-
大厂测试开发面试题整理(二面,附答案) at August 02, 2021
这个问的好深,不准备很多真的答不上。。。
-
接口测试如何实现重复执行还能保持结果一致 at August 02, 2021
想确认下,你的 data.py 数据的更新,是在什么时候更新的?
听你意思,是在运行所有用例前?
如果是,时机改为是运行任意用例前,那是不是就可以做到不管是首次执行还是重试执行,都会使用新的数据了?
PS:我觉得你问题的核心,是先排查清楚用例不稳定的原因,针对性解决,而不是纠结怎么重跑?
-
简单监控应用日志 at August 01, 2021
挺实用的工具,点赞。
提个小建议,如果可能,建议上 ELK,在线查日志和预警都方便很多。
-
接口测试如何实现重复执行还能保持结果一致 at July 30, 2021
哈哈,没想到还有一样做法的。握个爪
我觉得偏门,主要是和自动化测试的一些原则违背了。大量的一次性数据,虽然不影响什么,但还是会有点不大舒服。
-
接口测试如何实现重复执行还能保持结果一致 at July 30, 2021
我们用的 java 的 testng ,重跑机制和你第二个比较接近。
没太明白你说的
重跑时的数据和第一次数据肯定是一样的是为啥?我们每个用例 setup 阶段就会创建新数据了,所以重跑用的数据不会和第一次一样的。 -
接口测试如何实现重复执行还能保持结果一致 at July 30, 2021
正统做法:
1、tearDown 里做好删除(调删除接口或直接删除数据库数据)。方便重复使用。
2、每次都重新初始化完整数据库内容,保证干净但我们是金融类系统,为了方便回溯,系统其实是没有任何硬删除的。软删除且添加时带有一些不能重复的 key,会导致二次添加直接失败。直接删数据也不容易删干净,各个系统间有比较多关联关系。
这种情况下我们的偏门解法:每次都用新数据。从用户注册开始,全部都是新的数据。
-
流量回放框架 jvm-sandbox-repeater 的实践 at July 30, 2021
这些插件是 jvm-sandbox-repeater 的插件,不需要另外启动。启动 repeater 并且提前做好配置就可以了。
-
记一次不该发生的 bug at July 29, 2021
金融系统的设计应该都需要考虑安全性的。后端做校验,做粗了就只是恒等式校验(比如你这个场景的 a-b=c ),没啥用。做细了基本就是再算一遍,确认和前端一样,这样又变成了重复劳动,维护成本增加。
所以大部分情况,都是前端不做计算,要计算就请求后端,后端返回计算结果。最多会做试算,但不会以此为准确值。
-
记一次不该发生的 bug at July 29, 2021
这里感觉有点问题。
vue 或者 react 这些现在流行的前端框架,基本都是带有数据双向绑定的特性,即界面的数据一更新,js 里面对应的值和基于这个值计算的所有值都会立即自动更新(有个 computed 计算属性,里面固定写 c=a-b ,那 a 或者 b 有变化,c 就会自动变)。
一般用这种框架,应该不需要监控失焦这类事件来触发值变化,除非是数据没有绑定到 js 里的 data 值,导致 vue 监控不到数据变化。
-
记一次不该发生的 bug at July 29, 2021
-
记一次不该发生的 bug at July 29, 2021
OK,理解。
其实只要这些计算由服务端做,会简单很多。前端交互基本都是各种相互关联事件流,组合方式多,容易遗漏。服务端基本就一个请求一个返回,会简单很多。
-
记一次不该发生的 bug at July 29, 2021
倒不是要你描述清楚技术层面的问题,但操作交互还是需要说清楚的。你这个答复还是没看懂,具体的操作步骤是什么,先点哪里,后操作哪里,这些操作效果的预期和实际有啥不同。
-
记一次不该发生的 bug at July 28, 2021
我也有想过这种可能,但这个交互设计好奇怪。。。就不给人家纯键盘操作了么。
-
记一次不该发生的 bug at July 28, 2021
涉及金额的,我们前端都只做试算,真正入账的金额都是在后端算。因为前端或者接口,都是很容易被伪造的。
PS:你的步骤里,
没有收到鼠标移动的操作,所以他没有做 a-b=c这个没太懂。鼠标移动操作这个没太看懂。 -
推荐一款国内首个开源全链路压测平台 at July 27, 2021
之前试用的时候,web 平台启动倒不复杂,但配套的 java agent 发现用不了,提示 class not found 。你有遇到不?
-
基于百度脑图的用例增量保存 + diff 展示整体设计 at July 26, 2021
嗯嗯,我们大部分团队也是一个人一个测试集,一般一个迭代 1-2 个测试。但有些团队一个迭代有 6 个测试以上,所以需要共用测试集。
-
自动测试为什么总是退出去呢?sleep 时间有关系吗 at July 25, 2021
[Appium] Closing session, cause was 'New Command Timeout of 60 seconds expired. Try customizing the timeout using the 'newCommandTimeout' desired capability'
这条日志你看一下?里面写得很清晰了。
-
IOS 环境已搭建完成,但是操作有些延迟,怎么改善操作流畅度? at July 24, 2021
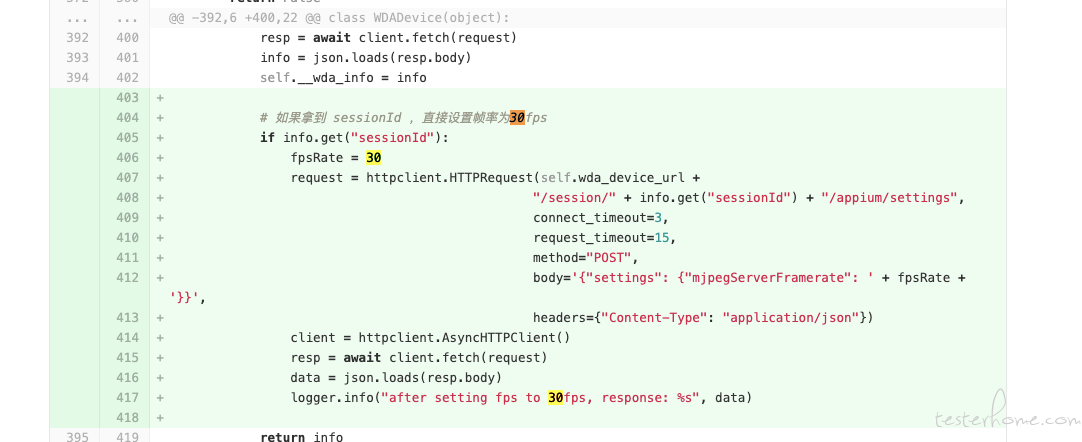
你用这个 url 看看,实际运行时 wda 的 fps 配置是多少?
http://<这里替换成你的 wda 地址>/session/<这里替换成你的 sessionId >/appium/settings接口返回值大概是类似下面这样:
{ "value" : { "screenshotOrientation" : "auto", "shouldUseCompactResponses" : true, "mjpegServerFramerate" : 30, "snapshotMaxDepth" : 50, "activeAppDetectionPoint" : "64.00,64.00", "acceptAlertButtonSelector" : "", "snapshotTimeout" : 15, "elementResponseAttributes" : "type,label", "keyboardPrediction" : 0, "screenshotQuality" : 1, "keyboardAutocorrection" : 0, "useFirstMatch" : false, "reduceMotion" : false, "defaultActiveApplication" : "auto", "mjpegScalingFactor" : 100, "mjpegServerScreenshotQuality" : 25, "dismissAlertButtonSelector" : "", "includeNonModalElements" : false }, "sessionId" : "1053FDC1-77AC-4674-A0BF-04C7C1605098" }上面这个值里的 mjpegServerFramerate 就是实际使用的最高帧率。
我目前的改法,是直接改 atx 源码,建立 session 后,发一个请求去修改帧率的,默认好像是 15。实践中修改为 30,感受上会比较流畅,大部分时间帧率会在 25-30 之间。改为 60,实际受限于 wda 性能,也到不了 60 的,反而可能因为帧率不稳定感觉卡卡的。具体改动的 diff 截图发你参考下
-
基于 cypress 的 UI 自动化实践入门 at July 24, 2021
对于运行速度这个,感觉 selenium 也不慢。有相同操作下两者运行速度差异的对比数据吗?
-
劝诫篇:切勿喜新厌旧,人云亦云,在长板到达一定程度后再去发展短板! at July 24, 2021
我觉得学一下倒无妨,留个印象,有时候广度就是这么来的,随性舒服,比如看到一个技术点感兴趣,就会花点时间去找下相关的材料,了解清楚背后大致的原理什么的。只是我一般会限制自己学习时间,比如设置个 20 分钟倒计时,到点就停响起闹钟停止探究,避免耽误正事。
真正要深入的技能,还是建议在工作中去试用,并尽可能争取到资源去落地应用,这样才能深入。毕竟工作时间有 8 小时以上,投入时间足够多,而且一旦立项也会有各种监督保障你不会半途而废,这样会比自己一直只是自学要来的高效靠谱。
-
为什么开发人员都不愿意写接口文档? at July 24, 2021
会不会遇到后端改了自己代码,但没改文档里面的参数,导致文档落后于代码?这个实践中是通过什么方法来保障同步呢?
个人之前用的大多是类似 swagger 这类从代码生成文档的工具,这样一致性保障可以程序全自动完成,避免人为疏忽遗漏。也想交流了解下看这类通过文档生成代码的,在这个方面具体是怎么保障的。
-
为什么开发人员都不愿意写接口文档? at July 23, 2021
好奇问一个点,这里面提到的最佳实践里,好像没提到 "你这接口参数怎么又变了?" 的解决方案?这个应该是前后端并行开发最容易遇到的问题了。
-
现在培训班出来的测试找工作薪资真有介绍的那么高? at July 22, 2021
这个是幸存者偏差吧。
一个培训班几十人,几期下来几百人,出来几个薪资比较高甚至进到大厂翻几番的,很正常。你公司测试团队有类似规模,离职的人里有一些学习比较积极,成长比较快的,出几个高薪的例子也是很正常的。
-
【活动】MTSC 2021 深圳站议题征集 at July 22, 2021
西安暂时没计划。
-
有幸参与大会志愿者活动,纪念一下。 at July 22, 2021
感谢志愿者们的在幕后的辛苦工作,大会圆满结束离不开各位志愿者的支持!
PS:志愿者的志字,文中有好几处错误,有空修正下吧。