前言
由于公司产品的变化,我需要编写一些 TensorFlow 的代码来测试我们产品的深度学习模块。 最近也在学习 TensorFlow。 所以先暂停卷积神经网络部分的更新。开始写一些 tensorflow 的东西。 话说白话了这么久的理论~~ 终于可以跟大家上点代码了。 对于 tensorflow,下面我都简称 tf
环境搭建
这个我没细研究,直接 docker hub 上找到 TensorFlow 的镜像下载,然后启动。 或者大家也可以搭建一个集成了 TensorFlow 的 notebook
什么是 tensorflow
一个 2 分类单隐藏层的神经网络
先上代码。
import tensorflow as tf
x = tf.constant([[0.7,0.9]])
y_ = tf.constant([[1.0]])
w1 = tf.Variable(tf.random_normal([2,3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3,1], stddev=1, seed=1))
b1 = tf.Variable(tf.zeros([3]))
b2 = tf.Variable(tf.zeros([1]))
a = tf.nn.relu(tf.matmul(x,w1) + b1)
y = tf.matmul(a, w2) + b2
cost = tf.nn.sigmoid_cross_entropy_with_logits(logits=y, labels=y_, name=None)
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
for i in range(100):
sess.run(train_op)
print(sess.run(w1))
print(sess.run(w2))
这是模拟一个最简单的神经网络的代码。 只有一条样本两个特征维度 (只是拿来做 demo 的), 隐藏层使用 relu 作为激活函数。有 3 个神经元,整个神经网络的目的是做二分类,所以输出层的激活函数是 sigmoid,损失函数 (成本函数) 也是 sigmoid 的损失函数。 前向传播算法是使用矩阵乘法实现。 反向传播是用 tf 提供的标准的梯度下降,学习率为 0.01,训练轮数为 100. 没有加正则。 我们查看经过训练后隐藏层和输出层的权重信息如下:

为什么用 tensorflow
如果有同学用过类似 Keras 这种高度封装 API 的神经网络库的话,就会发现 tf 的代码简直太复杂太繁琐了。 上面只是最简单的神经网络,没加正则没用 mini batch 甚至样本只有一个,连实现前向传播都得自己写代码。 实际应用的话代码会更复杂很多。 但是使用 Keras 可能就是几行代码的事,学习难度小很多。 那我们为什么还要使用 tf 呢? 我知道的好处是 tf 灵活,支持分布式执行,比如 tf on k8s 现在很火。是现在做深度学习平台的不二选择。 据我所知现在各大厂的深度学习平台都是用 tf 弄出来的。 当然对于我来说,学习 tf 的目的只有一个,就是测试我们自己的深度学习平台。
tensorflow 基础概念
tensorflow = tensor + flow。 其中 tensor 是 tf 的数据结构,flow 代表着 tf 的计算框架 ---- 计算图
tensor,又名张量。在 tf 中所有的数据都是以张量的形式表现的。从功能上来看,张量是一个多维数组。比如在我们上面的 demo 中,我们用来模拟样本数据的 x 和对应的 label y_都是 tensor。但 tensor 在 tf 里的实现并不是直接采用数组的或其他任何已知的数据结构。 如果说类似的话,tensor 的机制有点像 spark 中 RDD 的惰性计算, 在 spark 中我们的计算流是惰性的,在代码执行每一个 transform 的时候并不会真正的执行,而是把计算过程记录下来,等到执行到 action 的时候才会真正的执行。 这是惰性计算。 tensor 以及 tensor 的计算表现也类似。 当我们执行以下代码时,并不会得到真正的结果,而是会得到一个结果的引用。

我们在 tf 声明了两个常量, a 和 b。 他们是 tf 中的 tensor(张量)。 当我们执行了一个加法操作的时候,打印出的结果并不是他们的计算结果。 而是一个 tensor 的结果。其中打印的第一个字段:add_35:0 表示这个节点 add_35, 0 是说 c 这个张量是节点add_35的第一个输出。 打印的第二个字段是 shape,也就是维度。 说明这个 tensor 是几乘几的矩阵。 我们的例子中是 shape=(1,2) 表明这是一个 1*2 的矩阵。 第三个字段是 tensor 的类型,我们这里是 float32 类型。
如果用画图的方式表示出来,大概就是下面这样的
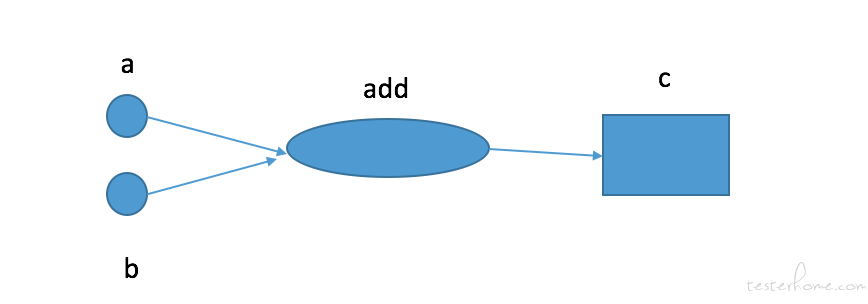
上图中的每一个节点都是一个运算,而每一条边代表了计算之间的依赖关系,一个运算的输入依赖于另一个运算的输出。 这就是 tf 的计算图,也就是 tensorflow 中 flow 代表的意思。 在 tf 遇到真正需要执行的那段代码之前, 所有的计算都不会触发,取而代之的是 tf 在内部维护一个计算图。 在遇到需要执行的时候, 按照计算图依次进行计算。
计算图的执行节点 -- 会话
刚才我们讲了 tf 是如何组织数据和计算图的。 它不会真正的执行,而是等待某个时机的到来,按照计算图依次进行计算。 那么这个时机就是会话。 如下:

可以看到上图中我们使用 python 的 with as 大法管理 tf 的会话声明周期。 在里面我们并没有去管 a 和 b,相反我们只用了一行代码 print(session.run(c)) 就打印出了计算结果。 正如我之前所说,tf 会维护一个计算图。 当我们真正的去计算 c 的时候。它会按照计算图从头计算一遍。
结尾
今天就写这么多吧。 快半夜 11 点了。。。。
