会员
466895041 (重来看雨)
第 7549 位会员 / 2016-02-26
8 篇帖子 • 258 条回帖
-
19 个赞 / 29 条回复
-
10 个赞 / 16 条回复
-
3 个赞 / 16 条回复
-
1 个赞 / 7 条回复
-
0 个赞 / 27 条回复
-
0 个赞 / 4 条回复
-
0 个赞 / 3 条回复
-
0 个赞 / 3 条回复
-
那次上线后,我凌晨 3 点被叫起来修 Bug——"改了新功能,旧功能崩了"到底怎么破? at 2026年05月06日
需要一个契约测试。
-
openclaw 帮我做 cicd,性能自动化,接口自动化 at 2026年03月23日
gitlab webhook 监听就可以完成以上的流水线了,emm。不太理解这能解决什么。。
-
年终总结 at 2026年01月04日
恭喜
-
SDK 测试的自动化实现 at 2025年10月29日
SDK 跨语言比较难,建议不同的语言开发一个客户端,测试数据可以同一个存储,客户端做读取和数据格式处理。另外还有一种方法是在 SDK 项目里以单元测试的方式调用,测试数据同上。
-
软测副业 at 2025年10月20日
缅 A
-
有点好奇论坛大佬们提测后每天的产出 bug 量 at 2025年09月17日
如何要考核,线上 bug 率就很好。
-
自己脑洞大开做了一个西游玩家以唐僧视角去西天取经的小游戏(暂时是 demo) at 2025年07月14日
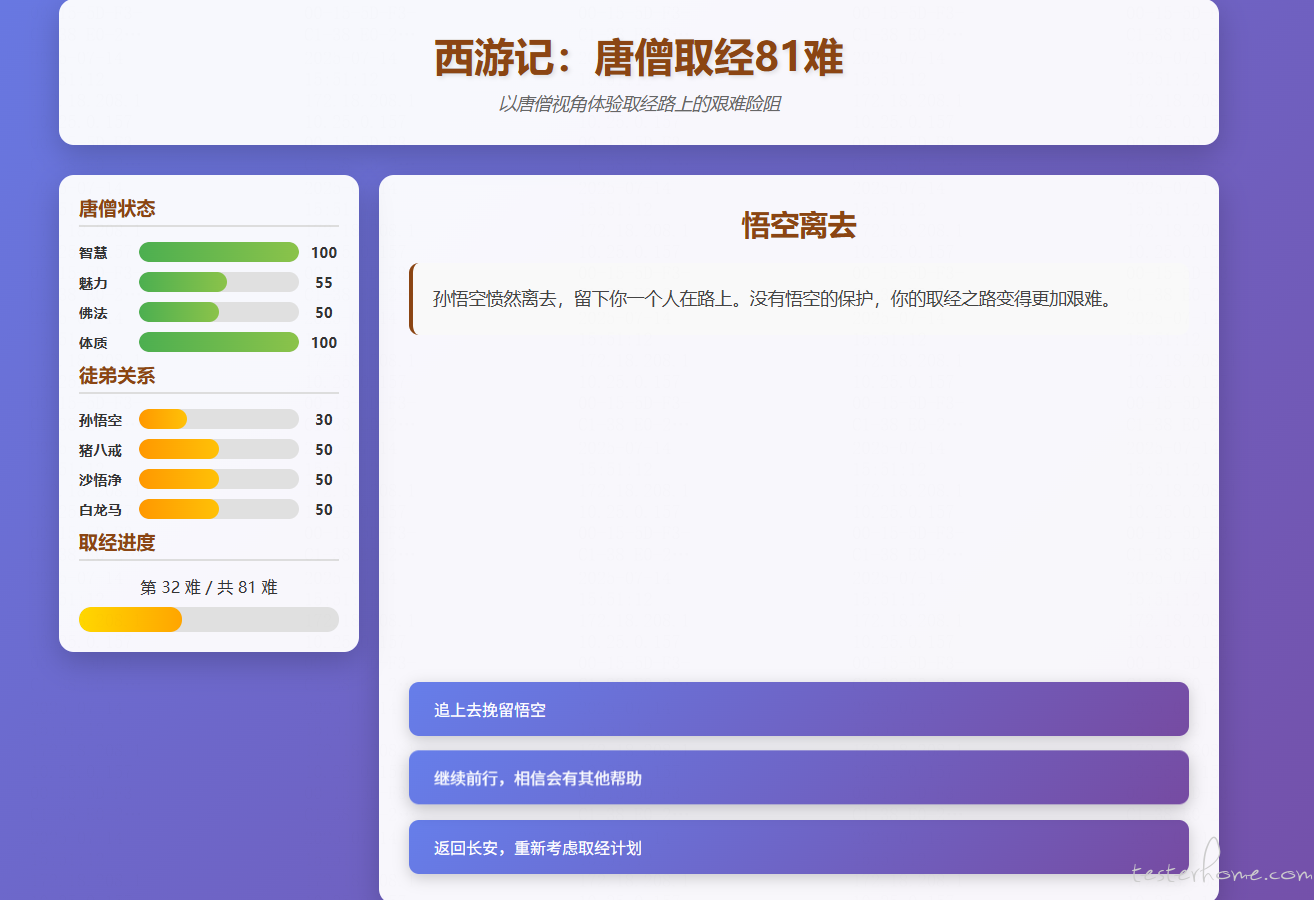
一直点继续前行。但一直无法跳转 -
自己脑洞大开做了一个西游玩家以唐僧视角去西天取经的小游戏(暂时是 demo) at 2025年07月14日
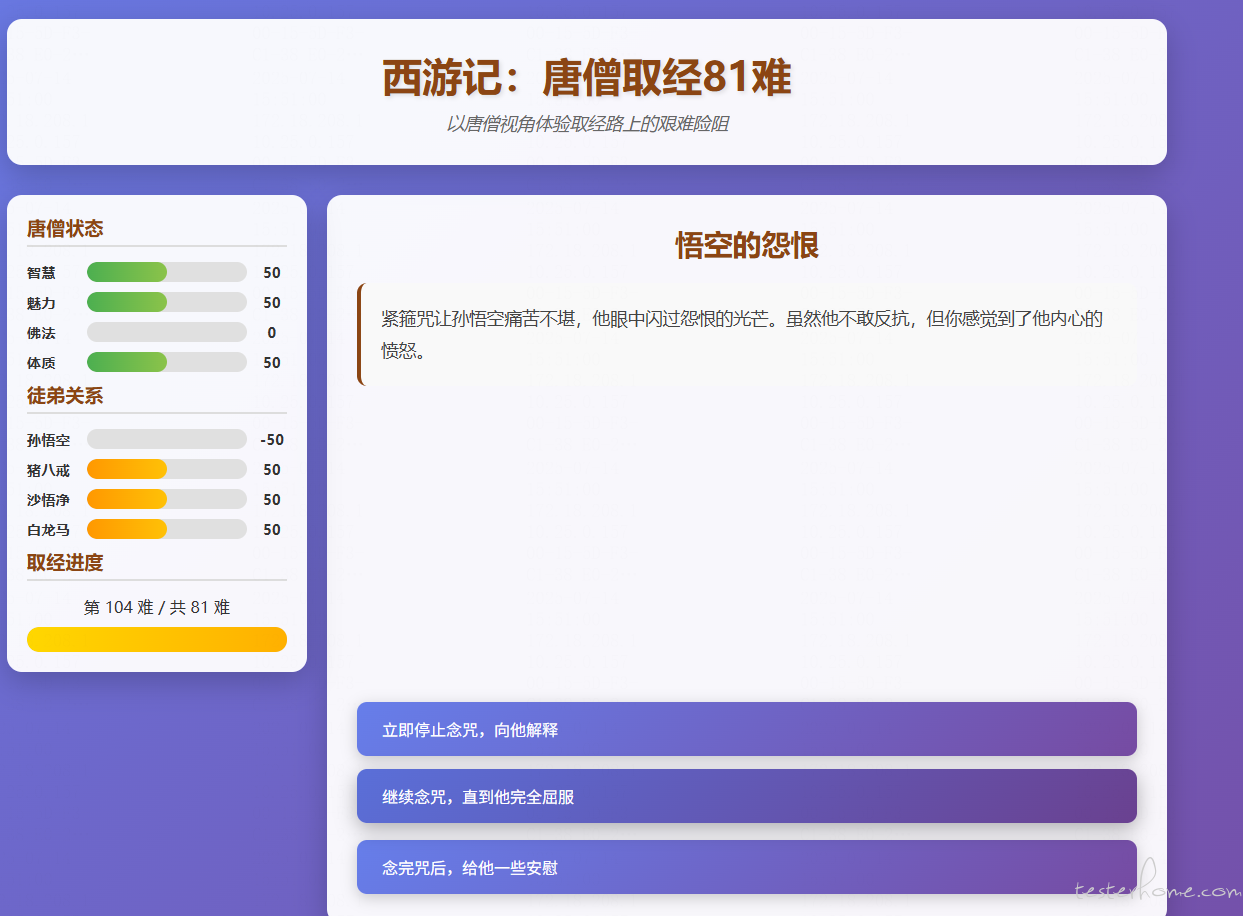
一直点念咒就有 bug -
说一点公司那些让你瞠目结舌的瓜吧 at 2025年07月04日
男 A 与女 B 外地出差偷情,持续时间多久不了解。被男 A 老婆知道了。深夜男 A 老婆用男 A 的账号发公司大群曝光。
-
请教下有没有在 slb 或者 nginx 层面实施 mock 的开源框架,最好是 java 的 at 2024年11月15日
具体得看链接架构,然后尽量不要侵入被测的服务代码。从看到标题是 slb 和 nginx,我理解链路是 A 服务 请求到 B 服务,A-->B 加一层代理,即 A 请求到 slb/nginx 后,反向代理到 mock 服务或者 nginx 应答即可。至于采用那种,看具体协议。
mock 服务关键输入输出的控制,有时间可以自研。美团这个文章不错 https://tech.meituan.com/2015/10/19/mock-server-in-action.html