资源 1c 2g uvicorn,docker 部署
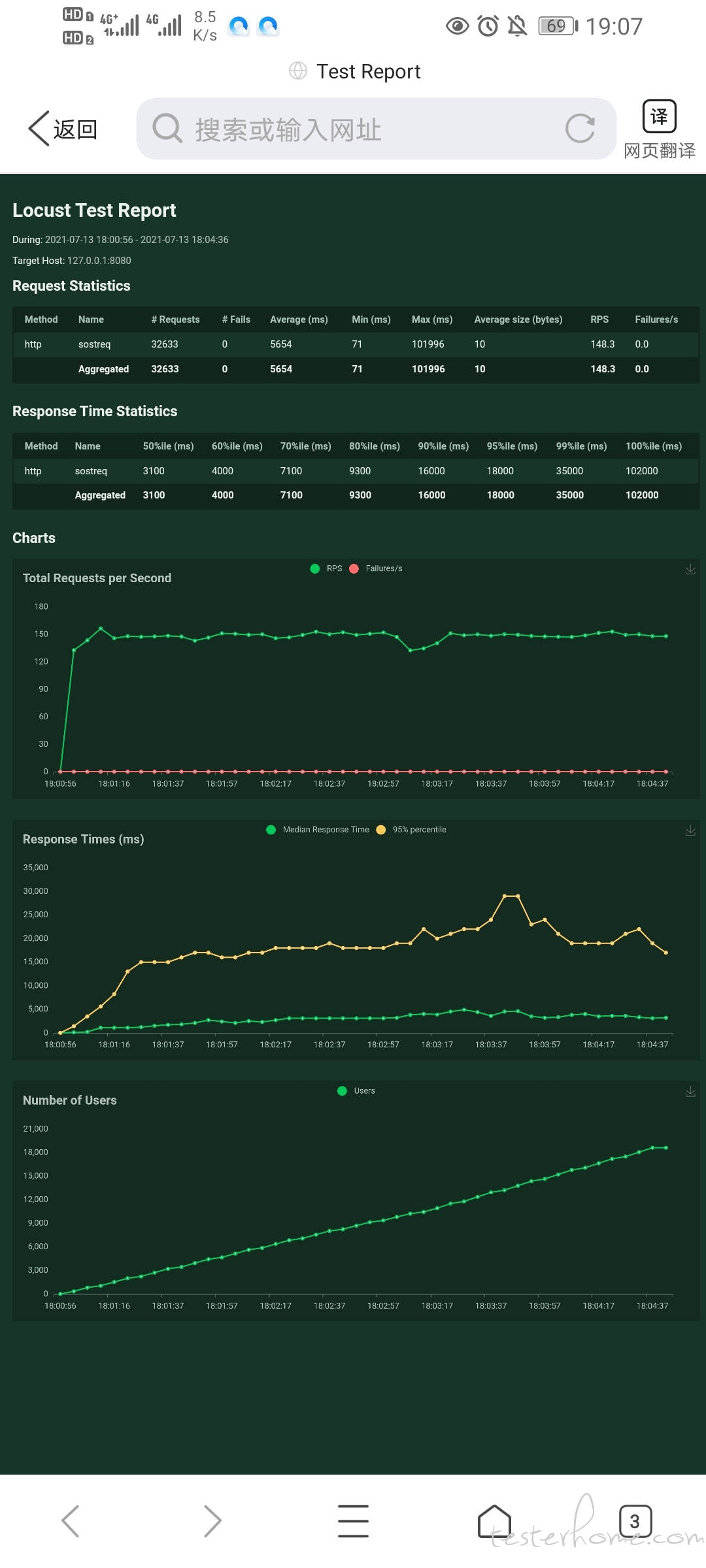
1.这个报告中的 rps 可以直接给领导说是每秒并发嘛
- 应该从哪些地方进行排查呢
性能测试跟功能一样,先得有需求吧,再有设计,执行,比对预期结果和实际结果。
光从图上看,几千用户的时候 rps 就到峰值,后面的响应时间都是几十秒,什么业务系统能容忍这么高的响应时间呢?
如果是想把服务器 CPU 压满,那对于瓶颈本来就不在 CPU 的怎么压,再说 RPS 都上不去了追求 CPU 利用率有什么意义。
没怎么用过 locust ,先好奇问下,最后一个 number of users ,y 轴指的是并发线程数,还是累计用户数?
如果是累计,从斜率说明发送请求的速度是恒定的,那这个 rps 是否已经极限不好说,要换下并发线程数看下是否还是保持一致。不过从响应时间 95% 已经增大到这么大的数据看,大概率已经达到极限了。
如果是并发线程数,rps 应该早就极限了,但响应时间却在 1 分钟左右达到了一个相对稳定的值,只能理解为系统有自动降级措施,直接放弃处理请求直接返回了,所以响应时间没有继续涨。
两万多用户只有一百多 rps?响应时间太长了,rps 上不去,cpu 基本上就上不去了,先把响应时间降下来,把 RPS 搞上去,cpu 自然就上去了
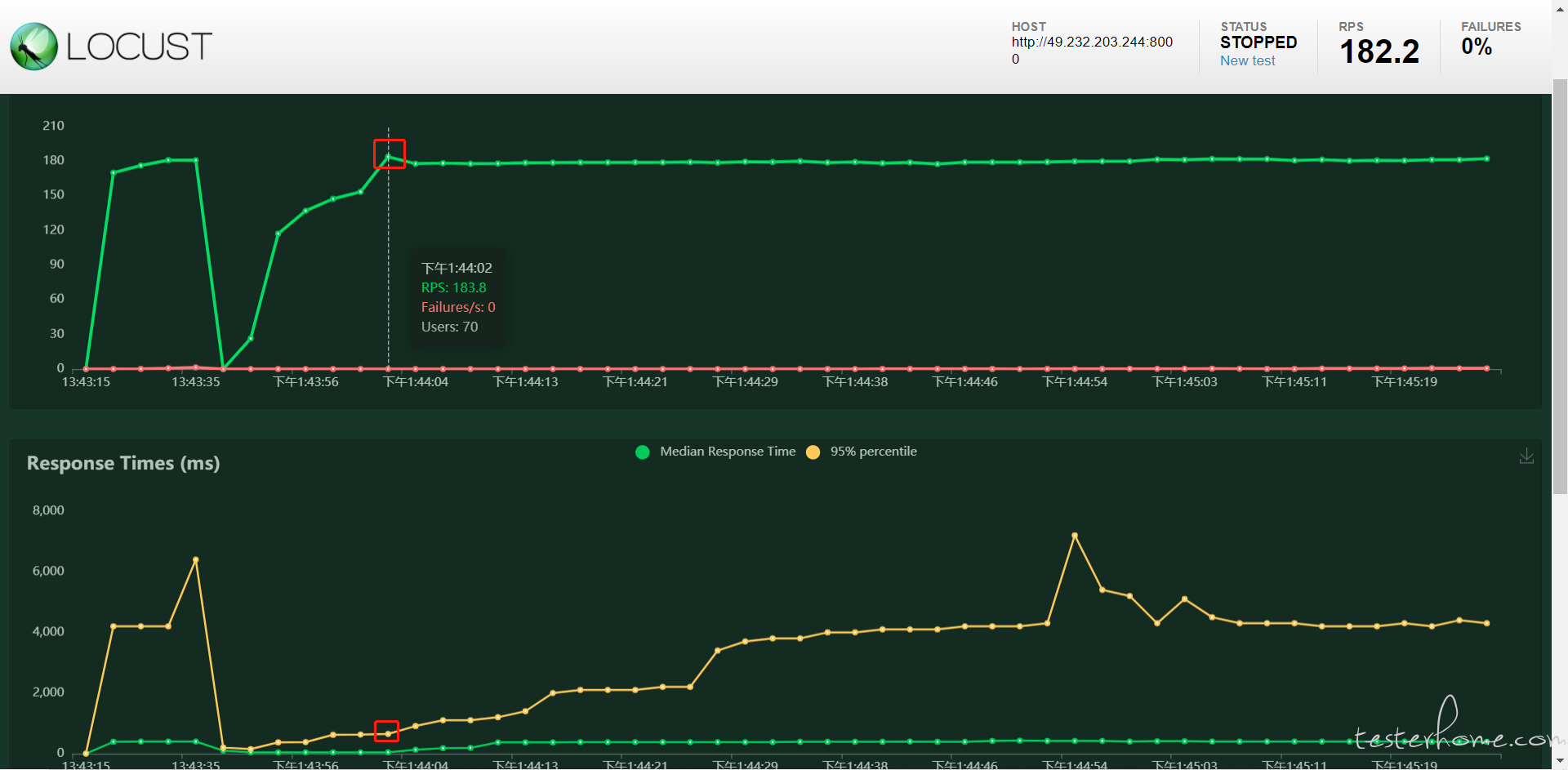
那就是并发线程数恒定了,压力相对恒定了。
这个报告中的 rps 可以直接给领导说是每秒并发嘛
从现在的响应时间增大情况看,其实早就达到系统瓶颈点了(响应时间涨,说明系统现有的处理线程不够用,有不少请求其实已经在排队而非立即处理了)。建议并发线程数从 10 开始,先试试,然后逐步增加,看到多少的时候 rps 就不再上去,而是响应时间增加。
应该从哪些地方进行排查呢
不知道你说的排查是排查啥,这里的信息看不出啥呀。比如你说 cpu 不再上升,按照你现在性能表现分析,有可能是请求在队列里等待,实际处理线程已经是配置范围内全负荷运行了,那 cpu 不再上升也不奇怪(在队列里等待不会消耗 cpu 的)。如果确认这个接口的处理逻辑属于计算密集型,要通过提升 CPU 利用率提高性能,可以考虑增大线程数配置,让它同时多干点活。
抱歉,个人想先试试避免后面用,像之前的场景基本老大也是说直接压,然后完了 问 多少并发,同时当时的响应时间等指标情况,属于纯小白...
并发数这个概念每个人理解都有不同,没有统一的定义。按照高楼老师在极客时间性能课程的定义,并发数就是 rps,指代系统实际最高性能。
压测工具里的用户数(并发线程数)不能代表真实用户的,毕竟真实用户不一定会这么高频访问接口。
建议你买本性能测试相关的书,或者看看极客时间里高楼老师性能测试的课程,先把性能测试相对完整的了解一下。
这响应时间看 QPS 没啥意义的