通用技术 关于线上监控的思考总结
前言
- 近期和大佬们对规划,梳理新财年要做的事情,有非常重要的一项就是线上监控,对于线上监控,大家都最熟悉不过,凡是在生产环境上运行的系统,或多或少都会有监控,但是否有思考过哪些监控是有效的,监控的目的是什么,监控告警出来之后又是怎么的一轮操作,今天我们来探讨关于线上监控的相关经验
业务系统分析
在实施线上监控之前的梳理,核心还是要对业务系统有比较深刻的了解,才能对症下药,对于业务系统的梳理,可以套一下的框架
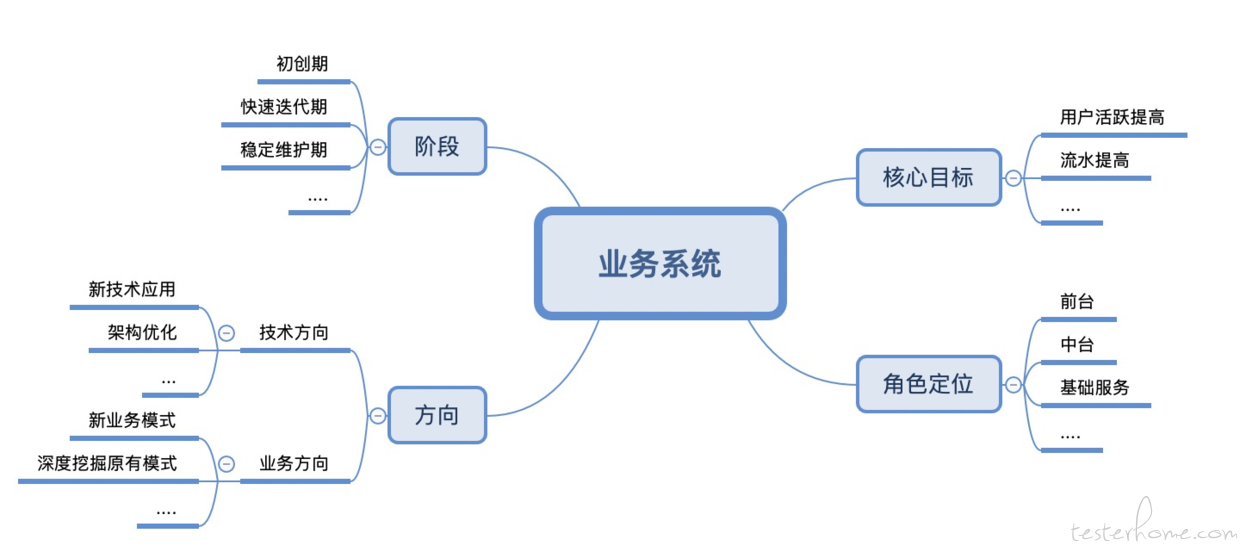
简单举个例子,从阶段来说,一般初创期和快速迭代的系统,业务和功能都未必稳定,这时就不宜去做比较深度的监控,把核心场景覆盖即可,结合系统的核心目标,如用户活跃和流水,对流水和用户活跃数据的敏感度的监控等,同时一般面向外部用户的业务系统都是一个前台的角色,用户敏感度比较高,所以把一些用户高频操作的功能给监控起来,再者要结合当前的技术方向以及业务方向,如技术方向,可以引入一些新技术,或者在原有的逻辑上补充监控点,技术方向有个前提是技术栈统一或相近,不然会加大监控点建立的难度和后期的维护成本,有了前置对业务系统的分析,再实施监控时才少走弯路,降低成本
监控梳理
按照个人的经验总结,我们可以按这样子的一个框架去建立监控体系
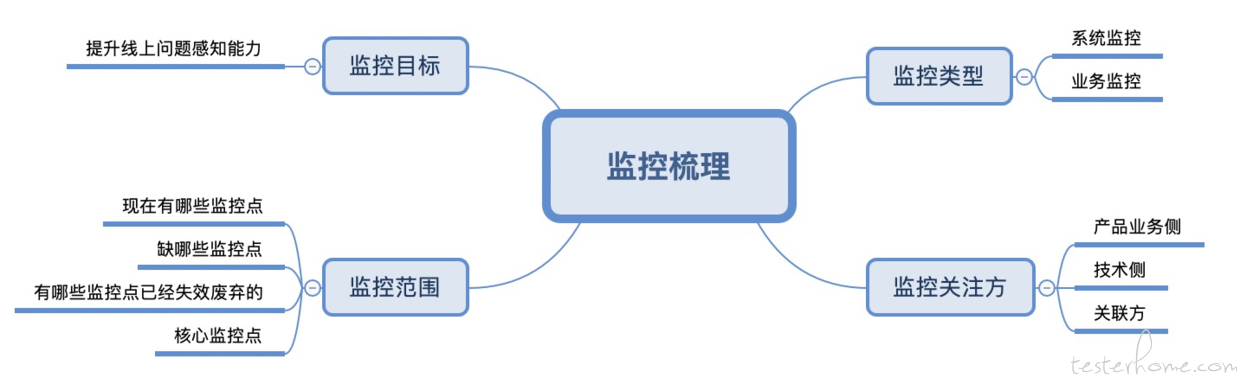
依据上图,我们具体说一下里面的几个大点
监控目标
- 监控的核心目标,就是为了在发现线上问题时第一时间能够了解到情况,同时通过告警信息精准地定位到问题出现在哪里,比较专业的描述就是提升线上问题感知能力,迅速地感知到线上问题,并迅速地定位到问题,用最少的成本将线上问题的影响降到最低,下来的一切措施都是围绕着这个目标去开展
监控范围
做监控梳理的第一个步骤是要明确监控的范围,哪些点是要监控起来的,那就要清晰明确业务系统的架构,技术栈以及依赖方等各种方面,并梳理优先级,简单总结为查缺补漏
1.查找整理当前有哪些监控点,具体的监控范围,从业务覆盖度(功能层面)和系统覆盖度(资源层面,如 cpu 资源等)盘点当前已应用的监控点及其价值
2.检查是否已有监控中是否有由于迭代等因素,已经废弃的监控点,或者是有影响到正常排查问题思路的监控点,已经失去监控的价值的,可以废弃
3.检查是否有核心功能或核心数据等没有监控起来,出现问题的时候往往都是用户反馈才发现,补全监控点
4.检查告警机制是否到位,是否出现确实有监控起来但没有很好的反馈到需要关注的相关人员处,补全告警机制
监控类型
- 我把监控的类型分为两个大类,分别是系统监控和业务监控
系统监控
首先讲一下系统监控,如下图
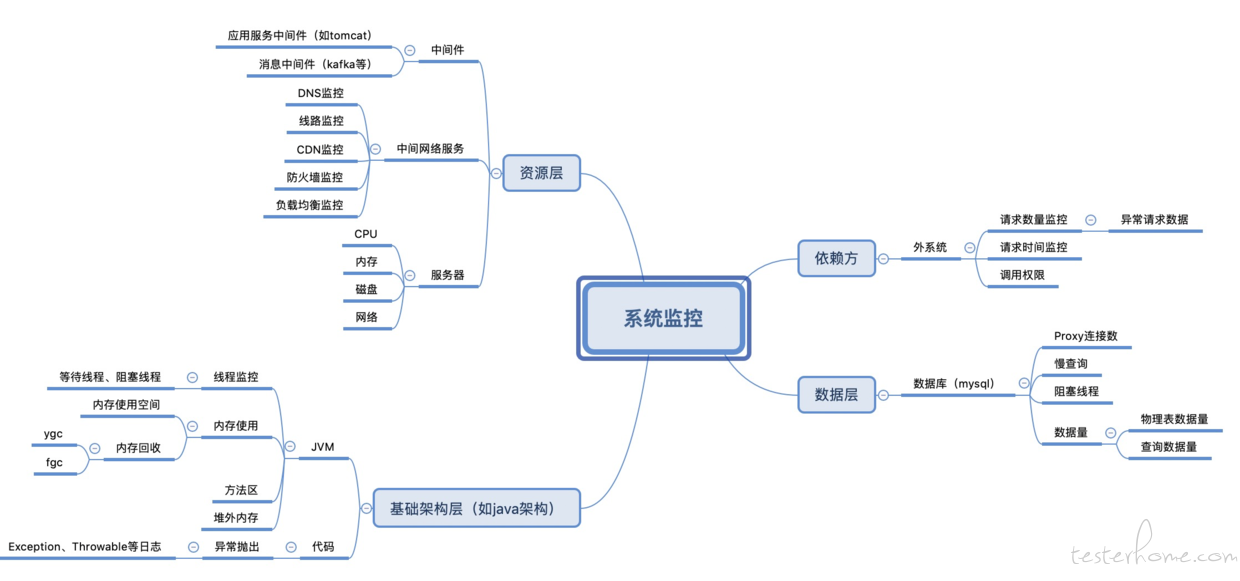
系统监控更多的是关注业务系统所在的环境及其资源的情况,简单理解就是能让系统正常运行起来的先决条件的监控,这里将系统监控分为资源层,基础架构层,数据层以及依赖方
资源层会关注运行环境的硬件等资源,如 cpu,内存,磁盘的使用率以及网络流量等,这也是通用的监控点,同时也是会中间网络服务监控起来,比如 DNS 的访问,保证域名等有效性,是否负载均衡,机器流量分布不均会导致业务流程阻塞,资源也未必很好地利用起来,中间件如一些消息服务是否有出现消息堆积等情况
基础架构层会关注实现业务系统的技术底层运行情况,以 java 开发的系统为例,比如 jvm,一般会对其线程进行监控,如线程占用的内存,内存回收机制是否正常,是否有内存泄漏,同时在方法区,方法的调用情况是否正常,堆栈使用是否合理,代码逻辑异常时是否有正常抛出,日志是否清晰等等
数据层为关注数据库读写情况,比如 proxy 连接数是否在运行范围内,慢查询的数量,数据量的大小以及表的大小会影响读写情况,在一些耗时超时的跟踪上是可以通过监控手段跟踪起来
依赖方这里更多的是关注调用情况,调用链路是否正常,是否有越权调用的情况,调用耗时等各种方面
业务监控
不同的业务系统有不的监控方式,这里只例举一些通用的场景,如下图:
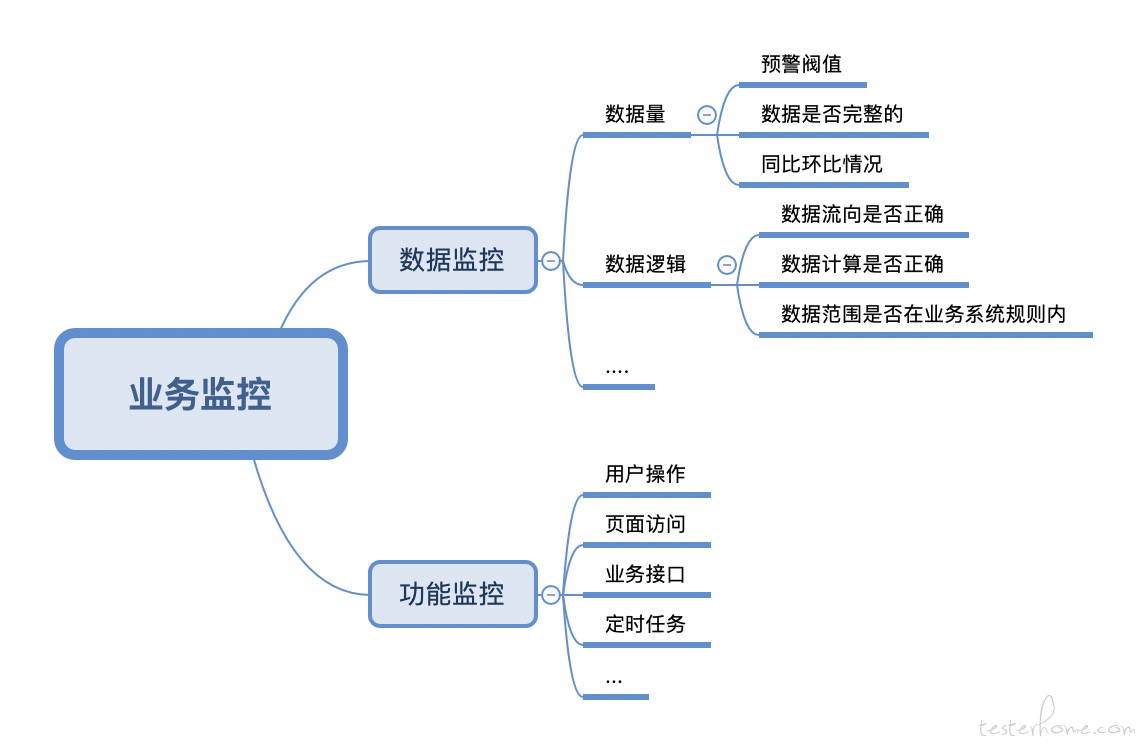
业务监控主要关注两个方面,就是系统功能以及数据
功能监控
- 先说说功能监控,这个很好理解就是对用户的操作行为进行打点监控,比如用户在使用某一功能过于频繁,导致操作被限制,用户由于对功能不理解反馈功能异常,又或者对于获得利益的功能,比如领取代金券领取奖品等,领取是否正常等等,同时关注到业务接口尤其是几个关联接口的使用场景,比如领奖的几个关联接口中的某一个不通或者异常导致整个链路失败的,这时就可以直接根据告警信息来准确地处理问题了,当然这也可以是交互上解决的问题,这里就不扯远了,
- 同时对于页面访问的情况,是否出现白屏,load 超时,页面不兼容的情况,可以通过打点监控获取到相关的信息,如果是 bug 或其他优化问题就可以记录并做日后优化的一个工作项
- 定时任务,在业务场景用应用是非常广泛的,如定时更新游戏里面的任务,定时给用户发奖,定时去获取某些信息等等,监控定时任务的执行情况保证业务流程的正常执行
数据监控
- 数据监控就是针对业务数据来说的,有些业务系统每天都会出业务报表,如果报表中的业务数据变化比较大的话,就必须通过告警让相关关注人员去确认业务数据的变化是否合理,现这种场景,一般就是通过环比同比设置预警阀值进行监控,比如环比超过 10%,就需要告警到对应人员
- 结合业务场景来说,如上面提到的发奖品等,数据层面就要关注发出量和领取量以及库存量,如果有设置了每天发出量的限制的话就要监控是否有超出预值,同时当库存量不足支持发奖活动的需求的,就要即时的告警出来
- 除了数据量相关的监控以外,还有就是数据逻辑功能,比如数据计算,是否和预期值是正常的,尤其是在大数据量的计算的时候,如果一条条找错误数据的话明显非常低效,于是就可以通过监控告警的方式,将不符合既定规则的数据告警出来,就可以精准定位到是哪条数据出现问题,然后再去追溯跟进问题原因
- 不同的业务系统有不同的监控点,所以这里只能聊一下比较通用的场景,业务监控是建立在具体的业务逻辑上,依据其具体的逻辑去实现监控点
监控关注方
- 监控关注方直白意思就是看监控的人,做了一堆监控,对于整个团队来说,是所有建立起监控的点都要关注,但每种职能关注的监控点的优先级是不一样的,产品业务侧会更关注用户行为以及相关的业务数据,毕竟这些告警会影响到产品需求设计上的一些方向,而技术侧会更偏于系统层面的监控,比如一些 error 日志和硬件资源使用的情况,如果作为基础服务的系统,涉及多关联方调用的,关联方也会关注其所涉及的一些依赖接口,依赖数据等告警
- 举个反例场景,线上出现一些资源上的 bug,报了一堆代码信息的告警,然后全往产品经理处发,产品经理看到后最后还是找技术侧去处理,这样的一个信息传递的链路实在是有点长,所以在做监控实施之前,就必须明确什么监控是给什么人看的,这些信息传递得更准确,问题感知的能力才会有提升
监控实施
监控点都梳理情况之后,就可以设计监控实施的方案,这里会涉及需要用到的工具或技术栈,以及对于的一个预警方案和救火方案,可以通过这几个明细项去设计实施方案
1.监控层:比如系统监控中的运行环境资源
2.监控项:比如系统监控中的运行环境资源中的 cpu,内存等
3.监控点:比如网络使用中的网络 io,网络连接数据,丢包率、重传率等
4.监控工具(方案):其实就是应用在这个监控点上具体的工具或者是方法
5.预警策略:当监控工具将对应的监控点都监控起来,我们就能得到相关的数据,依据数据或信息设置一些预警策略,在业务层面上,比如当库存少于 XXX 量时,就告警,系统层面上比如磁盘使用率超过 90% 时就告警
6.告警载体:如以邮件,钉钉等方式通知到关注方
7.关注方:如前文所说举个实际的例子,如下图
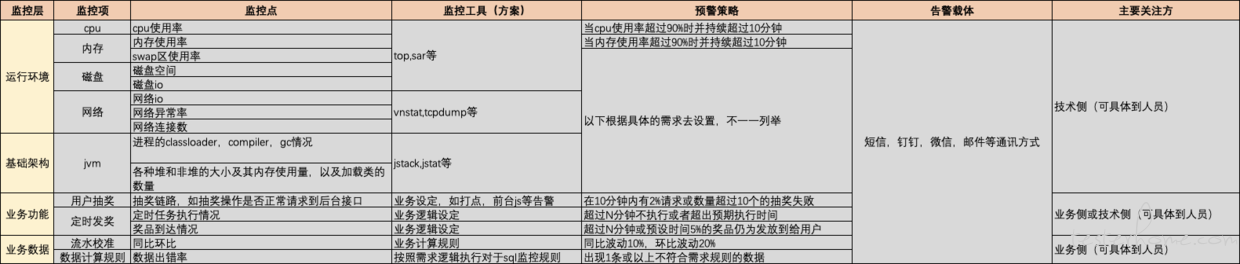
上图通过上述的一部分监控类型举例如果是设计监控方案落地,大家可以参考一下
在监控工具(方案)上面,上述是通过一些点去选择具体的工具或方案,但尤其是在系统监控方面,一个个点用工具去实施维护肯定是不切实际的,现在行业里面也有很多具体的方案或工具可以全面的对系统方面进行监控,比如新型监控告警工具Prometheus,像利用Prometheus+Grafana搭建起监控运维平台,就基本上面可以满足系统监控的实施需求
监控价值评价
- 从盘点到设计到落地,监控是起来了,但作为工程技术人员,实施方案都需要评价最后得到的价值和结果,结合前文做监控的目的,就是为了提升线上问题感知能力,降低排查问题的成本
- 基于这点目的出发,我们就可以记录每实施一项监控点是否满足这个目的,比如做数据计算规则的监控,可以精准定位到时哪一条数据出现问题,而不是自己一条条去排查,降低排查成本,告警梳理完善,信息更加精确地推送到关注方
- 但也有反例,就是实施了监控之后让告警信息复杂化,过多的无效告警信息,或者是不需要关注方关注的信息告警出来,长期以来会让关注方对告警信息麻木,最后真的有线上问题的时候就忽略了重要信息,还有就是实现监控之后对业务系统有较大的代码插入,带来系统 bug,这样也是得不偿失,所以综合来说可以通过判断实施监控前和实现监控后的效果来判断监控是否有效,对于无效监控应当机立断地废弃掉
小结
- 监控方法千万条,有效告警第一条,监控不规范,同学两行泪,不管是线上监控,还是其他方案,从业务的根本需求出发,整体地思考,细致地落地,希望通过本文能为大家在进行线上监控实施时起到一些帮助,谢谢