说明
本文以文字为主,会讲解到理论及具体工作思路,因当时没有保存代码,因此代码部分不贴,也懒得写了;
因内容过多,途中会插入部分表情包,阅读时长 5-10 分钟;
前言
这篇文章修改很多次,各种推倒重写,原因是,一开始只想写自己做过的东西,但是写着写着,觉得太局面,因此想换个大点的角度,能力有限,写的不好或不够,欢迎讨论;
去年 8 月份,做了线上问题跟进的事情,持续到去年年底,后来因进度问题,以及采用的底层方案有点问题,就让研发负责了,从某种意义上,这是第一个完全自主负责的项目;

整个项目对于 Jb 来说是个挑战,同时是一个明显的成长点,后来找工作面试的时候,很多企业对这个感兴趣,问的东西比较细,到现在为止,依然很感恩有这个机会;
一年后的今天,如果要问自己,同样的问题,有没有更好的解决方案?目前来看,没特别的想法,总感觉今年在测试这方面,有点退步了,毕竟今年都在不务正业;
日常骚操作
废话一大堆,来谈主题吧;
相信每一位测试&研发,都会有这日常工作:
跟进线上问题;
无论是 PC、M 端、小程序,只要是面向 C 端的产品,发布后,肯定会有用户反馈问题;
- XX 功能无法使用;
- XX 功能闪退;
- XX 功能充值不到账
相信很多同学都会遇到这些问题,遇到问题别慌,这类问题一般都会有一套应急流程,因不同公司而异,这里只说知道的;

一般来说,线上反馈分两类:
紧急&非紧急;
紧急问题处理流程
一般的紧急问题处理流程如下:
- 客服/运营收到线上反馈,且短时间内呈现明显上涨;
- 通知项目经理/测试/研发,测试尝试重现难问题,研发同步排查代码;
- 能重现问题/研发知道原因,解决问题;如果重现不了,研发排查差不出问题,尝试联系用户及动员更多的同学一起重现,尝试重现;
- 确定解决问题方案(回滚代码/紧急线上处理,APP 则 hotfix 或重新提交各商店),内部验收
- 问题上线后,监控/及时回访用户,观察是否已经解决问题;
- 分析产生问题的原因,总结;
- 复盘,后续如何规避;
大致上是说,就是这么一个流程;
非紧急问题处理流程
而对于非紧急的问题,一般如下:
- 客服/运营收到线上反馈,先确认,标准下不同问题的重现情况;
- 定时整理,比如一周,反馈到测试&项目处;
- 测试确认,如果是能重现,报 Bug 给开发,根据问题严重程度,酌情排期;如果不能重现,也先报 Bug,列为观察问题,后面 3 个版本留意下是否有类似问题或是否能重现,如果一直不重现,关闭观察处理;
- 问题解决,测试通过,安排版本上线,同时反馈到客服/运营处,安排进行用户回访;
- 定时关注线上数据,确保问题已解决,并且及时邮件通知最后的结果;
基本上,这两套流程就能用了,很普通的流程,尤其非紧急流程,内部反馈问题也大概是这样,只是内部反馈,可以及时要现场重现;
一般来说,紧急情况,如果实在找不到解决方案,回滚是最后的方案;
而对于非紧急情况,现实往往是测试折腾半天,无法重现,然后放一边,毕竟工作繁忙,而且反馈的问题也比较多,没可能过多投入;
一旦形成习惯,这类情况一般都会说,无法重现,完,然后没下文了,这也是测试日常的骚操作;

其实从用户角度想想,蛮累的,之前简单统计过,用户主动反馈问题的比例是万分之一,而这万分之一的用户反馈问题过来,测试却说,无法重现就完了,而且也没个交代,犹如石沉大海一般,很打击积极性;
到这里,要知道一点,不能挑战用户,有用户反馈,就说明用户想这个产品越来越好,然而现实很残酷,他明明爱着你,但是你却不知道,舔狗不得 house;

吹下理论吧
上文得知,一条用户反馈来自不易,那如何有效利用用户反馈,以及把没反馈的用户也利用起来,就是需要思考的问题了;
需要注意,用户不反馈问题并不代表没问题,也许用户想反馈问题直接 crash 了,无法反馈,或者有问题模块不影响用户日常使用,jb 也是用户,看到软件有 bug,懒得反馈,反正可替代品那么多,不行就换一个罗;

上面说到的,这里都不介绍,主要想说说自己对质量保障的看法,可能比较片面,但是想增加对线上质量的关注;
目前整个质量环节大致是这样:
- 研发阶段,通过研发自测、概要设计评审等手段尽可能提高交付质量;
- 测试阶段,通过用例评审、丰富测试手段(探索性测试等)来验收产品;
- 灰度验证,快速验证产品上线是否存在严重问题;
- 问题修复,线上问题快速定位、修复;
当然,上面说的只是大致环节,还有很多小环节没有暴露,比如上车检查(代码检查)、monkey、核心数据、集体试用等环节;
看到这里,不得不问,如何在敏捷项目中做好质量管理?
质量管理是一个大环节,并不单单是测试找 bug,而是贯穿项目立项到结项整个过程,比如产品文档规范等都是一环,比如,产品文档模棱两可,研发测试也没有核实,结果成品跟产品要的效果不一致或者有很多 BUG,导致项目延期;
怎么做好质量管理,目前想到两个环节:预防&测试分级;
预防
预防,在项目初期就可以有一定的计划,让项目避免出现已知或可能出现的风险。
提前规避,是检验项目经理对整体项目把控程度好坏的重要考量标准。
而定期检查和调整是保证产品质量的关键,定期召开评审会/晨会,及时同步信息,在此显得尤为重要;
那研发侧怎么预防?目前大众的方案就是静态代码检查、lint、代码覆盖率(jacoco 较多),从以往经验来说,静态代码、lint 的检查,能发现不少编码、性能问题;

测试分级
一般说的测试,大部分指功能测试,但是靠功能测试,不足以保障质量,因此需要对测试进行分级,拆分出更细的测试维度;
- 单元测试,不说,白盒测试的一种,即使大公司也不一定会做,小公司简直别想;
- 接口测试,保障业务逻辑和后台质量,常用是 postman,输入输出,看输出是否跟接口文档要求一致,更进一步,去数据库修改数据,来校验后台处理逻辑是否正常;
- UI 测试,保障到 C 的体验跟交互;
- 性能测试,保障整体业务性能和稳定性,满足大环境需求;常见的性能监控有稳定性、启动速度、卡顿率、流畅度、内存、耗电、流量,服务器的话,就是 CPU、内存、IO、并发用户数、响应时间、事件成功率、超时错误率,可能有遗漏,欢迎提出补充;
- 安全测试,保障系统安全性;比如涉及到下载,需要考虑到劫持场景,充值功能,需要考虑网络传输是否加密以及是否有破解方式;
- 自动化测试,主要是用户回归测试和常规验证,比如某些配置项、主路径功能等;
自动化验证和持续交付
互联网的节奏非常快,想在高强度的氛围保障质量,是一件很有挑战性的事情,换个角度,是否有不需要测试就可以直接上线的情况?
如果想达到这种情况,要做什么?
这个话题就更大了,jb 也还在学习 ing,但上面有提及到,静态代码检查、看研发代码等,除此,代码覆盖率、自动化都是提高质量的一环;
但有一点是肯定的,要做这块,必须要懂代码,记得前前前老大跟 jb 说过一句,好的测试,编码能力应该要比最差的研发要强;
上面说的都是台前,那我们也要关注幕后,因为质量并不是一环;
那幕后有什么?打包效率、提测质量、上线部署、线上质量监控,这里不像详细说明,直接贴一个图;
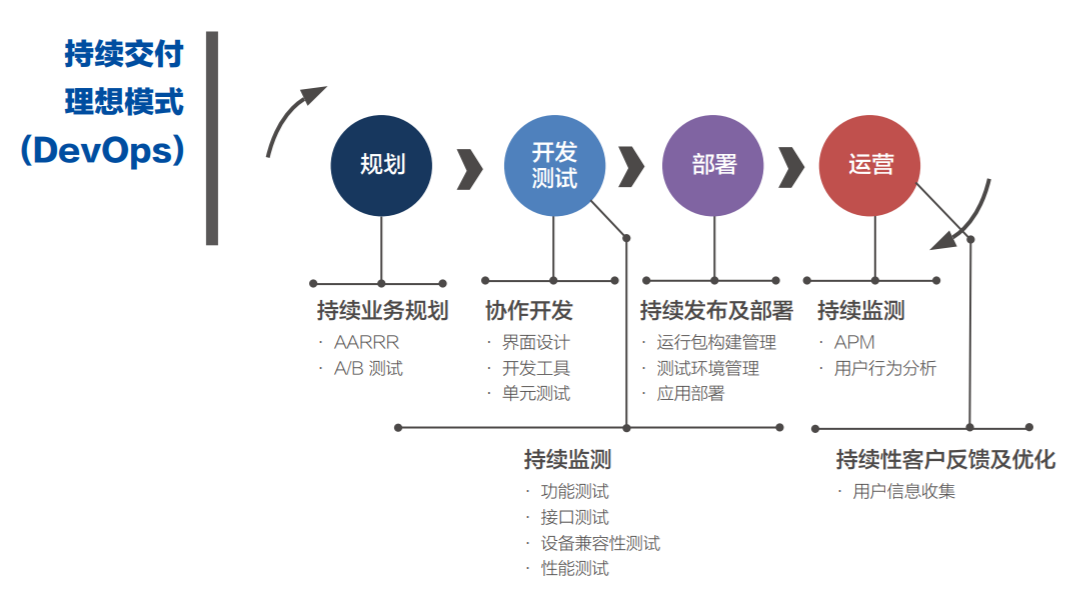
从性价比看,发布部署是性价比最高的,直接弄个 jenkins,写点具体发布脚本即可,收益是最高的;
别少看打包效率这类问题,一人打包 10 分钟,2 人打包 20 分钟,如果提高到 5 分钟,那 1 人就节省 5 分钟,100 人就节省 500 分钟了,亲身经历,这类问题不能轻视;
其他的提测质量、线上监控,都是很大的点,这里不说;
质量管理优化
不管什么公司,多多少少都会有不同的问题,只是,在大公司里面,往往通过协助平台、流程规范等方式把问题解决或屏蔽,但是在小公司,问题就会暴露出来;
做质量管理不容易,需要强大的内心,而且,公司资源向你倾斜,只有这样才能真正推行,否则如石沉大海;
遇到问题,不要慌,这里介绍三步走:
体系状况,分析梳理
古人云:工欲善其事,必先利其器,想优化,必须得先知道病在哪里,那不妨从以下几个维度去了解问题;
- 了解公司总体业务现状
- 了解各业务产品应用架构、技术架构、团队组织架构及分工配合情况
- 了解业务和产品需求以及未来发布规划
- 收集核心业务质量现状数据,明确需要优化的方向,优先级,排期处理;
- - 研发流程现状数据
- - 产品质量问题数据
- - 测试质量问题数据
- - 质量流程问题数据
- - 团队协助问题收集
- 诊断分析并找出问题根源(流程、方法、标准、工具、协助、规范等)
- 根据以上的问题以及具体原因,初步给出一个改善建议的且可行的优先级;
质量流程,优化设计
上面给出了初步改善建议,那接下来就要规定流程,针对具体问题制定规范,明确每个职能部门的分工;
- 确认目标,即做质量前后有什么变化,要解决什么问题;
- 根据上一轮诊断信息和优先级顺序,进行优化方案设计
- - 团队角色及分工定义
- - 基本流程定义
- - 流程相关工具平台选择,比如 UI 用 A 工具设计,测试报 bug 用 B 平台等,确保统一
- - 初步质量目标和模板定义
- - 选择试用产品/项目和推广顺序
- - 实施计划和风险分析
- 方案讨论,修改,然后跟具体大佬沟通,得到认可后推行
- 组织团队培训,敏捷思想和方法
质量规范,部署实施
定下规范,就去试试吧;
- 关键环节控制流程部署和实施
- - 需求跟踪
- - 测试设计
- - 研发编码、提测
- - 发布验收
- 全面流程管控和标准化
- 建立自动化测试平台体系
- - 接口测试
- - UI 测试
- - 性能测试
- - 安全测试
- 构建持续集成和持续测试
- 质量保障持续优化机制建立
业界也有个词,叫测试左移,简单说,就是让测试提前介入所有流程:
- 需求评审,测试必须对业务熟悉;
- 技术方案评审,测试能读懂和理解技术方案,凭丰富的经验或者嗅觉,挖掘技术方案不足的地方,比如业务场景的可扩展性,业务量大幅增加后的性能问题、可测性;
- 测试用例和业务编码并行,包括接口测试用例、功能测试用例,准入标准,功能都无问题,回归脚本全部通过;
- 单元测试质量,除了保障代码覆盖率之外,还要检查 UT 代码的有效性;
- 静态代码分析,有能力则协同开发一起保障代码质量,或者引入第三方工具,准入标准,没有严重级别的问题
- 代码审查,同需要代码能力;
- 测试用例评审,提测前组织产品、研发、测试一起完成,提测后直接使用;
- 冒烟测试,提高提测质量,要通过冒烟才能提测,准入标准,比如没有主路径问题;
更详细的,自行上网查询;
大家怎么玩
上面啪啪啪的一大堆废话,本文的重点在于线上质量,那就聊正经事情吧;
问题一般分两类,性能问题、功能问题,体验问题不算在这里;
性能问题能通过一定的规则来抓取,比如获取当前 APP 的内存,是比较固定的内容:
- 定时查询统计
- 有问题直接落地生成 log
- 日志回传到服务器
- 服务器解析日志,做聚合统计入库
- 前端查询展示数据
那,在跟进线上反馈的时候,到底遇到什么问题?

- 联系上用户,但因各种问题 ,问题没法跟进了或者需要的 log 拿不回来,怎么办?
- 压根联系不上用户,怎么办?
记得是在去年 2 月份,上 testerhome 发帖子问,幸运得到部分大佬答复,看到的方式有 2 种:
- 部分企业有大量 log(用户行为日志),通过 log 分析出用户行为,然后内部排查问题,发现是问题处理,不能发现的,线上增加埋点 log;
- 内部重现,如不能重现,则联系用户,给各种调试包等,联系不上的,放弃;
很不好,当时就是处于第二种,只是觉得,即使是联系不上的用户,也不能浪费;
怀着这份激情,跟老大反馈多次,逐渐的,老大们也开始关注到这块,因此就立了个专项,让 jb 去负责处理这个事情,因此,这个事情的开端就是:如何跟进线上问题;
这里更多指的是,无法联系,或者联系了重现不了之类的用户;
既然大家都是依赖 log来玩,那我们也这么玩吧;
题外话:虽然很不喜欢处理线上反馈,但遇到暖心的用户真的很感动,幸运的是,jb 遇到不少,远程各种协助跟进问题,好人还是不少的;

独乐乐不如众乐乐
既然问题核心是没有 log,导致无法跟进问题,那换个角度,有怎样的 log 才能跟进问题?
因此,有了以下的内容:
- 当时产品里面有很多收集性能日志功能,比如卡顿、内存、启动速度,只是都不会在 release 版本开启,因为收集日志本身存在性能问题;
- 那用户行为日志是不是也可以跟性能日志一样收集?
- 但是,不在 release 版本开启,做了也没意义,那,有没有办法做到在 release 版本开启这些日志功能?
- 如果支持 release 版本开启,那怎样的日志内容能满足不同业务进行跟进问题?毕竟不同业务需要的日志内容不一样;
- 日志什么时候保存?保存在哪里?什么时候回传?回传到哪里?回传到怎么处理?
这就是第一期的目标-发现问题;
上面的问题如何解决?
Q:如何在 release 版本开启收集日志功能?并且支持动态关闭?
A:push,产品本身支持 push,有独立 push 通道,即使用户退出 APP 也能收到 push 消息,
因此,针对不同模块(用户行为日志、卡顿、启动速度、内存等)做独立的标记,定好协议,客户端收到 push 消息后做协议解析,然后修改对应模块的标记,APP 重启后做判断,这样就可以达到动态开启\关闭的效果;
Q:怎样的日志内容能满足不同业务进行跟进问题?
A:这是个问题,一开始想着做全家桶,但是后来发现不适合,原因是业务方只会关注自己业务的出错日志,如果弄全家桶,业务方过滤日志需要大量成本;
因此觉得,封装一层提供接口,提供一个写日志的接口,业务方根据协议来传对应的内容即可;
这样,一份日志可能会有多个业务方的内容,没关系,因为格式是固定的,日志回传到服务器后,服务器脚本做解析,最终会把一个日志根据格式内容拆分出 N 个日志,这样拆分出来的日志就是对应一个业务方的日志;
********************************************
# 此处公共模块信息
版本号:XXXX
子版本号:XXXXX
流水号:XXXX
时间:XXX
模块:小说
********************************************
# 具体业务日志内容
********************************************
********************************************
# 此处公共模块信息
版本号:XXXX
子版本号:XXXXX
流水号:XXXX
时间:XXX
模块:搜索
********************************************
# 具体业务日志内容
********************************************
Q:日志什么时候保存?保存在哪里?什么时候回传?回传到哪里?回传到怎么处理?
A:这里面,只有日志什么时候保存是关键;但是这里不细说过程,最终选择的是xlog;
微信开源的一个收集日志库,好处就是,不需要自己处理各种逻辑(比如日志文件限制多少 M 后拆分等),直接初始化,然后 XLog.d 就可以用了;
xlog 是后面换的,一开始是自己折腾的,浪费不少时间,所以,造轮子之前,想看看有没有好轮子,避免浪费时间;
因为有个业务是联网业务,因此选择软件启动后就异步初始化,只要业务方一调用 XLog.d,就会有文件生成;
Q:什么时候回传日志?
A:这里要解释下,一般情况下,日志不会回传,上面都说了,要解决两个场景,
- 1)用户不反馈;
- 2)用户反馈但是没日志;
如果是用户主动反馈,则在点击反馈的时候,先把日志上传,得到一个地址,然后再把地址传给客服系统的接口,
这样就能在具体反馈里面看到具体日志,当然这个是原始日志,需要解密处理,因此会再传一个解密后的地址,跟解密服务器约定好的格式;
如果用户没反馈问题,那就在业务出错时把日志上传,业务出错的时机交给业务方自行判断;
部分业务是没办法识别到出错的,比如联网业务,因此这类业务采用日志先落地不上传的策略,需要时通过 push 拉取日志;
至此,第一阶段,发现问题,到此结束;

看看干了啥
既然有日志了,那对于测试同学来说,比较方便了,如果没记错,问题解决率在 30% 左右,看上去觉得很低,但实际是因为,很多功能研发还没埋点,算是一个不错的效果;
点对点的问题解决了,那点对面了?从项目的角度,想知道线上什么情况,怎么搞?
因此专项第二阶段就是监控问题;
其实,监控问题,没有太多的内容可以说,无非就是把日志如何解析,聚合,数据处理再显示而已,最终的效果就是,点击某一个版本,选择某一个模块,就可以知道这个模块收集到的日志排名,研发根据这个排名依序解决问题就好了;
换种方式踩坑
做完上面 2 个阶段,时间到了 10 月初,期间从立项,方案,调研,编码,灰度,推行都花了不少时间,尤其在推行这一环节,要有具体数据来吸引业务方来使用,不然做出来没人用是很尴尬的事情;
这时候,既然产品有这样的功能,想让用户有意识使用,说白就是想增加曝光,有如下的想法:
- 新手引导用户
- 产品首页增加悬浮框告诉用户
- 简化用户反馈的路径(原有路径有 3 级,比较麻烦,业界大部分产品也类似)
但是 1、2 被产品经理打回,原因是,用户反馈这个功能不是每个用户都必须的,为了那点人而浪费一个新手引导位,不合适;
当时听到很不舒服,但是事后回去站在场景的时候思考,有点道理,打脸了吧~

那就想办法简化用户进行反馈的路径吧,经过思维的碰撞,内部觉得,在产品上三指长按一定时间弹出反馈界面,是一个不错的场景;
跟产品沟通后,产品觉得可以,那需求就为:用户三指同时长按屏幕 2S,弹出意见反馈页面;
从此,跌入深渊,自己给自己挖了一个大坑;
跌入深渊
需求很简单:用户在 app 内使用三指长按屏幕 2s,APP 执行某操作;
挖坑
需求关键字:三指,长按,2s,执行(这不是需求原话么)

当时的处理逻辑是这样的:
- 判断用户手指个数
- 如果是 3 个,设置一个 runnable 2S 后执行
- 执行时再判断用户手指个数
- 如果还是 3 个,执行操作 A,over
(懂的大神已经笑了~)
当时信心满满的上线后,发现使用的 uv\pv 都非常高,非常不合理,因为 app 上没有功能引导,用户也没有三指的行为习惯,所以肯定是出 bug了;

跟进这问题 2 个步骤,
- 看用户反馈,结果上千条反馈,都没有一条相关反馈,那是否可能是打点问题?
- 查看统计代码,也没发现异常;

问题到底在哪里?
新增了用户的场景统计,发现部分用户在色情网站会连续出现打点,本地尝试没发现问题,就让其他同学帮忙用用,结果发现问题了!!(一个人的力量是有限的,理解也是有限的~)

原来用户是有多指(3 指及以上)进行缩放的习惯,如果用户是使用三指进行缩放,而且还是一直在屏幕不停缩放(即没有手指离开屏幕),就会出现问题了;
因为代码只判断触发前后的手指个数,中招了!(事后跟产品沟通,这种用户可能是平时有用 iPad 的习惯。。而色情网站是用户在看图片或者漫画,为了看得更清晰,所以需要缩放,就出现问题了,但是还是没想懂如此明显问题,居然没用户反馈?)
噗,多明显的设计问题啊~!
二遇坑
重现后问题就好办了,逻辑重写,处理 event 事件,触发逻辑不变:
1)当用户手指个数为 3 个且每只手指按下时间差不大于 50ms(防止用户是一只手指点击后再放第二只手指,这种场景是无效的,因此设定个两个手指的时间差),就会设置一个 runnable 2S 后执行;
2)其他情况,长按后,产生 up 事件(有手指抬起)、move 事件大于一定距离(认为用户在滑动)、大于 3 只手指,这些场景都会把执行 removeRunnable 操作,则把 runnable 取消,避免触发操作 a 逻辑;
这样算是把门槛调高了,上线后,误触发的占比大幅下降,但是,仍然有百分之一的用户误触发,虽然人均 pv 大部分为 1!!
对比原来动不动误触发,的确是有优化效果的,但是,百分之一的 uv 也是很困扰~
经过好几轮灰度,最终发现一个问题,问题用户的 event 常规统计数对不上,那说明有其他没有统计到事件在一直执行,最终发现是 cancel 事件!!!
再次懵逼,cancel 事件理论上是不会触发,至少自己本地用几台机器都没出现。
android 文档的说明很简短,想看明白很难。国外一网页说的还比较详细,写在这里分享给大家:
原文是这样的:
You receive this when a parent takes possession of the motion, for example when the user has dragged enough across a list view or scroll view that it will start scrolling instead of letting you press the buttons inside of it.
意思是这样的:
当你的手指(或者其它)移动屏幕的时候会触发这个事件,比如当你的手指在屏幕上拖动一个 listView 或者一个 ScrollView 而不是去按上面的按钮时会触发这个事件。”
当时懵逼,我们的场景没有这种行为,为什么还会有 cancel 事件,肯定有其他原因,最终终于找到了:
“当控件收到前驱事件(什么叫前驱事件?一个从 DOWN 一直到 UP 的所有事件组合称为完整的手势,中间的任意一次事件对于下一个事件而言就是它的前驱事件)之后,后面的事件如果被父控件拦截,那么当前控件就会收到一个 CANCEL 事件,并且把这个事件会传递给它的子事件”;
划重点:被父控件拦截!!
最后经过多次验证,的确是被拦截了,但是,是被 rom 拦截了!
通过统计数据,发现 oppo r9 及以上机器很容易出现该问题,人均 pv 高达几十次,后来找来机器验证,发现问题了:
原来这些手机系统上自带了一个三指上/下滑动进行手机截屏的功能,而原理就是监听 event 事件,如果发现手指个数等于 3,操作系统层直接返回 cancel 事件;
而客户端没有针对 cancel 事件做处理,因此导致逻辑继续跑,意味着用户执行系统三指截图功能时,顺带把 app 的这个三指功能也触发了~
这个问题已经跟 oppo 的研发沟通,的确如此,而且一加、小米、魅族等新机器都有此功能,如果手动在系统设置把系统的三指功能关闭,则 app 的三指功能恢复正常,再次验证这个假设;
虽然发现了问题,但是开心不起来,因为后来发现不同厂商虽然都有这功能,但是实现的方案不一样,这里不细聊,后面权衡后,决定对 oppo 的手机做兼容处理;
(系统逻辑是三指长按后滑动,我们的逻辑是三指长按 2s,其实还有区别,但是被系统强奸了。。)

处理方案讨论了好久,也好了好多大神沟通,纷纷表示没办法,毕竟是操作系统返回的,你能怎么办?话虽这么说,但是后来还是针对 cancel 事件做了特殊的处理;
通过调试发现,一旦触发这种 cancel 事件,oppo 系统会一直返回 cancel 事件(原理是触发 move,系统把所有事件触发都返回 cancel,对于系统而言,move 是很高频的且很短,而如果真的触发了系统的截屏,每次截屏耗时基本在 200ms 以上,针对这一特性做手脚)
1)在收到 cancel 事件时,判断之前触发的 runnable 是否已经存在;如果存在,则手动把 runnable 取消;
2)如果每次 cancel 事件大于 200ms,则认为触发了系统的截屏,则把这个事件相加保存起来,原因是排除 move 事件的影响;并且执行次数 +1;
3)当执行次数少于 15 次且时长大于 2s,则认为满足条件,此时判断是否为 3 只手指且没明显滑动操作,如果是,则立即触发执行操作 a;(设置次数是为了提高门槛,不然随着次数的增加,肯定会有达到 2s 的情况,这样就没意义了)
代码上线了,虽然不是百分百杜绝误触发,但是占比再次下降,基本达到万分之一,这事后来就不折腾了~
如果有更好的解决办法,欢迎一起讨论,这个方案并非合理方案,只是简单处理,而整个功能虽然一句话,但是从编码到最后发现,用了一个月多点,而不停灰度收集统计是时间的大头~
小小结:
- 研发的概要设计文档流程还是需要的,别以为只是一句话需求就不做了;容易陷入想当然;
- event 容易出现兼容性问题,厂商有可能做了定制处理,这块要切记;
爱理不理
既然用户反馈这么重要,是不是每条都需要跟进?
答案也是否定的,给自动化一样,自动化很重要,那是不是所有项目都要做自动化?同理而已;
有一类产品,不需要做过多的线上闭环这么一个流程,是跟钱相关的,比如 P2P,理财类;
为什么?因为用户的钱在你那里,再大的 bug 的,用户的也得忍受,而工具类产品不一样,比如新闻资讯类,有问题,换一个,很现实;
这也不代表用理财这类产品不需要管线上反馈,只是不需要做到那么细的地步,遇到线上问题,还是要处理的哦;

吧唧下线上跟进流程
谁没有过跟进线上问题的经历,下面就介绍下跟进线上问题的流程吧:
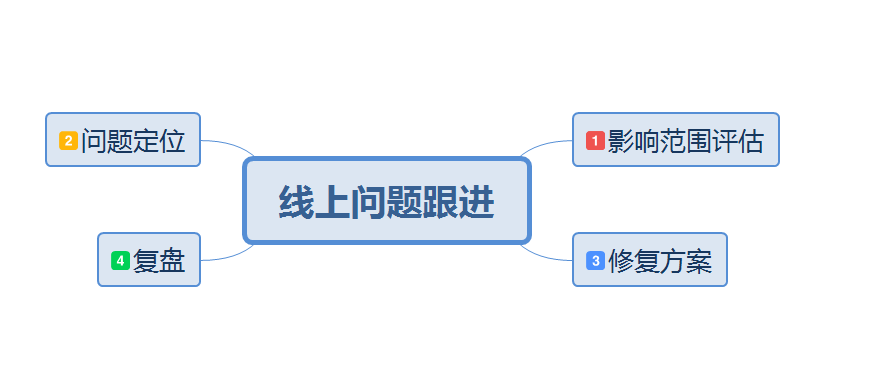
影响范围评估
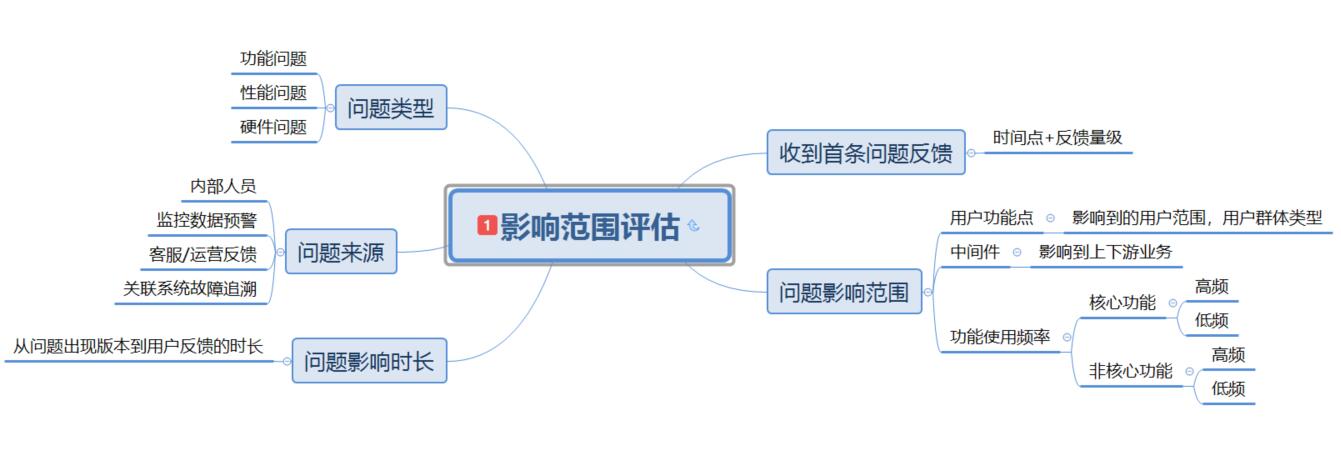
拿到问题,肯定是先要评估影响面,根据影响面的不同以及影响时间,采取不同的修复策略;
问题定位
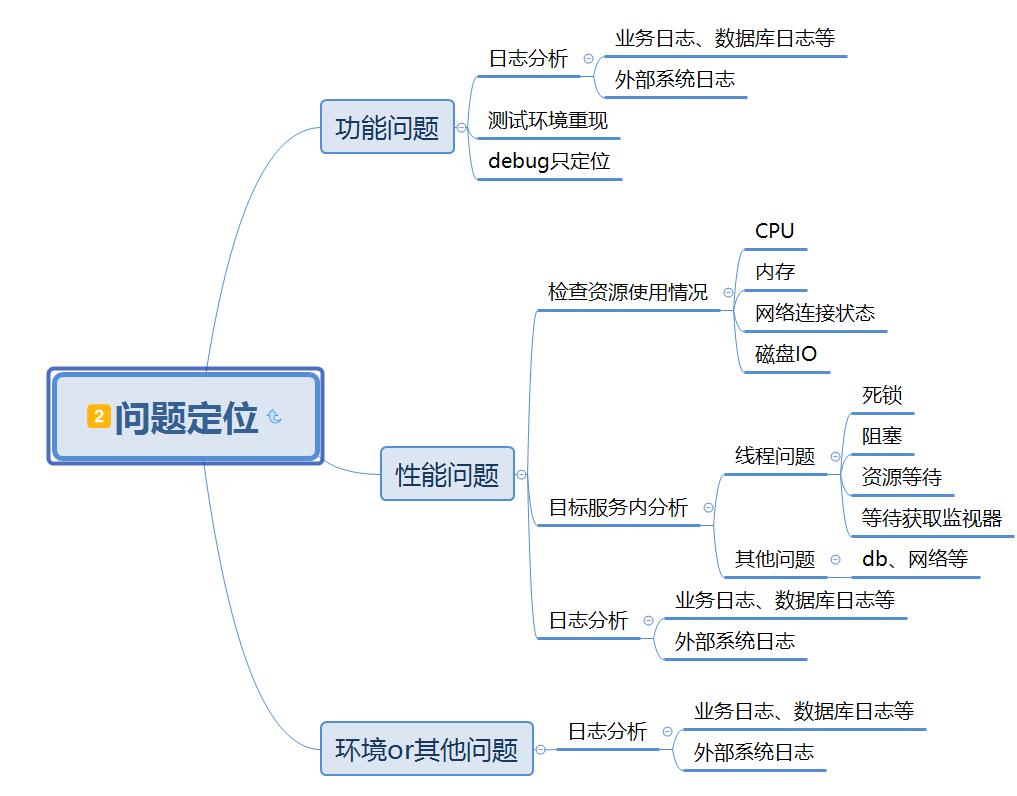
修复方案

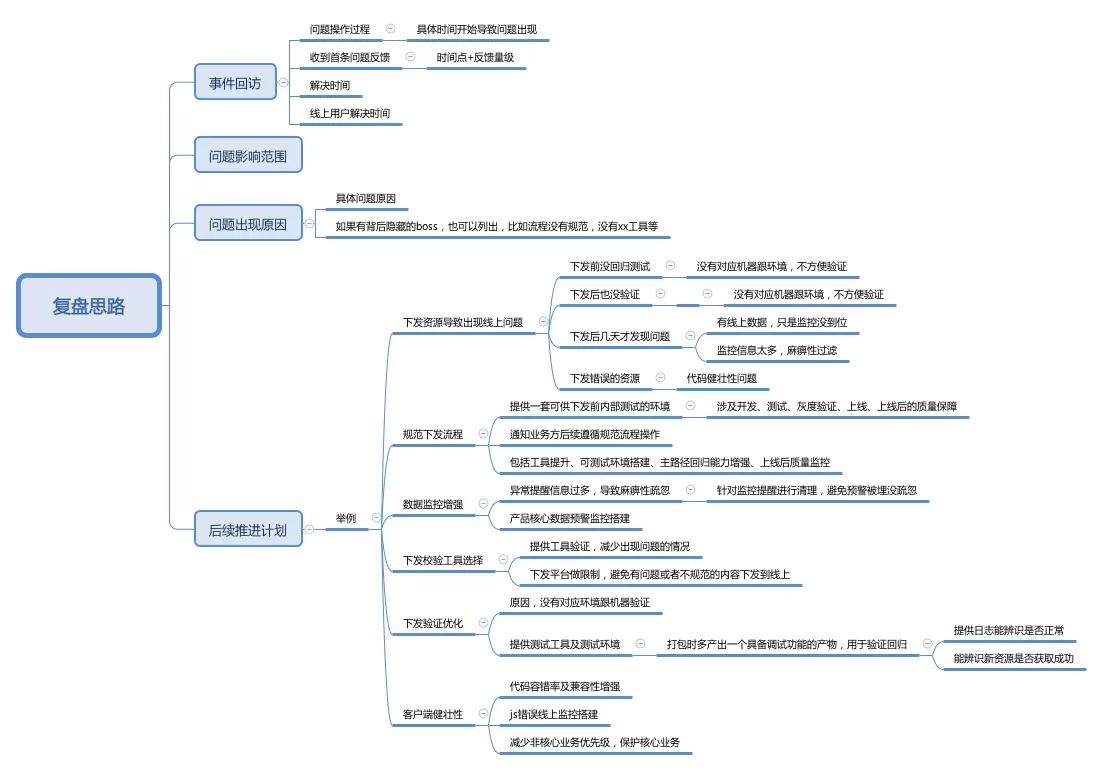
复盘
关于复盘,不想多说,可以来这看,之前写过一篇关于复盘的总结;
撒花
写了将近 1 天的时候,本来三指那块是重点,但是想着既然都要写了,就从一个大的角度去说说吧,对自己来说,算是巩固了这块的知识了,算一个知识回顾吧;
看到这里,感谢您的坚持,纯文字的文档,居然能坚持看到这里,兄弟,不容易吧;

小结
常规流程,来个小结;
- 线上质量要重视,很容易造成用户流失;
- 想做好质量管理,有两个环节:预防&测试分级;
- 预防是依赖流程、工具进行约束;
- 测试分级大致为:单元、接口、UI、性能、安全、自动化测试;
- 了解持续交付,包括部署流程,线上监控等;
而质量管理优化,有以下三步:
- 体系状况,分析梳理
- 质量流程,优化设计
- 质量规范,部署实施
剩下的,就是收集 log 的工作,大概思路如下:
- 客户端具备生成日志且储存日志功能;
- 客户端具备上传日志功能;
- 客户端具备关闭上传日志功能;
- 后台系统具备将上传日志进行问题排序且提供日志下载功能
接着就是安卓三指遇到的坑,总结下:
- 研发的概要设计文档流程还是需要的,别以为只是一句话需求就不做了;容易陷入想当然;
- event 容易出现兼容性问题,厂商有可能做了定制处理,这块要切记;
题外话
以前见识到手淘的黑科技,具体链接忘记的,大致流程如下:
- 用户遇到问题
- 程序上传日志
- 解析日志,转化成用户行为信息
- 通过视频回放的方式观察到用户的操作场景
这样,就可以把用户的操作一览无遗,高级玩家高级玩家;

最后,欢迎大家一起探讨,毕竟一个人的力量是有限的,jb 只是在无知的世界里漫游而已;
最后的最后,谢谢大家~