会员
Ayo (Ayo)
第 62296 位会员 / 2021-04-30
11 篇帖子 • 112 条回帖
-
100 个赞 / 36 条回复
-
39 个赞 / 37 条回复
-
32 个赞 / 11 条回复
-
29 个赞 / 17 条回复
-
22 个赞 / 13 条回复
-
21 个赞 / 23 条回复
-
20 个赞 / 6 条回复
-
15 个赞 / 28 条回复
-
13 个赞 / 3 条回复
-
5 个赞 / 4 条回复
-
公司现在需要写一份用 AI 辅助测试的调研报告 at 2025年10月31日
自研的 Agent 开发平台,类似在线创建一个 Planning/ReAct Agent
-
对 AI 测试的一个想法 at 2025年10月31日
其实就是一个 ReAct Agent 自主规划你给他的一些 Tool , 例如读写文件/执行命令啥的, 最后通过 Tool 或者 Prompt 约定输出就好啦。
-
对 AI 测试的一个想法 at 2025年10月30日
上个月基于代码/监控做的 AI 分析可以精确到行,以及提交人等 SCM 信息。后续对话解决方案/创建任务/创建 MR/ 也仅仅是几个 Tool
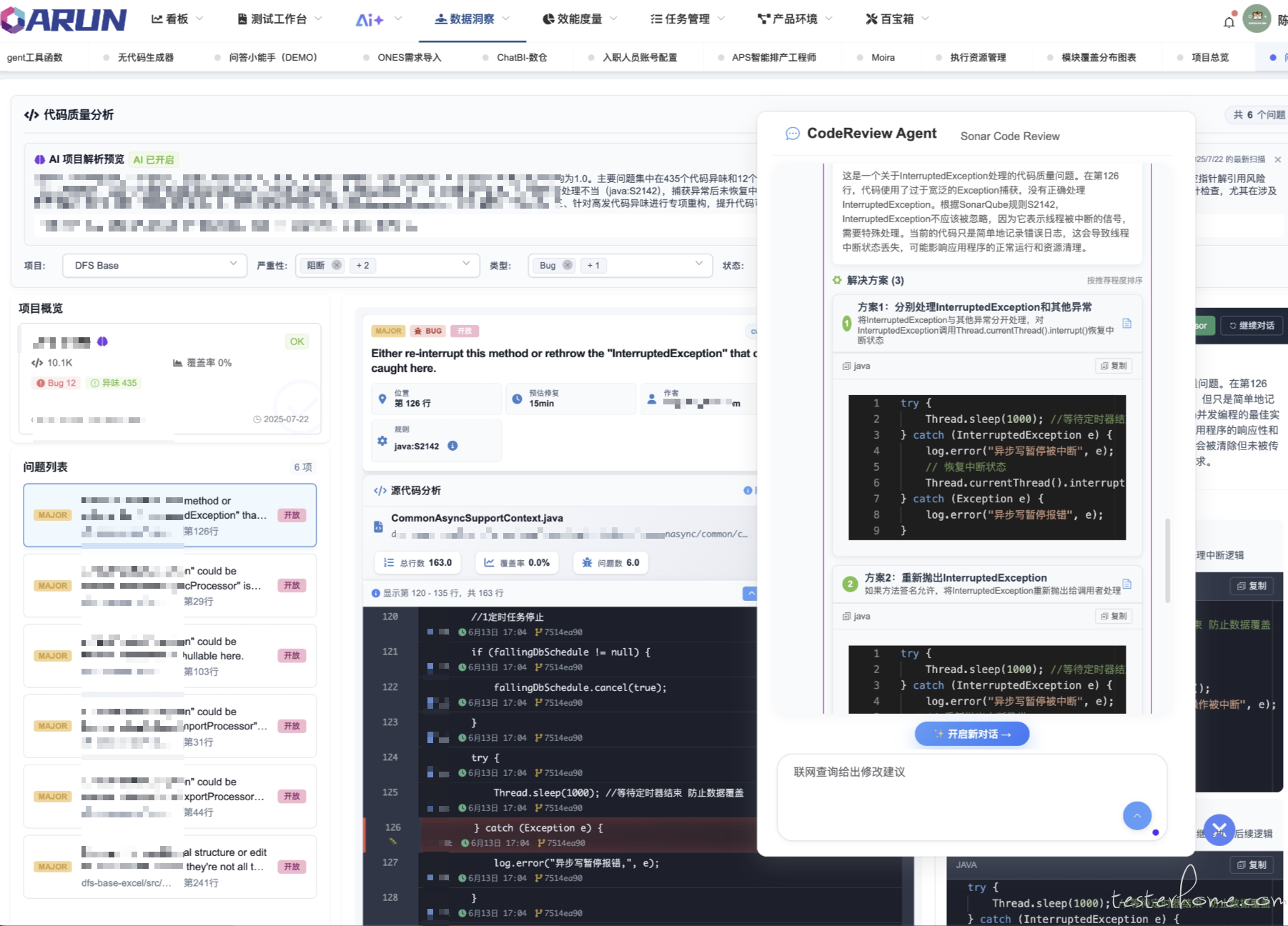
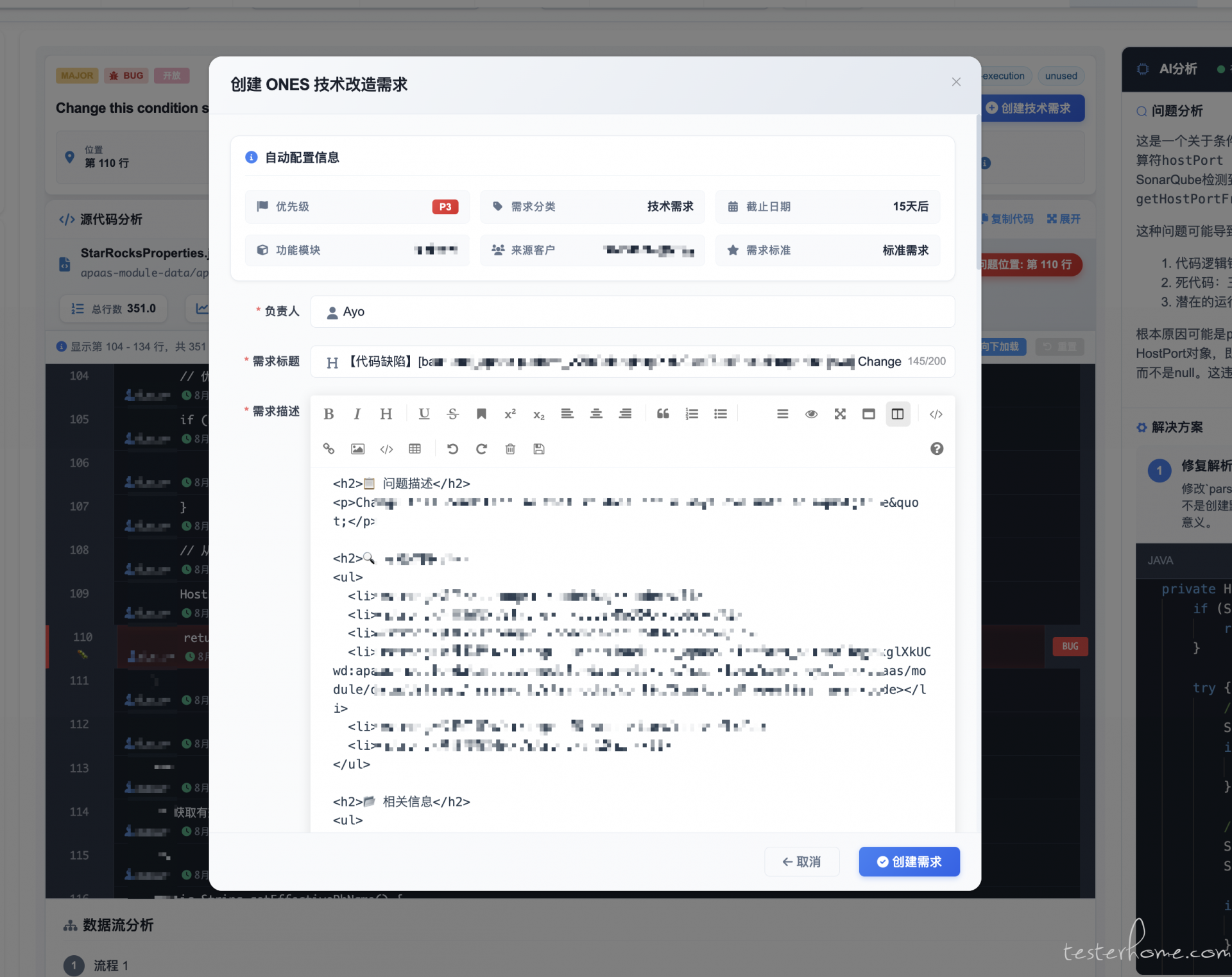
-
公司现在需要写一份用 AI 辅助测试的调研报告 at 2025年10月28日

-
Agentic X:LLM Agent 在测试领域的探索与思考 at 2025年09月26日
这样子的话 内网内的应用无法使用哇
 这种就属于 Agent 这种更高级别的接口逆向了, 如果只逆向 LLM 的 API 本地跑 Agent 内部调用远端的 LLM 也可以哇
这种就属于 Agent 这种更高级别的接口逆向了, 如果只逆向 LLM 的 API 本地跑 Agent 内部调用远端的 LLM 也可以哇 -
Agentic X:LLM Agent 在测试领域的探索与思考 at 2025年09月25日
如果你的底层实现是自主规划的 Agent, 那么你只需要给这个 Agent 写获取页面结构的 Tool,页面截图的 Tool 以及图片理解获取坐标的 Tool, 在 prompt 给个设定,优先使用获取结构进行下一步,如果出错可以采用图片理解坐标点击。 他会在每一步思考过程中 选择 Tool 进行下一步尝试
-
Agentic X:LLM Agent 在测试领域的探索与思考 at 2025年09月23日

 好样的 多多交流~
好样的 多多交流~ -
自动化平台上的 case 大家是如何编写和思考的? at 2025年09月01日
可以把重复多的公共步骤封装一个子流程作为引用,这样子只需要改子流程就好啦。
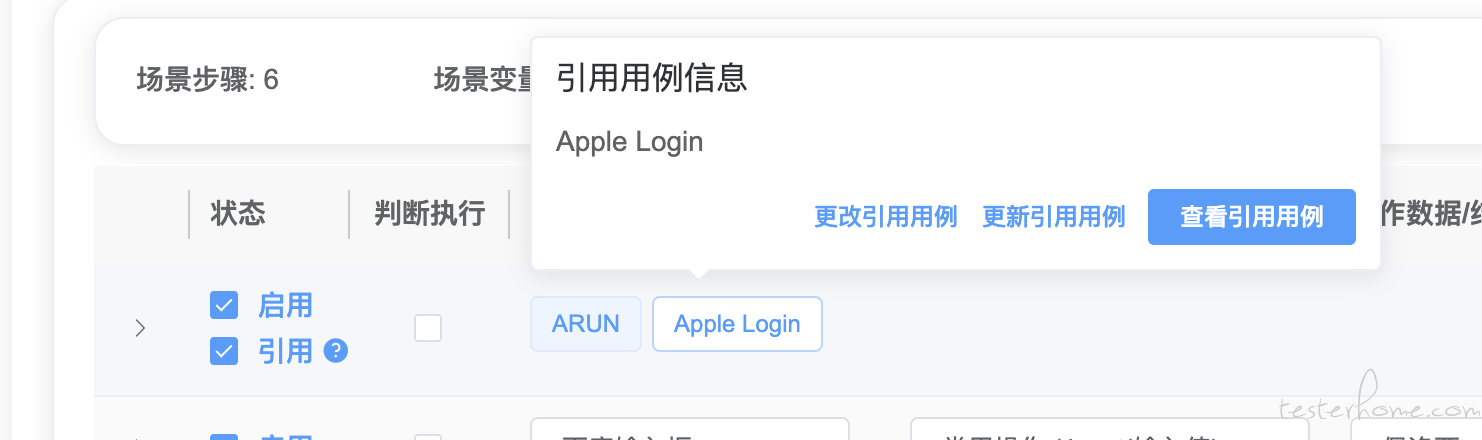
-
自动化平台上的 case 大家是如何编写和思考的? at 2025年08月29日
几年前做的样式,现在普通小白用起来还蛮简单,主要做法就是元素独立维护,用例里面选择元素,动作,入参等。
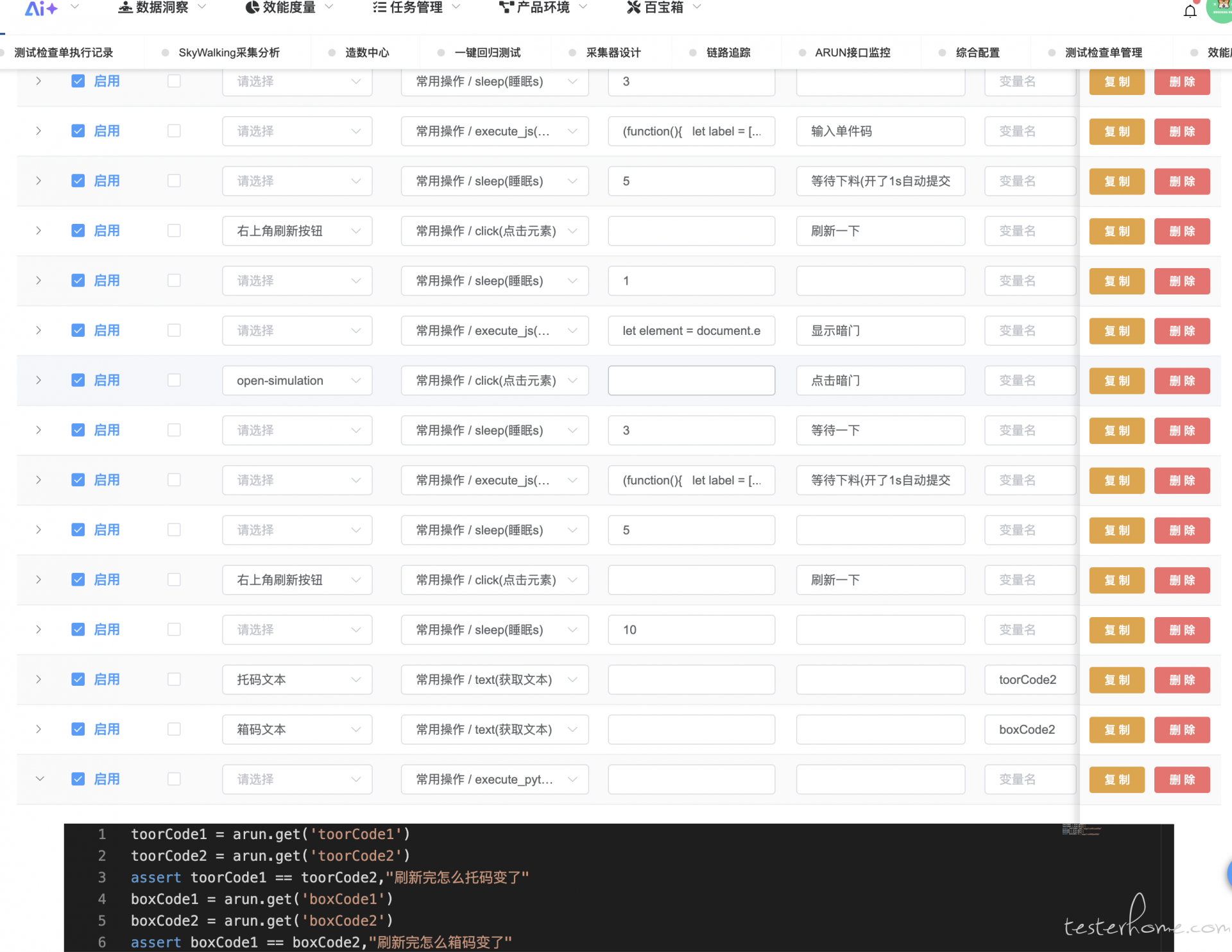
-
AI 本地知识库创建探讨 at 2025年07月31日
我是从 0-1 开发过,一般常用 RAG 比如 FastGPT/MaxKB/RAGFlow/Dify/Langflow 的我只借鉴过看过一丢丢, 可以加 AYO-YO-O 交流交流