-
協助團隊導入自動化測試之心路歷程_首篇 at 2018年01月19日
不建议一上来就把落地自动化规划的很大,可以先从局部的手工专项自动化实施落地,最后攒在一起就可以了。
jenkins 更多的是配置脚本和执行脚本的管理,其实 jenkins 很大的优势就是对不同脚本语言的包容,无论什么语言的脚本,只要执行配置归于 shell、批处理,就可以部署在 jenkins 上执行。并不是所有功能实现都局限在 jenkins 插件去实现,需要统一的是结果报告数据的格式和数据表定义,方便将测试报告统一规划设计。
至于数据可视化部分也没多难,简单落地就是测试结果按 csv 格式存储,python 用 pandas 库做数据处理,highcharts 可以做可交互的各种图。
具体实施来说:
1、测试开发实现手工测试团队自动化需求(任何脚本本语言,能实现即可),并向 jenkins 提供执行配置脚本,其中包括结果处理输出的脚本,邮件脚本(可 python 实现)
2、组织人手设计统一的测试结果存储和展示平台,第一步可各自建立 job 各自邮件通知测试结果,在平台搭建好后在发邮件前做数据上传到展示平台的工作。我们现在就是在落地结果统一收集展示平台搭建这块,各专项能自动化的都做了自动化方案的设计实施。
自动化实施最主要的就是老板的态度,得向老板充分展示出自动化带来的人力节省和部门成本预算上的节省。拉个有活力的新的测试开发团队推进,同时扩展测试覆盖范围给节省的人力提供更多的业务需求。
-
利用 dumpsys 输出当前这个手机的某个应用动画帧的状态,某些应用输出值为空 at 2018年01月17日
你需要搞清楚帧数据来源和原理,gfxinfo 的数据都是 UI 主进程绘制的数据,SurfaceView 的绘制帧数据是不包含在内的。还有一点是如果 app 使用了系统动效,系统动效这部分数据也不包含在内。
1、dumpsys gfxinfo 包名 framestats 命令只能获取除了 SurfaceView 和系统动效的帧数据;
2、获取 SurfaceView 和系统动效需要用到 dumpsys SurfaceFlinger --latency 包名;不加包名即是系统动效的帧数据 -
关于用 adb 命令统计手机所有 app 流量的优化 at 2017年12月22日
你搞反了,0x0 是总流量 tag、其他的 tag 是线程流量。不是去掉 0x0 而是只统计这个 tag。如果想了解详情才分别去看是哪些线程使用了流量。
-
shell 管理 monkey 压力测试续——监控方案重构及 MCM 监控维护 at 2017年12月21日
新的内部使用没分享呢,具体的 case 也只是适配的内部项目,再有就是没在管手机业务的基础体验测试后,手机的脚本一直也没维护,主要维护的 TV 的。外部分享得改不少内容,犯懒有时间没写分享了。
-
shell 管理 monkey 压力测试续——监控方案重构及 MCM 监控维护 at 2017年12月21日
内部有维护,现在是按 case 分组自动统计的方式进行测试,CI 部署测试,整体逻辑上有调整,就是还没整理分享。
统计页
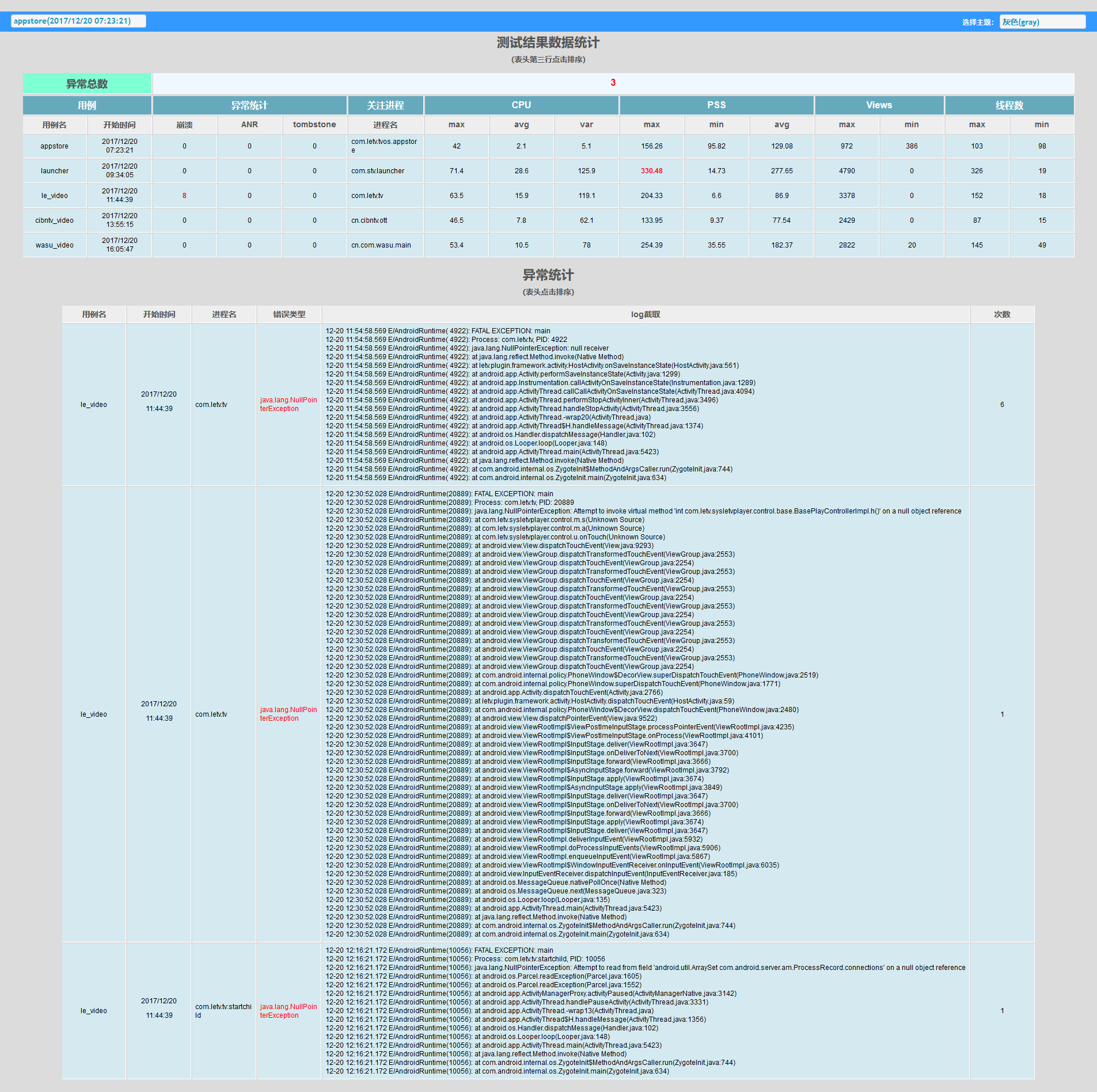
单 case 监控数据
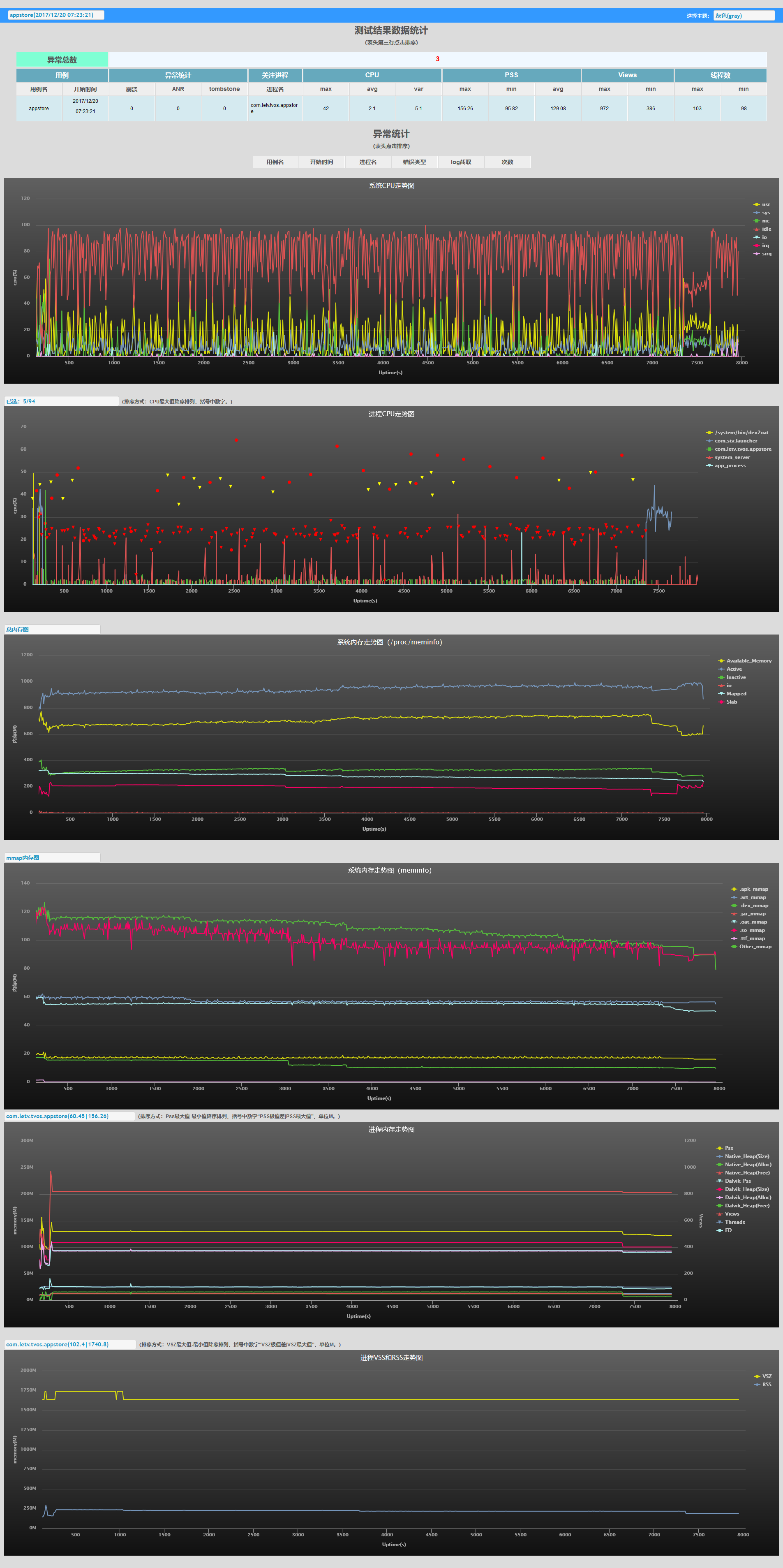
-
shell 脚本通过 dumpsys SurfaceFlinger --latency 数据计算 FPS 和评价流畅度。 at 2017年12月08日
这个时间就是为了对应下 log 时间点加的算了下结束帧对应时间,之前脚本没加时区的 8 小时,后来优化了逻辑和算法,见正文。
-
请问有什么好的办法能够快速耗电,让手机电量耗完? at 2017年12月01日
那就是手机的温控没做好,我们之前这么放电没问题,温控有优化。费电的就是摄像头,补光灯,屏幕,马达。可以用耗电 app,打开补光灯(手电筒),常亮屏幕震动
-
穷团队测试耗电量出路 at 2017年12月01日
主要是解决大部分功耗 case 的自动化:PowerMonitor 自身控制脚本 + 手机端 case 后台操作脚本(uiautomator、shell)+ 数据线加继电器改造(继电器控制通断脚本)+ 报告统计脚本。
主要执行步骤:
1、初始化 PowerMonitor 电源参数(由外部变量状态控制监控数据的存储,最初用的环境变量后改成了文件便于多设备并发,监控文件已 csv 保存),初始化手机的必要设置及环境状态
2、调度用的主脚本用于执行用例后断开数据线的继电器,之后修改文件内变量(通知 PowerMonitor 开始保存监控数据到 case 结果文件夹)
3、等待用例操作结束 (预调试好的等待时间),通知 PowerMonitor 停止记录并恢复数据线连接及获取 case 执行结果和 log 到 case 结果文件夹
4、回到第二步按照配置的 loop 和 case list 完成测试
5、此时的测试结果是分 case 文件夹保存的,包括 PowerMonitor 监控结果、case 执行结果和 log;通过报告脚本统计分析生成报告。(传入可配置的 goal 值 csv 文件用于统计)当时试跑报告形式如下,可选 case 及 loop 数查看该次的 PowerMonitor 电流数据图
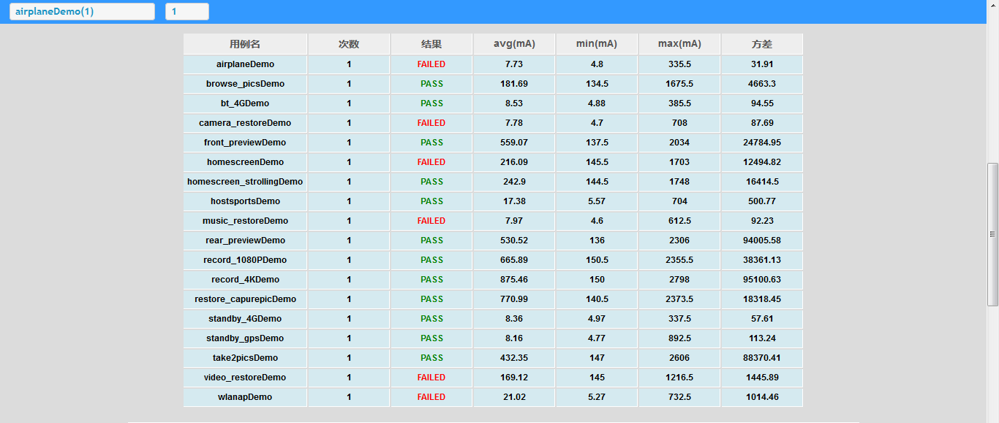
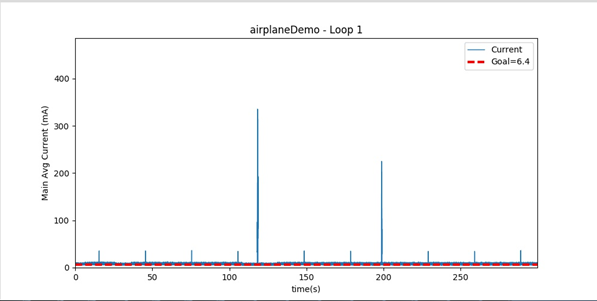
-
请问有什么好的办法能够快速耗电,让手机电量耗完? at 2017年11月30日
异常的快速耗电损坏电池,影响电池使用寿命。正常高耗电场景循环操作吧,最典型的就是开补光灯的 4K 模式录像/拍照
-
关于用 adb 命令统计手机所有 app 流量的优化 at 2017年11月17日
再有就是 python 一样,建议注意下文本流处理的意识,逐行过一遍文本信息直接通过逻辑处理拿到最终结果。awk 就是这个思路,逐行处理中已完成逻辑判定和处理。
-
关于用 adb 命令统计手机所有 app 流量的优化 at 2017年11月17日
你试下这几行命令就清楚了,再有就是取数据能一次获取的不要循环抓,dumpsys package packages 可一次性拿到所有 app 的 uid,就是文本得后处理下
-
穷团队测试耗电量出路 at 2017年11月15日
其实最主要是研发认可测试结果,研发提出需要至少 PowerMonitor 的测试结果,做硬件及 rom 不同于 app,硬件数据上有精度和底线需求。
-
穷团队测试耗电量出路 at 2017年11月15日
一般肯花钱的上的是安捷伦,省钱怎么也得上 PowerMonitor。年初兼顾手机基础体验测试时,下面的功耗续航组主要就是用的 PowerMonitor(都是美国代购回来的),当时还带着做了 PowerMonitor 的自动化测试方案。
-
关于用 adb 命令统计手机所有 app 流量的优化 at 2017年11月15日
善用 busybox 的文本流处理工具,如 awk,取/proc/net/xt_qtaguid/stats 并格式化输出耗时 20ms;取所有 app 的 uid 耗时 200ms
步骤一,busbox 官网下个安卓设备对应的 busybox
步骤二、push 到/data/local/tmp 下并付权限 755
adb push busbox /data/local/tmp
adb shell chmod 755 /data/local/tmp/busybox
步骤三、adb shell 下获取
adb shell
bb=/data/local/tmp/busybox
获取所有 app uid 以下命令是一行
dumpsys package packages|$bb grep -E "Package |userId"|$bb awk -v OFS="," '{if($1=="Package"){P=substr($2,2,length($2)-2)}else{if(substr($1,1,6)=="userId") print P,substr($1,8,length($1)-7)}}'
获取流量
$bb awk -v OFS=, 'NR>1{if($2=="wlan0"){wr[$4]+=$6;wt[$4]+=$8}else{if($2=="rmnet0"){rr[$4]+=$6;rt[$4]+=$8}}}END{for(i in wr){print i,wr[i],wt[i],"wifi"};for(i in rr){print i,rr[i],rt[i],"data"}}' /proc/net/xt_qtaguid/statsps: 结果格式化为 csv 格式,可按需自己修改;awk 中也可以对统计数据直接做浮点运算转换流量单位。
-
shell 脚本通过 dumpsys SurfaceFlinger --latency 数据计算 FPS 和评价流畅度。 at 2017年09月15日
配 surface 名主要是按需定制,毕竟不同测试场景需要监控的 surface 不同,不一定就是一个 activity。可能是 surfaceView,甚至是特定弹窗的 activity,主要为了匹配特定测试需求。其实做整体监控也可以全部抓数据后处理,这样就不用配参了,我另一个监控应用场景是动态取的数据,把当前所有 surface 帧率数据做保存,就是后续出图麻烦了些。
-
瞬时数据已 top 为准,cpuinfo 被平均的时段长,而且受其他命令影响大,尤其是 dumpsys meminfo。建议用 busybox top -b -n 1,单次抓取,比系统带的快,计算精度高一位。
-
关于 APP 页面加载时间的测试工具或者测试方法,有什么推荐或介绍的 at 2017年07月31日
这里所说的方法主要是针对直观用户体验维度,如果单纯是分阶段测试优化,抓包 + 绘制效率测试就够了。就是过渡绘制,页面内容和图片资源大小控制维度,做绘制效率优化。
-
关于 APP 页面加载时间的测试工具或者测试方法,有什么推荐或介绍的 at 2017年07月31日
不需要动开发代码,就是操作命令 + 显示过程动静状态判定。
比如一个点击后跳转页面,安卓使用 input/uiautomator 等框架的操作方法实现点击跳转,使用 surfaceflinger 历史帧数据取得最后显示静止一帧的 vsync 时间戳(操作前取/proc/timer_list 第三行的纳秒时间)两个时间的差值就是,也可以设定两帧间隔大小作为排定结束点的依据。当然纯外部的还有高大上的机械臂手段。
-
如何从业务测试过度到测试开发 at 2017年07月31日
我转测试开发就两点自我认知:
1、不拼编程语言掌握程度,重点关注需求逻辑组织变现,把逻辑思路想透并尽可能的简化和优化代码处理中的开销。
方案初版实现-》掌握更优的思路和开源框架就引入后重构,经过这种台阶式的重构提高把自己实现的方案不断优化,从而培养出自己解决自动化需求的方案套路。
注:这里重要的一点就是要做强需求的实现,且需要长期被使用。这样才有动力持续维护,我 13 年的 TV ota 压测脚本方案迭代维护用到现在;14 年初的 cpu 内存监控方案经过思路重构,新需求点引入,也维护使用到现在并集成到多个专项中。方案的思路的持续思考和升级能不断训练自己快速构建完整逻辑的能力,期间会形成自己的风格特点。2、拼自己独立实现的方案成果,且推广到所在业务团队得到认可
这里就是积累自己特色的实用解决方案,而不是人云亦云的跟随,开源方案落地到业务都是需要个性化定制的,需要有自己个性化定制的套路,或完全自己实现该框架思路的实现形式。 -
关于 APP 页面加载时间的测试工具或者测试方法,有什么推荐或介绍的 at 2017年07月31日
如果 app 加载的是静态页面,取下开始跳转到画面静止时间点的时间差值,可以写客户端脚本测试完整过程,抓包只是隔离抓了了网络部分没算加载显示部分。
-
如何从业务测试过度到测试开发 at 2017年07月31日
我认为业务测试过度到测试开发主要优势两点:
1、了解业务测试环节痛点,在做脚本和工具开发时应主动向高效解决这些痛点的自动化方案入手。
2、积累下来的业务 bug 风险点,开发中提前对已知风险点进行甄别、分析、统计归类。实实在在拿如何解决自己经历过的痛点练手,实现方案应用现有业务落地。多积累些解决问题的思路方案,之后就看能接多大的测试自动化脚本方案或工具设计业务需求能力了。
我是从客户端功能测试转测试开发,从功能测试到带执行组,之后转脚本方案设计,再之后安卓端性能测试相关方案建设,以此为基础扩展到带安卓项目基础体验团队。有一点明显的体会:不断用自动化方案解决自己过去遇到痛点,实际试用推广到所在团队,自然而然内部转岗后就成了测试开发了。这期间前期主要是用自己经历过的痛点练手自动化思路设计,学到更好用的思路就打破重构,有过成功方案思路落地,之后就可以接需求做更多事了。
遇到很多问我学自动化要看什么编程语言,甚至是有些人去报班培训,结果会用了还是维护别人自动化方案的自动化用例维护人员。。。要去换位想想业务上有哪些自动化需求,自己能独立解决多少。
-
android 端取 cpu,fps,men,wifi/gprs 流量等值 at 2017年07月28日
按目标需求逻辑捋顺流程,awk 这部分我是为了不再另写文件,写为了一行命令,这部分另存后在分号后换行看,大体语法和 c 的相似,只是需要了解下 awk 的公共变量。
-
android 端取 cpu,fps,men,wifi/gprs 流量等值 at 2017年07月28日
(https://testerhome.com/topics/4775)
(https://testerhome.com/topics/3685)
(https://testerhome.com/topics/2976)
早期的分享,当然到现在我这自己内部用的已经有迭代变化。不过思路上和关键函数变化不大,只是做些优化,更多的还是在方案组合使用衍生更多应用场景上的扩展。 -
android 端取 cpu,fps,men,wifi/gprs 流量等值 at 2017年07月28日
说下当年我趟过的坑:
1、最直接的抓取性能数据一轮的执行效率问题和占用设备问题
(1)设备端后台 shell 脚本作为监控脚本,即避免了 adb 通讯效率及异常风险又不用额外长连接 pc
(2)dumpsy meminfo 取进程内存时额外 cpu 开销大,会导致 dumpsys cpu 不准;系统自带 top 命令单次获取数据时间长且精度不够,最后用的 busybox 所带的 top 解决(在获取内存数据前先取 cpu)
(3)抓取所有进程 pss 耗时问题,最后是直接取 dumpsys meminfo 把其统计好的数据通过文本处理规则全部格式化为 csv
(4)处理各个命令获取数据结果的截取和格式化为 csv 保存的效率问题——利用 grep,sed,awk 文本流处理的形式提高处理效率,详细的截取、计算、统计规则使用 awk 语法搞定2、关于抓取数据的种类和必要性
(1)系统内存/proc/meminfo——整体宏观判定总内存,额外重点关注下 anon(匿名内存)使用
(2)dumpsys meminfo 统计结果中也有总内存统计,在做单进程 pss 抓取时顺便处理
(3)全部进程抓取外,额外重点关注进程也有监控详细 heap 数据需求,在抓所有进程 pss 时排除所关注的进程 pss,在之后使用 dumpsys meminfo 进程 pid 再次单进程获取(取 heap 数据以外,目前额外关注了 view 数量,子进程数量,fd 数量,vsz 大小则在 ps 中获取),view 不回收持续增长是验收 app 测试时很常见的问题,fd 和 vsz 主要针对 32 位平台地址空间有限,持续分配会引起可用 3G 地址空间用尽
(4)fps 测试需求,由于我这边需要站在用户体验角度分析问题,而不是代码执行效率是否满足(换言之动效设计等设定的帧间隔时间等设计因素;硬件性能掉帧也得考虑)——自己设计的统计规则使用 dumpsys SurfaceFlinger --latency surface 名 计算帧率
(5)流量和电量只是单独专项需求另行设计脚本子进程抓取3、关于数据呈现如何利于快速分析
(1)指定时间段统计间隔(1 小时),计算峰值降序,内存额外计算 pss 极值差 (最大 - 最小) 降序排列,引导快速选择重点关注的进程
(2)highcharts 交互图做报告展示模板,PID 变化时刻标红点,同名进程标黄点4、关于监控脚本应用场景,毕竟监控配合 case 操作才是完整方案
(1)监控脚本子进程执行,可被用例执行脚本统一管理开始结束时刻及监控结果存储位置
(2)单项监控数据获取独立函数,可按需任意组合或集成到其他执行脚本环节中
(3)报告展示逻辑部分,可集成到其他展示报告中5、关于时间轴统一:
(1)/proc/timer_list NOW 所在行纳秒时间作为统一时间轴对比 getevent、vsync(fps 时间轴)
(2)/proc/uptime 开机已运行时间作为 cpu、内存、电量、流量、sim 卡信号强度等数据的时间轴
(3)date 命令获取的时间作为额外记录用于对应 log 时间点最近在做外部录像、uid 流量,显示占率,getevent 操作统一时间轴对比分析的方案。
-
关于移动性能测试参数以及标准的讨论 at 2017年07月18日
我的看法是按需而定,重点关注如何落地闭环。
1、如果是管理层需求,就需要偏重点用户场景用例的性能体验评价和版本维护中的持续监控
2、如果是为了实际落地改善,就得和研发配合好,根据研发团队实际优化能力推动,需要研发和产品参与测试范围制定评估测试所提控的性能测试用例,最终落地测试方案。
3、app 方主要是业务驱动,会赶运营窗口期,业务上线响应效率是第一位的。快速有效的监控数据评估方案及灰度上线策略应该逐步会变为主流,应运而生的就是上线验收性能测试方案流程及评估标准。