AI测试 我造了一个测试分身,它现在在帮我干活
我是一个 QA,但现在我大部分时间不在测试,在写 coding 自己的分身和审阅它的产出。
不是转岗,是我给自己造了一个测试分身——它帮我扛掉了 80% 的重复劳动,我才有时间去做真正需要动脑的事。
几个月前,我的工作状态是这样的:一天写 几十条用例,写完还要一条条手动执行验证,最怕的不是写不完跑不完,是漏了什么关键用户场景自己可能不知道。现在同样的需求,从用例到执行到结果,时间砍半的同时我还在干其他的活。
下面是造它过程中想明白的几件事。
一、人脑不适合穷举,但穷举恰恰是用例编写的核心
测试用例的本质是什么?是把一份需求文档翻译成"所有可能出错的地方"。
这件事需要两种能力:理解力和穷举力。理解力是读懂业务逻辑,穷举力是不重不漏地列出每一个边界场景。
人擅长前者,机器擅长后者。
但传统的工作方式是让人同时干这两件事。所以你会觉得写用例很累——累的不是打字,是一边理解需求一边逼自己穷举,怕漏。
我的测试分身做的事情就是把这两件事拆开。理解和判断留给我,穷举和结构化交给 AI。
具体来说:粘贴需求,AI 30 秒生成一版完整用例,我在它的基础上审核、补充、调整。从"从零构建"变成"在已有基础上优化"。
这个转变看起来小,心理负担的差距是巨大的。
二、让 AI 写用例,我踩的坑
第一个坑:一次性让 LLM 生成大量的用例,质量崩塌。
原因很反直觉——不是模型不够强,是你给它的任务太大了。就像你让一个人同时想十件事,每件事都想不深。
解法:分阶段思考。先让 LLM 只读需求、提取关键实体(不生成用例)。然后划分模块。最后按模块逐一生成。"先列提纲再写文章",覆盖率直接上了一个台阶。
第二个坑:让 LLM 输出 JSON,流式传输中必崩。
为什么需要 JSON?因为我做了用例的脑图展示——按模块、优先级把用例组织成树状结构,需要结构化数据来驱动渲染。但 LLM 输出 JSON 在流式传输时非常脆弱,一个未闭合的括号就导致解析失败。
我改成了分隔符协议——每条用例用特定标记分隔,看到标记就知道一条结束了,立刻解析成结构化数据渲染到脑图上。不依赖完整 JSON 闭合,对流式输出天然友好。
第三个坑:生成需要时间,干等体验很差。
最早是等十几秒,然后一次性出现所有用例。问题不只是"感觉慢",而是等待过程中你的注意力已经跑了——切到别的窗口干别的事,写用例的上下文就断了。
改成实时推送后,用例一条条"长"出来,脑图实时展开。你的注意力始终跟着 AI 走,上下文不会断。
这样的做法在心理学上叫 Continuous Partial Attention——持续的部分注意力。你不需要盯着看,但你的余光知道事情在推进,你的脑子没有离开这个工作上下文。
当生成完成、用例卡片同时渐入的那一刻,用户不需要"重新理解发生了什么",因为他一直在场。你的分身没有把你晾在一边去后台处理任务,它一直在你旁边工作,你们始终在同一个空间里。
三、假设机制:干活的时候让 AI 分身主动说"这个地方我不确定"
需求文档永远写不完整。"用户名长度限制"——限制多少?没说。"超时自动退出"——多久算超时?也没说。
传统做法:简单的自己猜,上线发现猜错了。涉及逻辑的,反复和产品研发确认,我累他们也累。
我给 AI 下了一条指令:对于需求中没有明确说明的地方,你必须显式标注你的假设。
于是 AI 在生成用例的同时,会产出一份"假设清单":
问题:从外部复制的文本恰好匹配枚举值时,是否允许粘贴?
假设:完全匹配则允许
影响用例:枚举值不存在时报错
每条假设下面有输入框,当我填上实际情况,AI 自动调整相关用例。
以前和产品对需求,是我追着问、一来一回。现在是拿着一份假设清单一次性对齐。沟通效率提升非常明显。
回头想,这其实是一个反共识的设计。大部分人做 AI Agent,追求的是"AI 自信地给答案"。但我发现,让 AI 主动说"这个地方我不确定",反而比它自信地猜错有用一万倍。
不确定性不是 AI 的缺陷,是可以被设计成特性的。
四、AI 代跑——从"步骤复读机"到"有经验的测试搭档"
写完用例只是开始,执行才真正吃时间。
我集成了浏览器自动化和 Pi。给 AI 一个 URL 和一组用例,它打开用户自己的浏览器继承登录态,读懂页面,一步步操作。
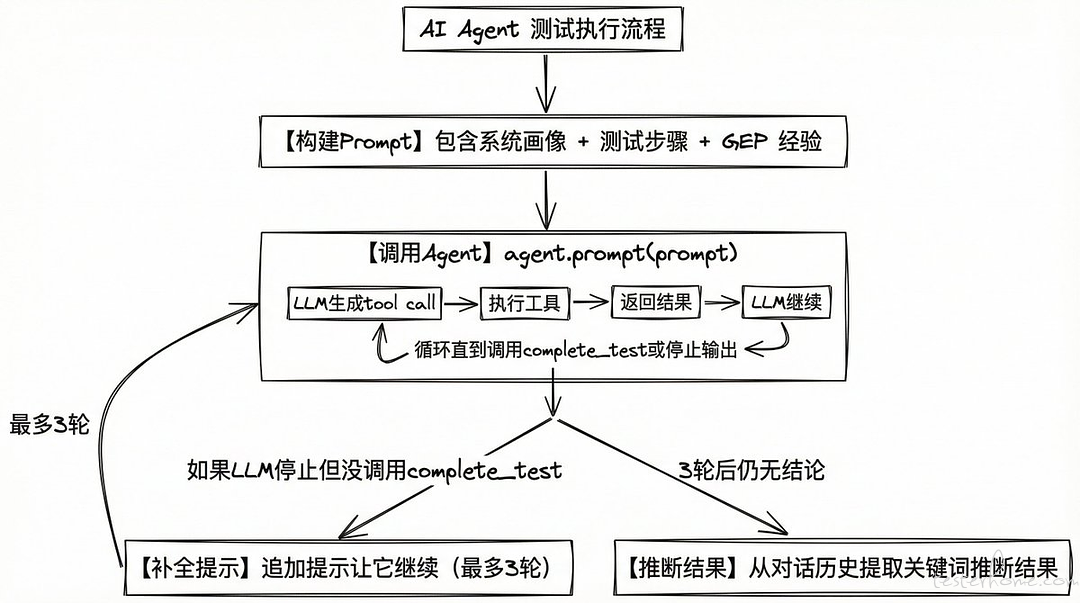
关键技术选择:让 LLM 怎么理解和操作页面?
最直觉的方案是截图 + 视觉模型——让 AI "看" 页面。但纯靠截图来定位元素和操作,慢、贵、对中文界面识别不稳定。
最终的方案是双通道并用:用页面的无障碍树(Accessibility Tree)来理解结构和定位元素——每个按钮、输入框都有结构化描述,相当于一份文字版的页面蓝图,LLM 处理起来又快又准;用截图来验证操作结果——点完之后看一眼页面变没变、对不对,像人一样用眼睛确认。
结构化数据负责"知道点哪",截图负责"确认点对了"。各取所长。
另一个设计决策:AI 跑测试用的是你自己的浏览器。通过 Chrome DevTools Protocol 连你本地的 Chrome,复用登录态和 Cookie。不需要额外维护登录脚本。
但真正让我兴奋的,不是"能跑",而是"越跑越聪明"。
早期版本的 AI 代跑,本质上是一个"步骤复读机"——你给它步骤,它逐条执行。页面稍微变一下,它就懵了。每次都从零开始理解页面,效率很低。
后来我参考了 EvoMap 的思路,引入了一套叫 GEP(Gene-Evolution Protocol)的机制,用生物进化的隐喻来解决这个问题。它有三层结构:
Gene(基因):把用例提炼成"测试意图 + 验收条件"。不是"第一步点登录按钮,第二步输入用户名",而是"验证正确账号密码能成功登录,验收条件是跳转到首页且显示用户昵称"。意图是稳定的,步骤是易变的。
Capsule(胶囊):记录一次成功执行的完整路径——点了哪些按钮、填了什么值、页面长什么样。同时记录当时的环境指纹(URL、页面结构、关键元素)。下次再跑同一个用例时,AI 会先比对环境指纹,决定执行策略:
环境高度匹配 → 复用,直接按上次的路径批量执行 环境部分变化 → 适配,参考路径但灵活调整 全新环境 → 探索,从头理解页面
Learned Insights(经验沉淀):每次执行中的发现会被提炼——某个按钮的选择器变了、某个操作需要等待 loading、某个流程有替代路径。这些经验会在后续执行中作为上下文注入给 AI。
说白了:第一次跑是探索,第二次跑是复用,跑得越多越快越稳。
这个设计解决了传统自动化测试最大的痛点——脆弱性。传统脚本里写死了"点击 id=submit-btn 的按钮",前端一改 id 就挂。GEP 的 AI 理解的是意图,不是死步骤。页面改版了,它会重新探索一条路径,成功后存成新的 Capsule,旧的自然淘汰。
像生物进化一样——适应环境的路径存活,不适应的被淘汰。
一条用例首次跑 30~60 秒,有 Capsule 复用后只要十几秒。批量 20 条十几分钟。跑完在脑图上标绿点红点,你只看红点就行。
五、80% 重复劳动的替代不是说说的
以前一份中等需求,从阅读到编写到执行,大半天。
现在:AI 生成用例几分钟,我审核调整一轮,代跑自动执行,最后只看失败的用例做判断。整个流程压缩到一小时以内。
但真正节省的不是时间,是焦虑。
以前最耗心力的是"怕漏"——不停问自己还有没有场景没想到。现在 AI 先铺一层完整的底,我在上面做精修。心理负担的差异远大于时间差异。
省下来的时间我做什么?设计探索性测试、分析线上故障、思考测试策略、和开发讨论可测性。
这些才是测试工程师真正的核心价值。以前全被用例编写挤占了。
六、最后一个感悟
做这个测试分身之前,我也想做全自动——需求进去报告出来,中间不需要人。
很快发现方向错了。
测试的价值不在"写了多少用例",在于质量判断——这个功能上线用户会不会炸?这个 bug 是偶现还是必现?这个边界值得不值得覆盖?
这些需要对业务的理解、对用户的同理心、对风险的直觉。目前 AI 做不了。
所以它叫"分身"不叫"替身"。它扛重复的活,方向盘在你手里。
最好的工具不是让人变得多余,而是让人有时间去做真正重要的事。
如果你也想造一个自己的工作分身,最重要的第一步不是选技术栈,而是想清楚:
你每天做的事情里,哪些是重复劳动,哪些是专业判断?
把前者交给机器,把后者留给自己。
