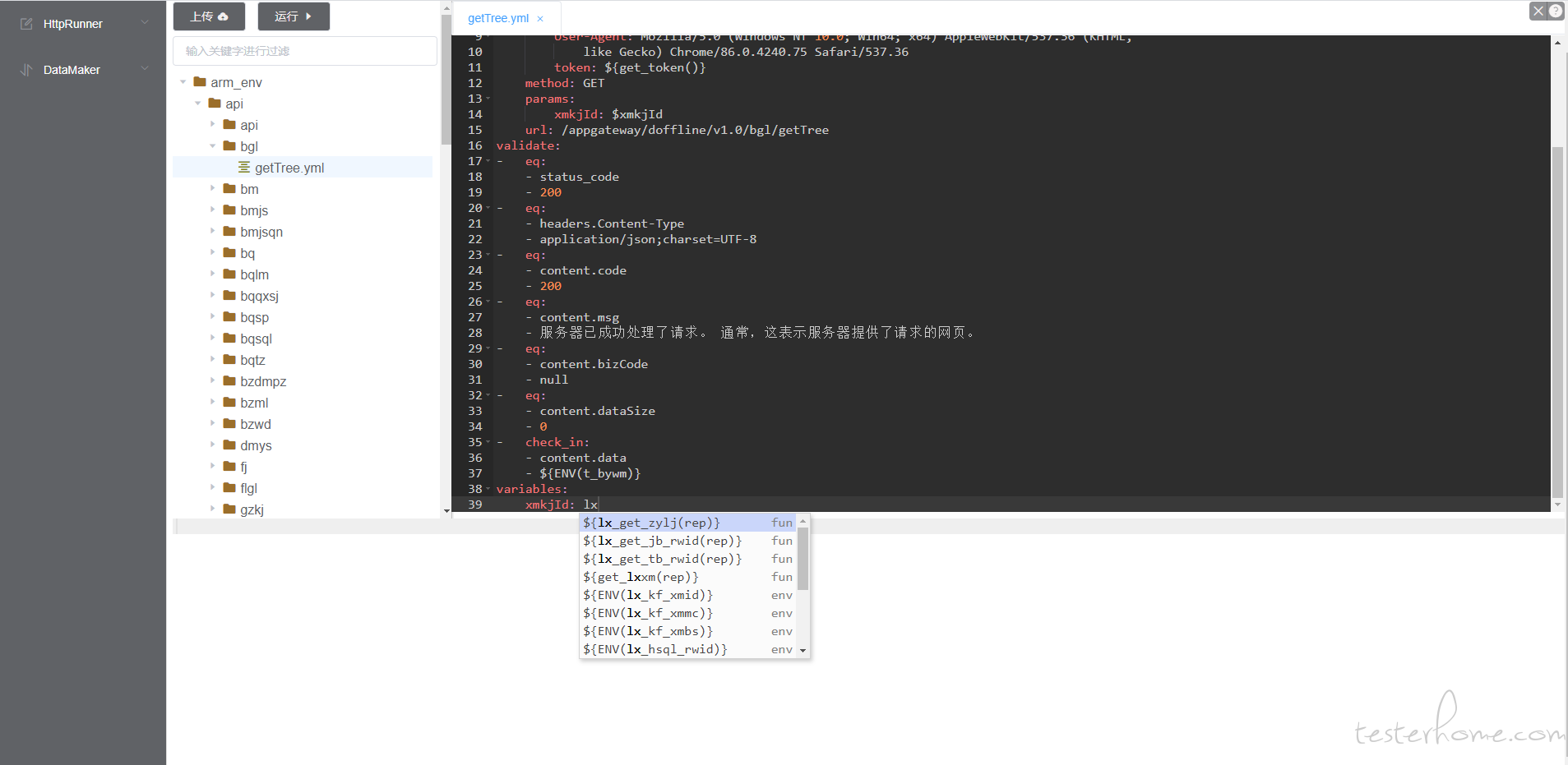
编写 yml 用例能自动提示 debugtalk 和 env 文件里面的函数变量
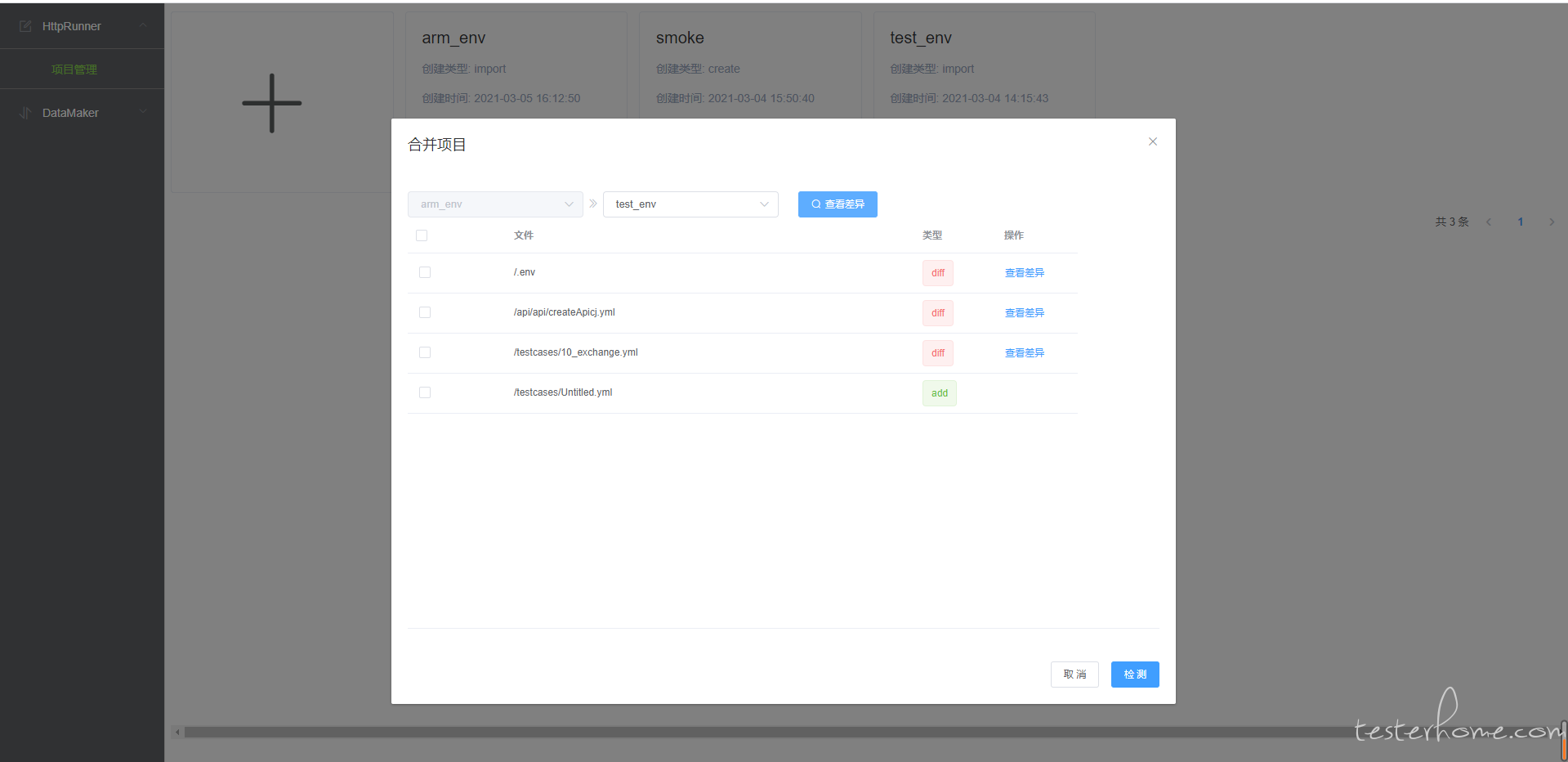
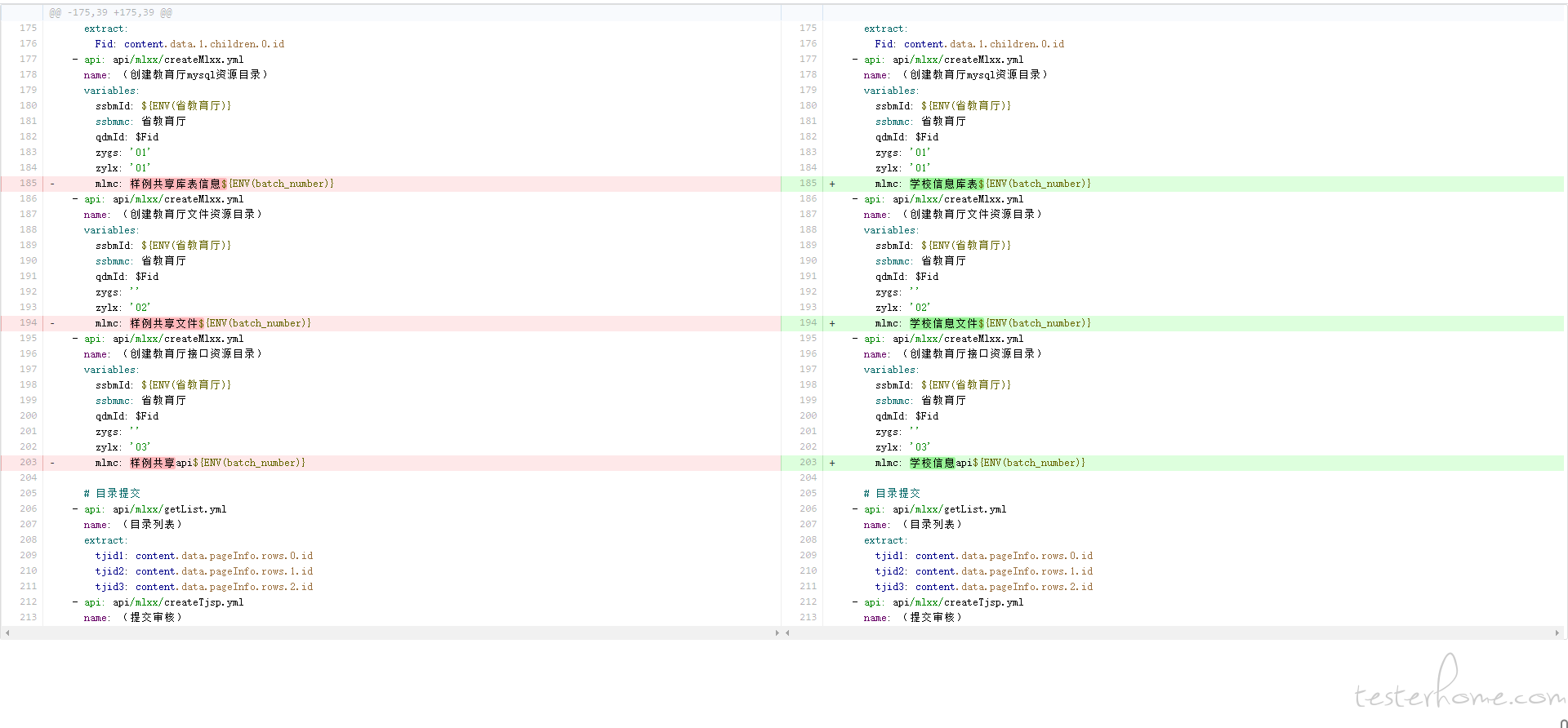
项目合并,比对查看两个项目间的文件差异,选择文件进行合并
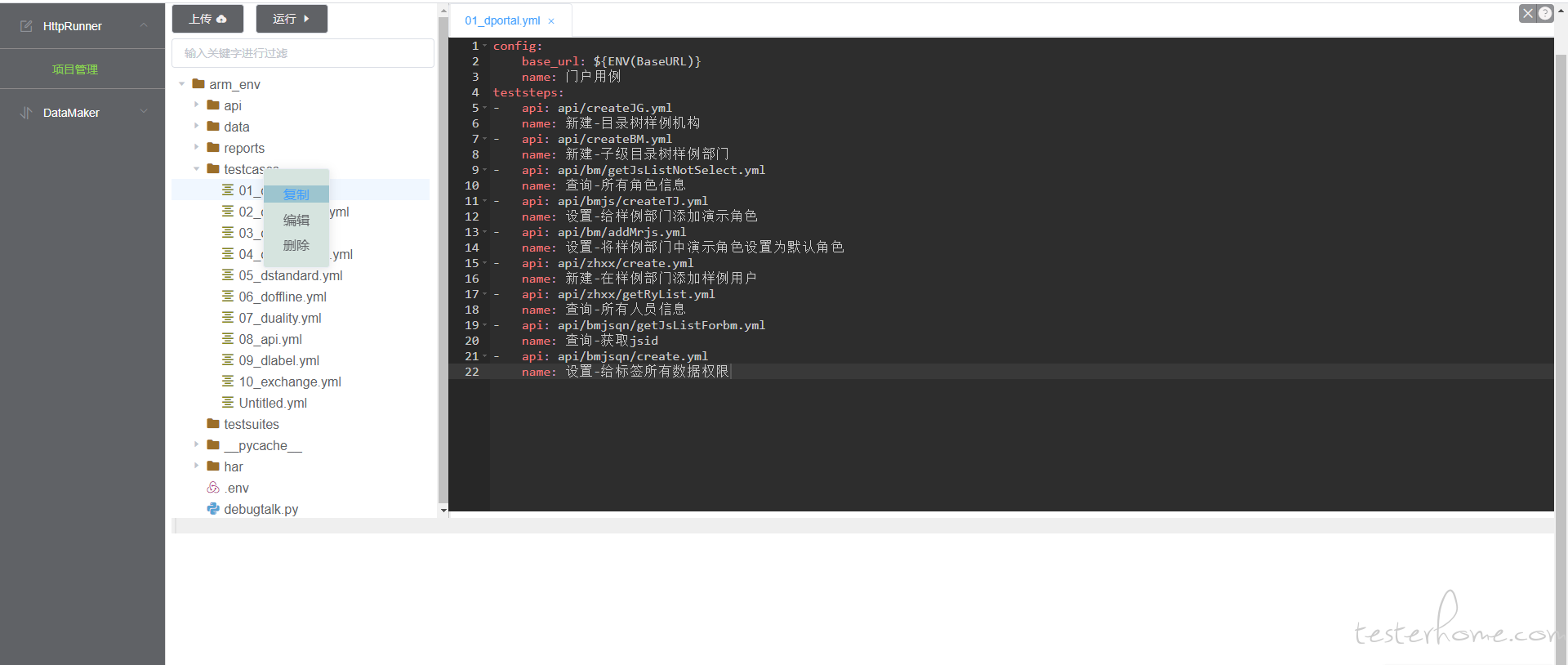
文件的编辑复制删除


 谢谢,还是菜鸟,代码还是流水账的模式 我也是在社区里面向大家学习,看的多了,遇到问题解决得思路就多点。
谢谢,还是菜鸟,代码还是流水账的模式 我也是在社区里面向大家学习,看的多了,遇到问题解决得思路就多点。