往期文章
专栏文章 质量保障系统的落地实践 (一) 概览篇
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 基础信息与缺陷信息设计
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 代码信息设计
专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 基础设计
专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 集成设计
专栏文章 质量保障系统的落地实践 (四) 效能管理设计 - 造数工厂
专栏文章 质量保障系统的落地实践 (五) 可视化设计
专栏文章 质量保障系统的落地实践 (六) 拓展延伸
专栏文章 质量保障系统的落地实践 (七)-AI 落地&指标评估
专栏文章 质量保障系统的落地实践 (八)-AI 赋能测试岗位
专栏文章 质量保障系统的落地实践 (九)-如何体系化设计自动化框架
最终成果
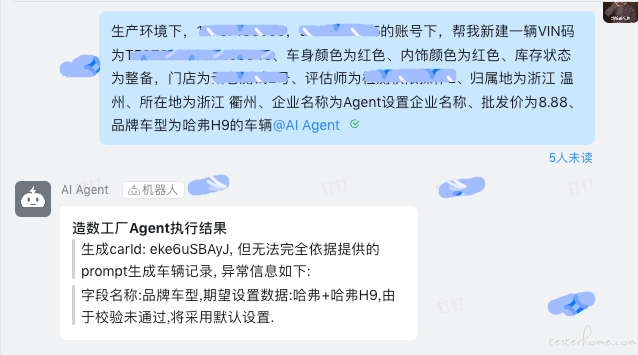
可以看到,调用方使用中文描述需求,Agent 依据需求通过 Skill 的组合完成了造数功能,并且将无法转换的内容做出了提示。
前言
大家好,我是困学。继上一篇文章介绍了如何体系化设计自动化框架,本篇文章中的 Agent 也可视作这套自动化框架的延展功能,有兴趣的朋友不妨再回头看看。
下面回到正题,这篇文章介绍的内容是如何搭建一个测试 Agent,测试的岗位职责可概括为:1、编写测试用例 (包含了前期需求、交互评审的过程);2、编写自动化脚本;3、提炼造数场景等等方面。本次的切入点在造数场景,这种 Agent 实现之后,能为后续设计并实现其他 Agent 如测试用例编写 Agent 等功能铺开道路。
Agent
通常我们使用的对话式 LLM,侧重问解惑,而不能直接替我们处理实际事务,因为它缺乏做事的能力,也就是 Skill,当然在做完事之后最好还能反思学习,不过反思学习不是这篇文章的重点。我们先来看看 Agent 的运行过程:
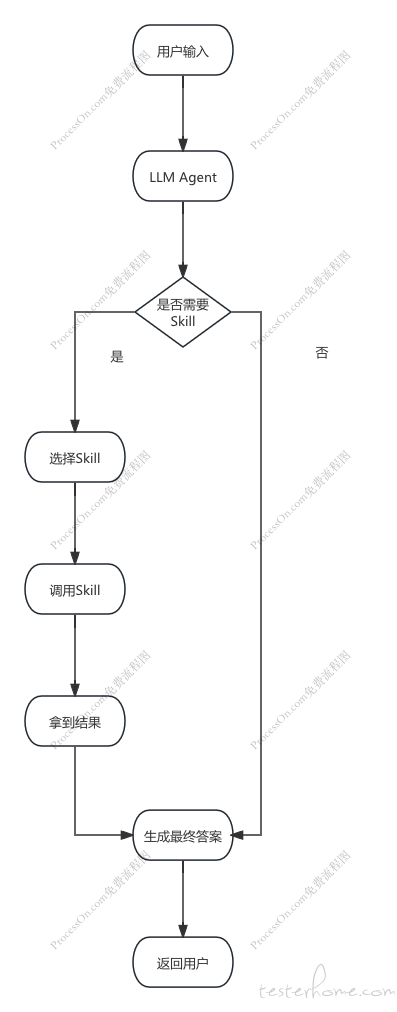
为了让 LLM 能够为我们做事,我们需要为她配置 Skill,这也是本篇文章的重点。
场景分析
再回到造数场景上,以接口造数为例,比如需求是新建一个名称为 Agent 测试,手机号为 13500000001,家庭住址为浙江省杭州市西湖区 xxxx 的用户,那么我们可以调用接口,将 value 值赋值给具体的 key:"name": "Agent 测试","phone": "13500000001","address":"浙江省杭州市西湖区 xxxx 的用户"。同时需要定义一个函数来接受外部参数,调用接口:
def create_user_keyword(name, phone, address):
# 参数封装 #
data = {
"name": name,
"phone": phone,
"address": address
}
# 接口请求 #
api_res = create_user_api(data)
# 参数提取 #
user_id = api_res["data"]
return user_id
但是这样的实现方式完全依赖外部传参了,也就是说必须外部将 name, phone, address 三个字段的数据全部给齐才能调用这个函数,那么再改一改,让它的拓展性好一些:
def create_user_keyword(name=None, phone=None, address=None):
if not name:
name = get_name()
if not phone:
phone = get_phone()
if not address:
address = get_address()
# 参数封装 #
data = {
"name": name,
"phone": phone,
"address": address
}
# 接口请求 #
api_res = create_user_api(data)
# 参数提取 #
user_id = api_res["data"]
return user_id
这样能兼容外部不传值的情况,但是这样写又太费事,需要很多的 if not name 的判断,再优化一次:
# replaceData方案
def create_user_keyword(replaceData={}):
name = get_name()
phone = get_phone()
address = get_address()
# 参数封装 #
data = {
"name": name,
"phone": phone,
"address": address
}
replace_data = {}
for field_code, field_value in data.items():
if field_code in replaceData:
replace_data[field_code] = replaceData[field_code]
# 接口请求 #
api_res = create_user_api(replace_data)
# 参数提取 #
user_id = api_res["data"]
return user_id
一般情况下,编写可重复执行的自动化场景时,为了实现可重复执行的目的,往往也需要在函数内部封装类似于 name = get_name() 的逻辑,避免因为数据重复导致场景化执行异常:
# 场景自动化方案
def create_user_keyword(replaceData={}):
name = get_name()
phone = get_phone()
address = get_address()
# 参数封装 #
data = {
"name": name,
"phone": phone,
"address": address
}
# 接口请求 #
api_res = create_user_api(data)
# 参数提取 #
user_id = api_res["data"]
return user_id
对比 replaceData 方案和场景自动化方案,可以看到只需要修改少量代码就可以快速实现从场景自动化方案至 replaceData 方案的切换。
到了这一步,如果不需要外部替换,那么直接调用 create_user_keyword(),如果需要外部替换时,那么只要设置 replaceData 即可,代码里自动会进行数据替换。通过这样的代码设计,我们只需要聚焦在 replaceData 的处理上即可。
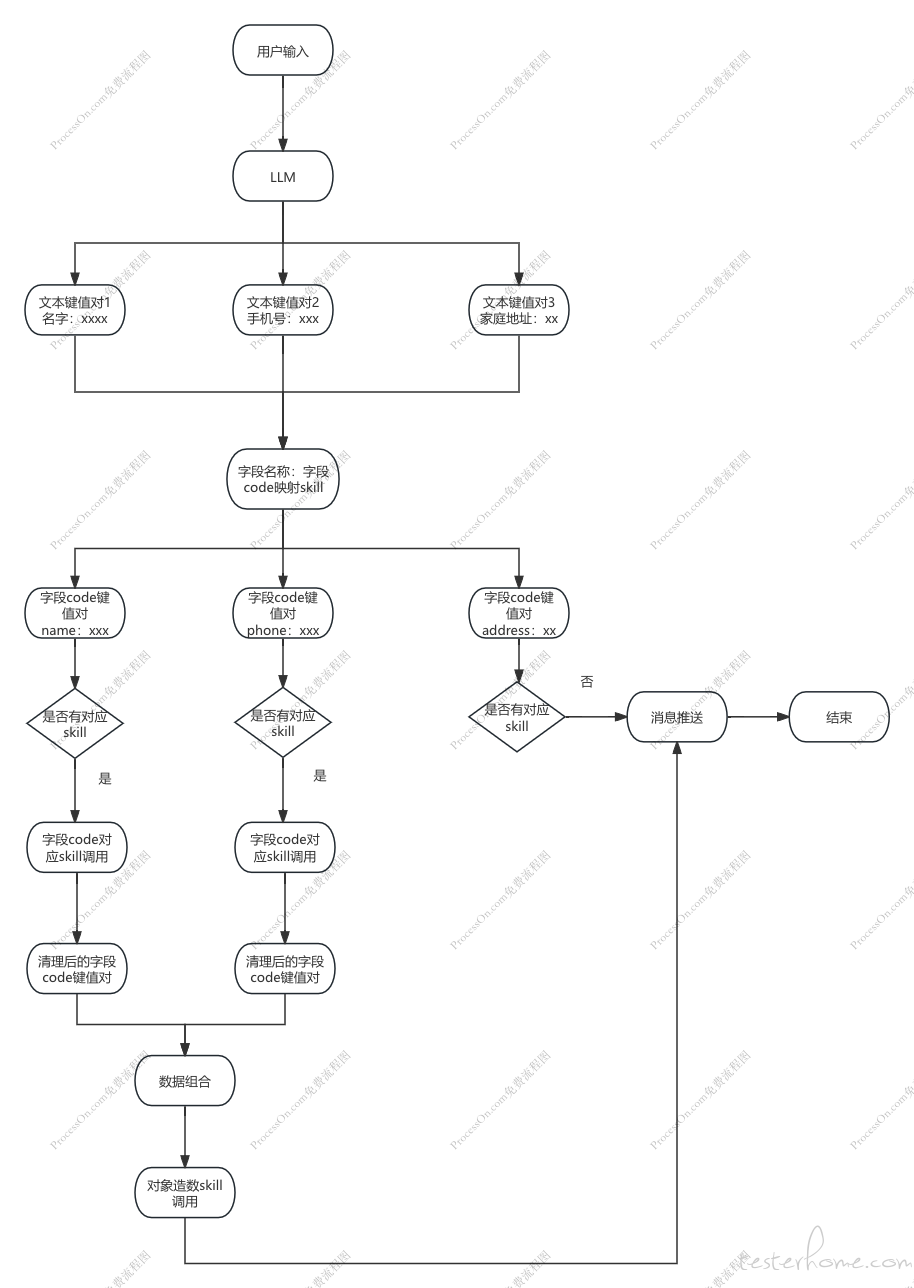
LLM 数据清洗
再谈 Skill 设计前,我们需要回到需求描述上:新建一个名称为 Agent 测试,手机号为 13500000001,家庭住址为浙江省杭州市西湖区 xxxx 的用户。
想要完成一句话造数的逻辑,我们能获得的信息只有这些中文文本,我们需要提取出几个关键键值对:{ 名称:Agent 测试, 手机号: 13500000001, 家庭住址: 浙江省杭州市西湖区 xxxx },需要知道要创建的对象:用户。
常规的字符串处理其实也能实现,比如以"为"作为键值对分隔的依据,但是这种方法约束了很多输入规则,否则无法提取,更无法处理比如用户输入手机为 13500000001,而不是手机号为的情况,字符串的提取方案就会失败。
使用 LLM 就可以比较好的规避这种情况,可以让模型替我们分析输入内容,从中以为、是、=等规则提取键值对,另外在对键名的处理上进行语义匹配,如用户输入的是手机,最后生成键值对时,手机替换成手机号。
那么为什么要做语义匹配,将字段名称手机转为手机号呢?是因为最终为了创建用户记录,我们需要拿到对应的字段 code,也就是 replaceData 方案的核心:
replace_data = {}
for field_code, field_value in data.items():
if field_code in replaceData:
replace_data[field_code] = replaceData[field_code]
需要知道字段的 code,字段的 code 的来源是需要创建的对象,比如这个例子中的用户对象,创建用户对象,需要三个字段:名称、手机号、家庭住址,分别对应的字段 code 为:name,phone,address。所以可以建立一个 field_name:field_code 的映射关系:{ 名称:name,手机号:phone,家庭住址:address}。
那么通过 LLM 解析并进行语义匹配后,得到的字段名称 field_name,通过映射关系可以得到字段 code。
通过以上的处理,完成了将用户描述转为自动化执行传参。
SKILL 封装
在完成了 LLM 数据清洗之后,我们拿到了如下的数据内容:{ name: Agent 测试,phone:13500000001,address:浙江省杭州市西湖区 xxxx },这是用户诉求,是需要替换的字段,即replaceData={ name: Agent 测试,phone:13500000001,address:浙江省杭州市西湖区 xxxx }。
接下来又要思考另一个问题了:输入合法性。以 phone 为例,由于是文本输入,用户可能会输入错误的手机号,例如位数不对、格式错误、号码已被注册等情况。如果是异常情况,为了保证造数过程不受影响,需要在代码中进行非法数据替换,也就是 SKILL 处理逻辑:
# 手机号清理SkILL
def clean_phone_skill(fieldCode, fieldValue):
# 校验手机号格式是否合法
passed = check_phone(fieldValue)
# 格式校验未通过则自动生成新的手机号
if not passed:
phone = get_phone()
else:
phone = fieldValue
# 检验手机号是否被注册
passed = check_phone_exist(phone)
.....
# 封装数据结构
data = {
fieldCode: phone
}
return data
同样的逻辑,对于 name、address 也可以有对应的 SKILL 进行数据清洗处理。
这么封装的优势在哪?可以看到在 clean_phone_skill 的调用过程中,外部只需要传入 fieldCode、fieldValue 即可。若是对 name、address 也做了对应的 SKILL 封装,那么完全可以通过 for 循环 replaceData 进行统一的 SKILL 调用:
# 定义清理后的数据存储
clean_data = {}
for field_code, field_value in repaleceData.items():
# 通过field_code获取对应的skill配置
skill = get_skill_by_field_code(field_code)
if skill:
clean_data = skill(field_code, field_value)
# clean_data的数据结构为 { field_code: clean_field_value }
clean_data.update(clean_data)
我们只需要维护一张 field_code 与 skill 的映射关系数据表即可,同时因为每个造数对象的字段均不相同,需要一个对象 code 与字段 code 的映射关系表:
对象字段映射关系表:obj_code field_name field_code
字段 skill 映射关系表:field_code, skill
PS:由于创建每个对象的接口并不相同,为了避免硬编码,可以在字段 skill 映射关系表中新增一种 field_code=create_object,对应的 SKILL 接收clean_data,调用对象创建接口。同样的可以将对象字段映射关系表也转为一种 SKILL,新增一种 field_code=all_object_fields,对应的 SKILL 返回创建对象所需的所有字段。
整体回顾
总结
本篇文章以造数场景切入 Agent 搭建逻辑,理解了实现原理,再做其他 Agent 也是类似的方案,想做什么事-SKILL,SKILL 触发条件-LLM 数据清洗。若是后续还需要丰富如内容反思等更深层的 Agent 功能,可以在这个基础上继续往后拓展。
如果本篇文章对你有所帮助,请帮忙点赞收藏,谢谢。