场景一:压测过程中,登陆只需要执行一次,其他业务接口执行 N 次
方案一
1、将登陆接口,三资管理业务接口分别放置两个线程组
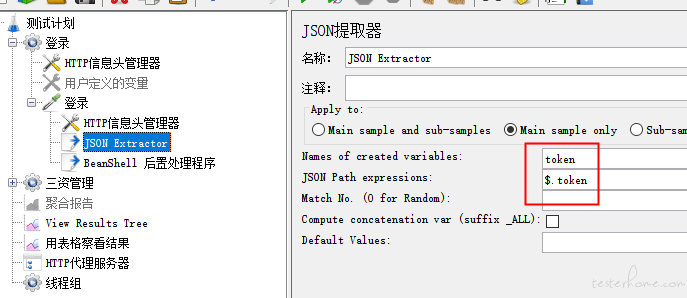
2、用 JSON 提取器提取登陆接口返回值的 token
3、用 BeanShell 后置处理器,将 token 设置为全局变量 newtoken

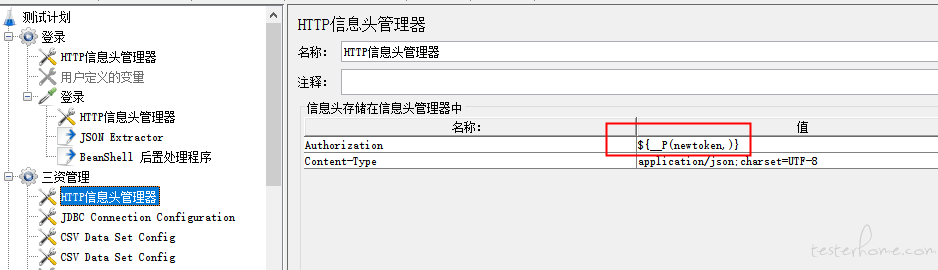
4、业务线程组的 HTTP 信息头管理器,引用 newtoken 的全局变量
方案二
1、登陆和业务接口都在同一线程组,将登陆接口放在吞吐量控制器下

2、吞吐量控制器选择 ‘Total Executions’,并设置吞吐量为 1.0
备注:不明白为什么仅一次控制器控制登陆接口无效
场景二:在实际业务中,比如淘宝购物,大部分时间在浏览商品,有时会将看重的商品添加到购物车,最后进入购物车,会勾选其中某几样商品一起支付,因此可能浏览商品的操作占 70%,加入购物车占 20%,支付占 10%
方案一
1、就三资产改项目而言,将收付款以及审批流相关接口,放在 A 吞吐量控制器下,选择 percent executions 吞吐量设置为 70.0
2、农银支付相关接口,放在 B 吞吐量控制器下,选择 percent executions 吞吐量设置为 20.0
3、财务相关接口,放在 C 吞吐量控制器下,选择 percent executions 吞吐量设置为 10.0
场景三:有些压测标准中要求 TPS 或 QPS,即吞吐量达到 50,即每秒处理的事物数达到 50 笔
方案一
1、一般来说 TPS 跟并发数有关,TPS 就好比一条马路,同时允许多少辆车可并行通过,即要求马路够宽,若并发量设置为 1,每秒通过一辆车,那 TPS 是 1,若设置并发量为 10,那 TPS 最大可能达到 10,但若遇到堵车情况下,TPS 会小于 10
2、结合 jp@gc Composite Graph,jp@gc Transaction Throughput vs threads 查看性能瓶颈点
3、若 TPS 曲线波动很剧烈,则说明可能压力设置不合理导致的,可将线程启动时间设置大一点
场景四:审核流程中,当前列表是待审核状态,当审核之后就变成已审核,在当前列表找不到了的
方案一
1、设置 JSON Extractor,提取返回值的 fid

2、选取审核记录,审核的入参,引用新增转账申请的返回值
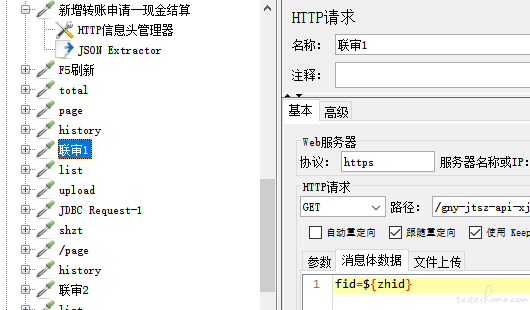
3、审核提交,入参有 taskid 参数,但前面的接口返回值并没有 taskid,因此需要通过第一个接口的 fid 的返回值,到数据库查询对应的 taskid


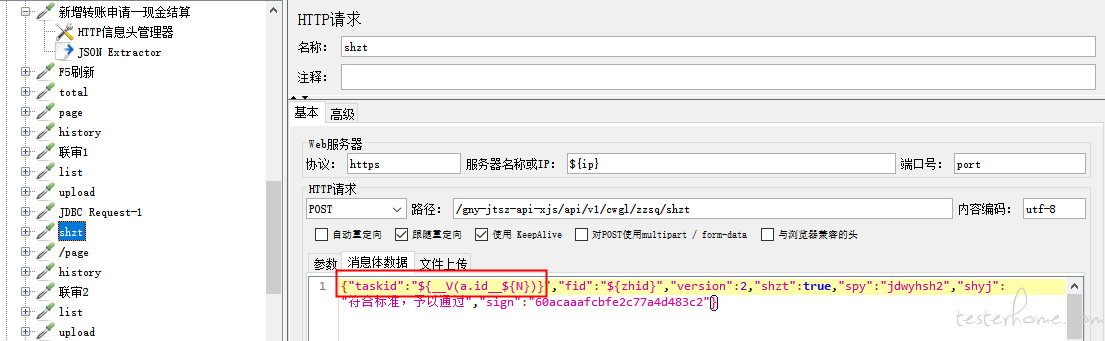
备注:也可以不用计数器提取,可直接在 shzt 的 http 请求中 taskid 直接调用 ${a.id_1}
场景五:上一接口的返回值中的一部分,作为下一接口的入参,如下图 7680 为下一接口的入参

方案一
1、获取接口返回值,并转为 json
String response = prev.getResponseDataAsString();
JSONObject responseJson = new JSONObject(response); //将返回值转json
log.info("输出转换为json的响应数据:"+responseJson);
2、继续获取 data 的值
JSONArray get_data = responseJson.getJSONArray("Data");
log.info("接口返回data为:"+get_data);
3、字符串截取
String dataString = get_data.toString(); //转为string格式
log.info("dataString为:"+dataString);
String[] splitStr=dataString.split("="); //根据等号进行字符串分割
log.info("分割后为:" +splitStr[1]);
szid = splitStr[1].substring(0,splitStr[1].length()- 2); //去除末尾两个字符
log.info(szid);
4、最后要保存为 jmeter 可调用的参数
vars.put("szid",szid); //将szid保存为jmeter参数
5、完整的 BeanShell 脚本
import org.json.*;
import org.json.JSONArray;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
String response = prev.getResponseDataAsString();
JSONObject responseJson = new JSONObject(response); //将返回值转json
log.info("输出转换为json的响应数据:"+responseJson);
JSONArray get_data = responseJson.getJSONArray("Data");
log.info("接口返回data为:"+get_data);
String dataString = get_data.toString(); //转为string格式
log.info("dataString为:"+dataString);
String[] splitStr=dataString.split("="); //根据等号进行字符串分割
log.info("分割后为:" +splitStr[1]);
szid = splitStr[1].substring(0,splitStr[1].length()- 2); //去除末尾两个字符
log.info("最后的szid:" + szid);
vars.put("szid",szid); //将szid保存为jmeter参数
/*
Matcher s = Pattern.compile("(?<=(\\[\"[^=]{0,20}=))[0-9]+(?=(\"]))").matcher(dataString); //正则表达式提取方式,即提取最后的szid
s.find();
String szid= dataString.substring(s.start(),s.end());
log.info(szid);
vars.put("szid",szid); //将szid保存为jmeter参数
*/
输出打印为

场景六:一次性做了多笔单子,然后支付前逐一浏览每个单子详情,而不是做一笔单子,浏览一笔单子
方案一
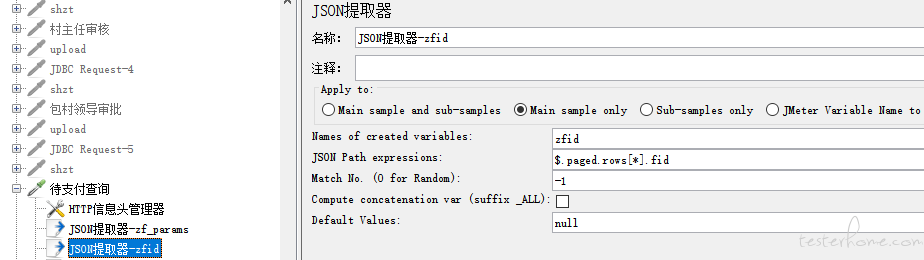
1、利用循环控制器,查看多笔待支付单据详情,先通过 JSON 提取器获取待支付查询接口的返回值的所有 fid
2、添加 debug 调试取样器,执行后再查看结果树种可以看到 debug 调试取样器的参数值

3、控制循环次数
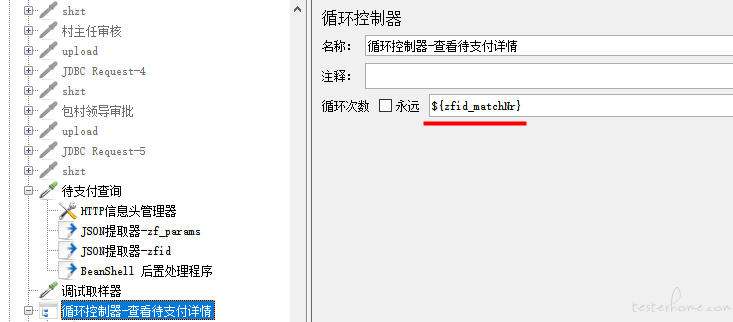
4、将查看待支付详情接口,放在循环控制器下,以此传递每个 zfid

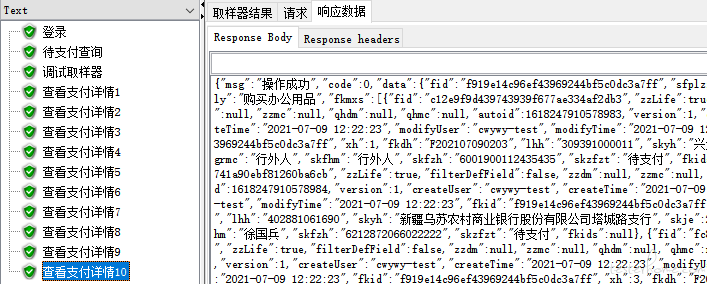
5、查看结果
场景七:批量选择操作,比如批量选择未支付的单据,点击支付按钮;而不是做一笔单据支付一笔
方案一
1、查询待支付的记录,如下一个{ }里是一笔单据,需要将所有的单据作为下一个接口的入参
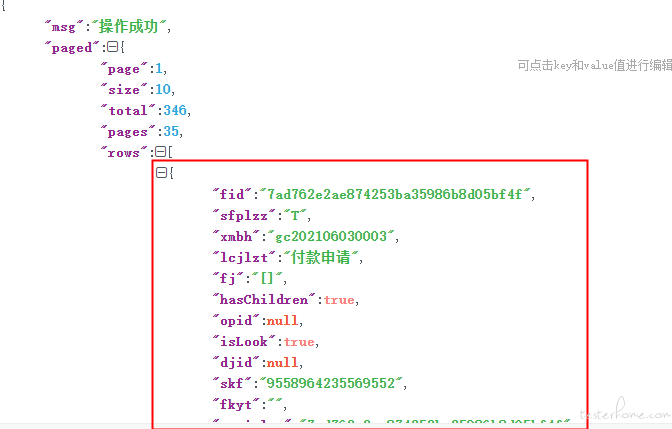
2、提取 rows 的所有值

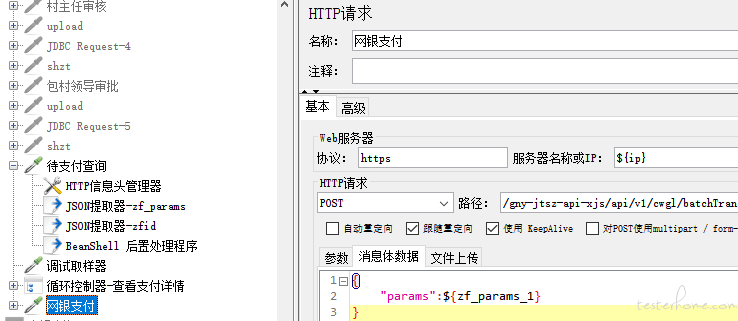
方案二
1、预想将上一接口的所有返回值逐一提取,再拼接为整个字符串,作为下一接口的入参
log.info("支付数量为:" + vars.get("zfid_matchNr")); //先获得支付数量
int num = Integer.valueOf("${zfid_matchNr}");
log.info("num:" + num);
String zfids = "";
//再循环支付id,并拼接字符
for(i=1; i<=num; i++){
String zfid = vars.get("zfid_" + i);
log.info("zfid为:" + vars.get("zfid_" + i));
zfids += zfid + ","; //将所有的zfid提取并以逗号拼接后赋值给zfids
}
zfids = zfids.substring(0,zfids.length() - 1); //去除zfids末尾的逗号
log.info("zfids为:" + zfids);
2、一开始想的是方案二,但猛地发现方案一也行,正好返回值和下一入参的格式恰好一样的,所以就不用考虑拼接了,所以方案二没有继续往下写。
场景八:校验某个查询接口的返回值是否正确
方案一:返回结果与数据库的值进行对比
1、先了解下 beansheell 的常用方法
(1)vars.get(String key):从 jmeter 中获取 String 变量值;
(2)vars.getObject(key): 从 jmeter 中获取非 String 变量值;
(3)vars.put(String key,String value): String 数据存到 jmeter 变量中;
(4)vars.putObject(key, value):非 String 数据存到 jmeter 变量中;
(1)getString(“字段名”):获取字符串型字段值;
(2)getBoolean(“字段名”) :获取布尔类型字段值;
(3)getInt(“字段名”):获取整型字段值;
(4)getLong(“字段名”):获取长整型字段值;
(5)getDouble(“字段名”):获取双精型字段值;
(6)getJSONObject(“字段名”):获取嵌套 Object 类型字段值,JSONObject 类型;
(7)getJSONArray("字段名"):获取嵌套 Array 类型,JSONArray 类型;
2、从数据库中根据条件统计数据
3、获取接口返回的统计数据
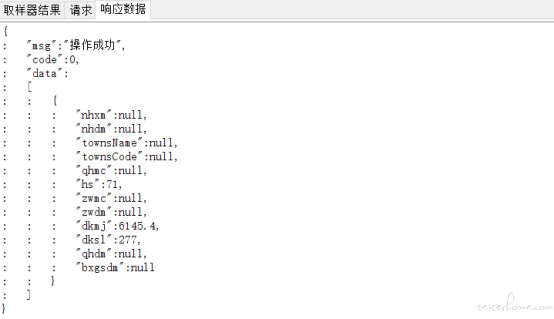
4、接口返回数据与数据库统计数据是否一致

方案二:输入的查询值与查询结果进行对比,比如查询农户代码 A,那么查询结果的返回值的农户代码字段也应该是 A
1、获取接口返回的数据

2、接口返回数据与输入的查询条件是否一致

场景九:接口返回了一数组,但不确定用数组中的哪一行的记录,因为数组的顺序是动态变化的,要求根据一变量获数组中对应的字段内容

比如:若上图中 businessKey 值 = 上一接口返回的 businessKey 值,则取出对应的 taskid
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.json.*;
String jsonContent = prev.getResponseDataAsString();//获取到上一个接口的返回json
JSONObject response = JSON.parseObject(jsonContent);//将接口返回json赋值给obj对象
JSONArray dataList = response.getJSONObject("data").getJSONArray("rows");
//取出datas数组,赋值给array
int length = dataList.size();//数组长度
vars.put("m_length",length.toString());//vars放进去的参数必须是String类型的
log.info("m_length==="+length.toString());
String taskid="";//这里注意初始化必须是双引号
String businessKey="";
String fid = vars.get("zhid");
log.info("变量fid为:"+fid);
log.info("-----开始执行循环-----");
for(int i=0;i<length;i++){
//将数组元素临时转化成obj对象
//数组元素一个个取出来,取出businessKey的值
JSONObject jsonTemp = (JSONObject)dataList.getJSONObject(i);
log.info("jsonTemp---->"+jsonTemp.toString());
businessKey = jsonTemp.get("businessKey");
log.info("businessKey---->"+businessKey);
//如果满足条件,则取出对应的taskId,循环终止
if(businessKey.equals(fid)){
taskid = jsonTemp.get("taskId").toString();
break;
}
else{
continue;
}
}
log.info("taskid:"+taskid);
vars.put("taskid",taskid); //通过put方法,使获得的taskid可以通过$(taskid)外部进行调用
注意要引用 import com.alibaba.fastjson.JSON; 则需要引用对应的包 fastjson-1.2.78
执行结果为:

场景十:时间差的调整
比如新疆和国外,与北京时间是有一定时间差的,在北京通过 jmeter 执行出来的记录时间与其他远地区本地服务器运行出的数据是有一定时间差的
__TimeShift(格式,日期,移位,语言环境,变量):可对日期进行移位加减操作
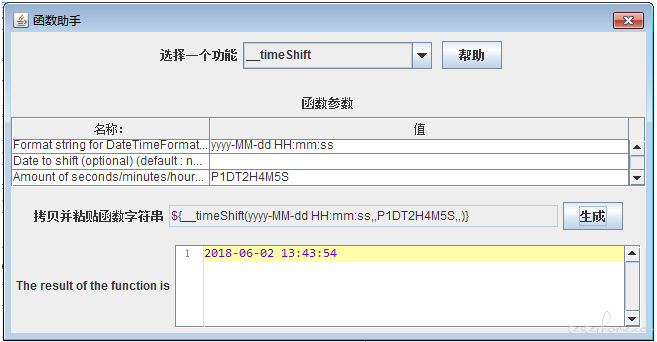
格式 - 将显示创建日期的格式。如果该值未被传递,则以毫秒为单位创建日期。
日期 - 这是日期值。用于如果要通过添加或减去特定天数,小时或分钟来创建特定日期的情况。如果参数值未通过,则使用当前日期。
移位 - 表示要从日期参数的值中添加或减去多少天,几小时或几分钟。如果该值未被传递,则不会将任何值减去或添加到日期参数的值中。
“P1DT2H4M5S” 解析为 “添加 1 天 2 小时 4 分钟 5 秒”
“P-6H3M” 解析为 “-6 小时 +3 分钟”
“-P6H3M” 解析为 “-6 小时-3 分钟”
“-P-6H + 3M” 解析为 “+6 小时和-3 分钟”
区域设置 - 设置创建日期的显示语言。不是必填项
变量 - 创建日期的值将被分配给的变量的名称。不是必填项