会员
shangguanyi (上官一)
第 95287 位Users / 2024-10-17
8 篇帖子 • 49 条回帖
-
13 个赞 / 23 条回复
-
2 个赞 / 3 条回复
-
0 个赞 / 3 条回复
-
0 个赞 / 3 条回复
-
AI 时代,测试的护城河到底是什么? at March 30, 2026
哪个 AI 社区呀
-
Appium Inspector 定位到元素是没有 text 属性的,是不是就获取不到他的文本了? at December 18, 2025
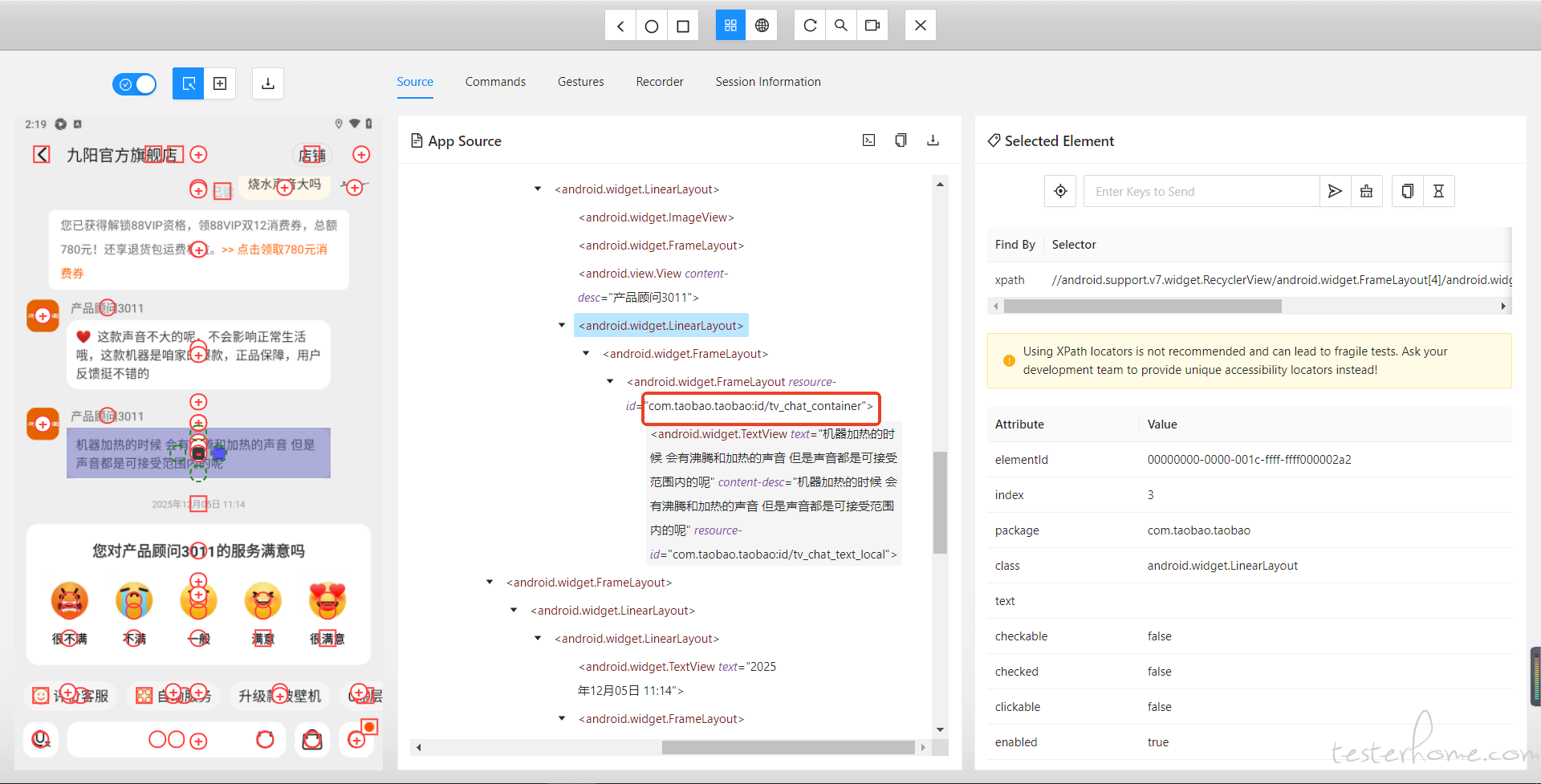
定位的不对 你可以看看我这个 -
来点高级货:手搓自动化验证码登录注册自动化测试 at October 29, 2025
这不巧了吗,我最近刚写了一个获取邮件信息的方法,再用正则表达式或者其他方式提取一下验证码
from imapclient import IMAPClient import email from email.header import decode_header from email.utils import parseaddr def get_email(sender_email=None, folder="INBOX", subject_keyword=None, only_unread=False, mark_as_read=False, limit=None): """ 使用 IMAPClient 获取邮件,并设置 IMAP ID 信息 """ IMAP_SERVER = "XXXX" EMAIL_ACCOUNT = "XXXX" PASSWORD = "XXXX" result = [] with IMAPClient(IMAP_SERVER, ssl=True) as server: # 登录 server.login(EMAIL_ACCOUNT, PASSWORD) # 设置 IMAP ID 信息 server.id_({ "name": "myname", "version": "1.0.0", "vendor": "myclient", "support-email": "testmail@test.com" }) # 列出文件夹(调试用) folders = server.list_folders() print("所有文件夹:") for i in folders: print(i) # 选择目标文件夹 try: server.select_folder(folder) except Exception as e: print(f"无法打开文件夹: {folder}\n{e}") return [] # 搜索条件 criteria = [] if only_unread: criteria.append("UNSEEN") else: criteria.append("ALL") if sender_email: criteria.append(f'FROM "{sender_email}"') # 搜索邮件 messages = server.search(criteria) if not messages: print("没有找到符合条件的邮件") return [] print(f"找到 {len(messages)} 封符合条件的邮件") count = 0 for msgid, data in server.fetch(messages, ["RFC822"]).items(): msg = email.message_from_bytes(data[b"RFC822"]) # 解码主题 subject, encoding = decode_header(msg["Subject"])[0] if isinstance(subject, bytes): subject = subject.decode(encoding or "utf-8", errors="ignore") if subject_keyword and subject_keyword not in subject: continue # 解码发件人 raw_from = msg.get("From") name, addr = parseaddr(raw_from) decoded_name = decode_header(name)[0][0] if isinstance(decoded_name, bytes): decoded_name = decoded_name.decode("utf-8", errors="ignore") from_ = f"{decoded_name} <{addr}>" # 提取正文 body = "" if msg.is_multipart(): for part in msg.walk(): content_type = part.get_content_type() content_disposition = str(part.get("Content-Disposition")) if content_type == "text/plain" and "attachment" not in content_disposition: charset = part.get_content_charset() or "utf-8" try: body = part.get_payload(decode=True).decode(charset, errors="ignore") except Exception: body = "" break else: charset = msg.get_content_charset() or "utf-8" body = msg.get_payload(decode=True).decode(charset, errors="ignore") result.append({ "subject": subject, "from": from_, "body": body }) # 标记为已读 if mark_as_read: server.set_flags(msgid, ["\\Seen"]) count += 1 if limit and count >= limit: break return result # 测试:读取未读邮件 if __name__ == "__main__": emails = get_email(folder="INBOX", only_unread=True, mark_as_read=True limit=1) print("结果:", emails) -
Agentic X:LLM Agent 在测试领域的探索与思考 at September 26, 2025
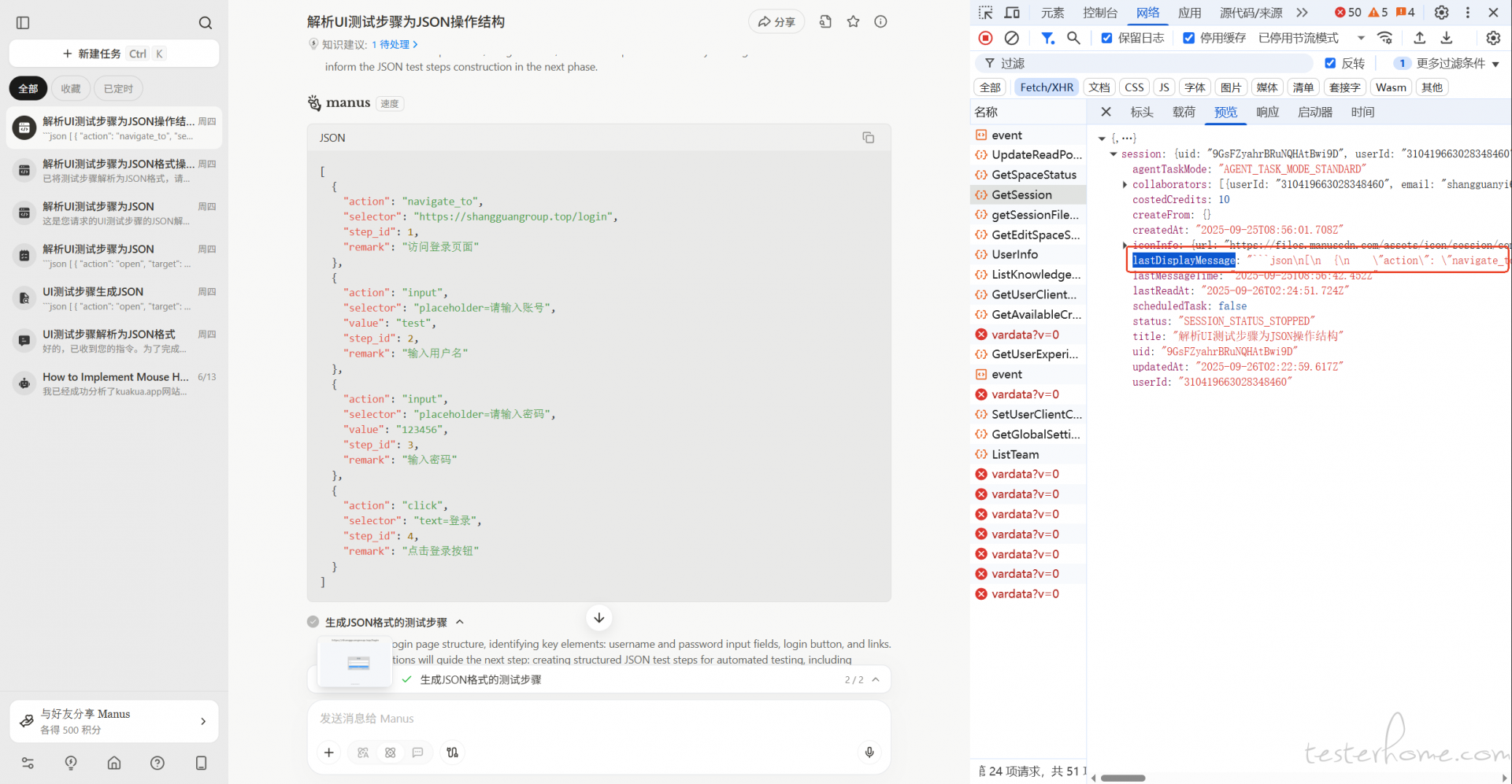
我发现一个更省事的方法,直接调用 manus api (他支持直接打开浏览器),让他把测试步骤解析成 json 结构,接口虽然不会返回任务的详细结果,但会返回 task_id,等任务执行完成直接请求
https://api.manus.im/session.v1.SessionService/GetSession 接口,
lastDisplayMessage 字段就是最后返回的结果,可以直接拿去用,缺点就是仅支持 WEB 端且价格有点贵
官网:https://manus.im/app
api 文档:https://open.manus.ai/docs/api-reference/create-task
-
Agentic X:LLM Agent 在测试领域的探索与思考 at September 24, 2025
多模态能力的 ui 测试平台是不是要把前端的页面结构传给 AI 呀,如果一条用例涉及多个页面,需要把多个页面结构一起传给 AI
-
测试工程师 -支持远程 at September 22, 2025
+1
-
UI 自动化平台中的用例管理 at September 09, 2025
平台支持手机端 app UI 自动化测试吗,如果支持,是如何实现的呢
-
告别 JavaScript 困扰!IterfaceTestPlatform 让 30 万 Python 测试工程师轻松拥抱接口自动化 at August 15, 2025
接口都 404 了
-
自动化测试 - 测试平台的结构化断言如何实现加减乘除的计算 at August 05, 2025
如果后端使用的是 python,可以使用 eval 函数,其他语言应该也有相应的函数可以实现。
可以在断言类型里加一个 eval,先算出来 a+b 的结果,最后再断言相等a = 1.555 b = 2.456 c = 4.01 result = eval("round(a + b, 2)") # 四舍五入保留两位小数 -
关于 UI 自动化方案 at August 04, 2025