自动化工具 请教下自动化失败的用例会做失败统计的原因吗?
状态
目前自动化平台基本完善,属于堆自动化用例的过程中,在跑用例的时候,总会有因各种情况导致用例失败。
思考过程
失败用例很正常,如何正视这种失败,如何避免这种失败情况呢?
结果输出
因为现在用例不多,失败也分很多种情况,那就不如先收集下失败的用例数据吧,做个整理归类。
在报告中,对于失败的用例进行选择性的收集,进行存储,在失败页面展示出来,在进行错误类型划分,备注上失败情况。
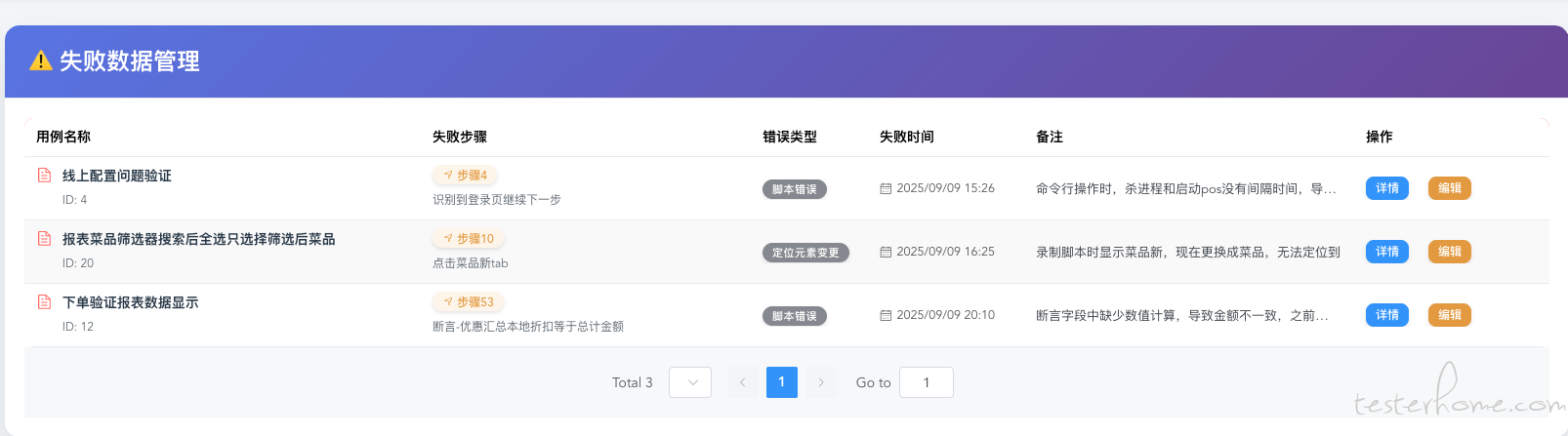
当前知道几个原因是什么造成:
1、写 case 的时候与真实的环境不同导致
2、断言数据时,对业务不熟悉,有些字段没数据忽略了
3、脚本执行时,过程中缺少等待时间,不确定性因素
效果
1、要说这样有用吗?会不会太麻烦了?
现在用例特别少,有一些作用,通过这里可以清晰的认识到失败的原因和改进的过程。但我不清楚用例量上来后,是否会有不一样的效果。