-
关于在本机监控流量,和使用 Jmeter 中监控的网络流量不符的问题 at March 15, 2021
最后一个是 agent 所在的整个机器的网络接收量,你前两个都是仅 java 进程的网络 IO 接收量。
确定除了 jmeter,没有其他接收量比较大的程序在同时跑吗?
-
appium ios 有办法清除用户数据,恢复初始状态么? at March 15, 2021
iOS 的沙箱安全机制,应该没有暴露可以清除应用内所有数据的入口,除非应用自己做这个功能。
-
面经手册《简历如何编写,作为一名职场人的建议》 at March 15, 2021
感觉好久没见到自己做排版的简历了,好多时候看到的都是直接招聘网站根据登记生成的简历,一般 2 页纸起步。。。
-
基于 STF 关于一机多控功能疑惑 at March 15, 2021
思路可以稍微转换一下,不一定是传递坐标点击事件来做一机多控,而是传递控件点击事件来做。这样问题 1 就可以解决掉了。
问题 3 的话,启动应用用命令启动(直接启动 activity )也可以解决。
推荐看看 solopi 一机多控。
-
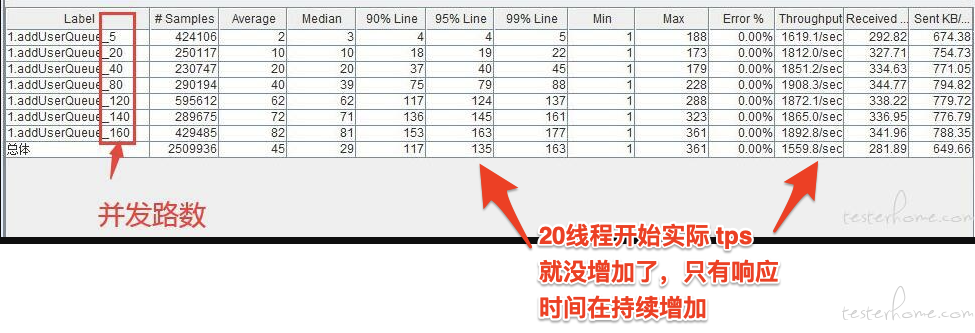
单接口压力测试时,增加线程数,却无法再提高 CPU 利用率 at March 15, 2021
不知道你后端是什么程序,如果是 Java 的话可以看 jvm 启动参数以及应用内的 properties 配置。
然后操作系统本身也有最大网络连接数这类配置的,可以百度看下,windows server 的我不大了解具体在哪里配置。
另外,从你这个图看,瓶颈应该不是资源消耗,有可能是应用内部机制引起的耗时,比如并发时等待锁释放之类的。推荐用 jconsole 抓取下整个 api 处理内部各函数的耗时情况以及看下会不会有锁之类的机制。
-
单接口压力测试时,增加线程数,却无法再提高 CPU 利用率 at March 13, 2021
有个问题,你是增加线程数后,提升不了 cpu 利用率,还是性能(TPS)也提升不了?
非 cpu 密集型的逻辑,cpu 提升不上去不是挺正常的么?
PS:建议也看看被测系统的环境配置,比如最大线程数、最大网络连接数之类的,是不是这些限制住了系统的发挥。
-
单元测试可以跑出覆盖率,接口业务测试能跑出代码覆盖率吗? at March 12, 2021
都可以。
具体方法可以在社区用 覆盖率 关键字搜索下。
-
不一样的测试之契约测试落地实践 at March 12, 2021
2 年前基于 Spring Cloud Contract 尝试过做契约测试,发现收效不大,当时出发点是尽早发现上下游契约不一致问题,但实际是有些细节还是得联调才能确认,光靠 mock 数据作用不大。
而基础的入参、出参、是否必填、值是否在可选值范围内之类的,开发把契约调用都封装成 rpc 调用后这类都不会有问题(强类型语言本身编译器就会强校验值类型这类信息)。代理和路由这个是个不错的扩展,可以在不侵入应用的情况下控制应用间通讯。期待后续楼主分享实际落地相关的经验。
-
同一个接口浏览器上和 jmeter 上看到的接口返回结果是不一样的是怎么回事?(返回是 HTML 页面) at March 12, 2021
把你网页的请求和 Jmeter 请求都发出来看看?包括 Url、http header 和 http body
两个结果不一样,大概率是你请求内容就不一样引起的。
-
开发改动的代码超出需求的范围怎么办? at March 11, 2021
先了解清楚开发多做改动的原因?
说的都是结果,没提及原因不好对症下药。开发也是人,一般不会无缘无故加代码的。
-
对于项目并行测试的看法 at March 11, 2021
同学,你跑题了。。。
PS:长期来说两门都需要,python 写脚本多一些,java 看开发逻辑和开发平台多一些。既然喜欢 java ,可以先深入 java ,后面有需要再了解下 python 。Java 熟练后上手 python 会快很多。
-
求一份比较完整软件测试方案,方案,方案,感谢! at March 11, 2021
建议去百度文库之类的地方找?
互联网公司基本都不会有这种超级完整的软件测试方案,写起来太花时间而且没啥用。
-
对于项目并行测试的看法 at March 11, 2021
这个不是可不可行的问题,是怎么让它变得更可行的问题。
效率会有一定影响(切换项目可能要花点时间回忆细节,也需要自己平衡好两个项目的时间占比),刚开始加班是避免不了的了。足够熟练之后相对会好一些。一般这种并行,都是一大一小的,一个大的花 60% 以上时间,一个小的 40% 左右时间。
-
【广州】荔枝招聘业务测试工程师 3 位,测试开发工程师(业务方向)3 位,测试开发工程师(音频专项)1 位 at March 09, 2021
回个帖支持下,欢迎大家一起来荔枝。里面技术氛围很不错的。
-
。。。 at March 08, 2021
-
当我看到我两年前写的开源代码... at March 08, 2021
好事,说明现在的你比以前的你强了。
-
每天一点面试题(2021/3/6) at March 06, 2021
我们一般在评定等级的时候就会一并考虑,低概率显示但一旦出现就很严重的,等级上会适当减轻。
可能还是不同公司节奏和分工不一样吧。我们基本不会有一个 leader 去决定每个缺陷的优先级,所以大部分都直接用的默认优先级。只有当缺陷真的比较多,不分优先级会修不完的时候,才会特别去强调一下优先解决哪几个 bug,大部分情况下这几个也是等级上最严重的。
-
测试人,是否你也有这样的迷茫 at March 06, 2021
如果一开始没沉淀,后面年限大了再进去确实比较困难。基本上大点的公司看得都是现在实力 + 未来潜质,两项都没有特别亮点的,会很容易被刷掉。
建议可以先结识一些人脉,有针对性地学习掌握所需技能,然后找人帮忙内推下。由于环境导致项目经验很难有亮点的,只能靠表现出来的潜力来吸引面试官了。
-
jmeter 接口请求间隔失败,postman 可以 at March 06, 2021
把你 jmeter 成功和失败两个请求的 request 和 response 完整贴上来?
光这个截图和这些文字只看到问题现象,没啥有助于定位问题的信息。
-
请教下微信小程序的接口测试要怎么整啊? at March 06, 2021
帮你设置好了。
鼠标移到回复右上角的赞,会多出来几个图标,其中一个打钩的就是设置为最佳回复了。
-
每天一点面试题(2021/3/6) at March 06, 2021
而 priority 分为五个等级:马上解决、急需解决、高度重视有时间要马上解决、一般重视有时间要马上解决、在系统发布前解决或确认可以不用解决
感觉道理是对的,但实际操作一般直接是严重性高的自然优先级高,两个放在一起反而容易导致不知道该先改哪个。
-
测试人,是否你也有这样的迷茫 at March 06, 2021
换个比较重视质量,且测试团队技术还不错的公司吧。
-
JsonSchema 这项技术还有用吗? at March 05, 2021
我觉得不是数据类型校验不重视,而是由于数据类型不一致引起问题的情况比较少,而且就算不用 jsonSchema 也很容易发现。
举个例子,某个字段表示当前用户数,定义是 number ,实际传了字符串。会出问题吗?不一定,服务端拆装箱会自动把字符串改为服务端应用里的数字类型。如果这个字符串无法转为 number ,服务端拆箱就会自动发现并且抛出异常,没啥特别去测试的必要。
至于返回值,前端也是类似的情况,类型错得离谱直接会影响业务逻辑立即被发现,错得不离谱其实也没关系。
-
造数工厂的一些疑问 at March 05, 2021
哪些业务最需要造数据,他们现在现状如何,要用上造数平台成本如何?
已经有脚本造数据的业务(一般也说明他们对造数据需求很大),目前用脚本造数据有什么痛点,上了造数平台可以解决其中哪些?可以想想这两个问题。个人理解关键点是这两个。
-
造数工厂的一些疑问 at March 05, 2021
能支持动态 java、python 脚本、jmeter 脚本的执行
部分业务线自己有自己的造数脚本等
快速变化的业务和平台自身稳定性之间存在矛盾
这三段话感觉有点矛盾。工厂支持脚本执行,业务本身也是有自己的造数脚本,为何业务要用的话会需要造数工厂跟着业务进行变化?
我们之前的经验是,先统一接口测试脚本框架,等到大家都熟悉后,再基于框架扩展 web 界面,达到直接通过 web 界面调用流程型用例造数据的能力。业务组接入只需要加点各个造数功能的定义就可以,成本不高,实现直接复用本身的接口脚本。
不过要推广到多业务线,要看其他业务线的需求如何,以及接入是否能给他们带来收益(我们这里接入得到的收益是前端开发、客户端开发、产品都能直接自助使用,不用再找测试去执行脚本,减少沟通协作成本。有这方面痛点的还是比较愿意接入的)。如果本身大家就有一些现成的东西,前期选型调研可能就要考虑到大家现成的内容,尽可能减少大部分业务的接入成本。