往期文章
专栏文章 质量保障系统的落地实践 (一) 概览篇
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 基础信息与缺陷信息设计
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 代码信息设计
专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 基础设计
专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 集成设计
专栏文章 质量保障系统的落地实践 (四) 效能管理设计 - 造数工厂
专栏文章 质量保障系统的落地实践 (五) 可视化设计
专栏文章 质量保障系统的落地实践 (六) 拓展延伸
前言
大家好,我是困学。上次专栏文章发布之后,已经有一段时间没有投稿了,这次给大家带来的主题是:测试岗位如何结合 AI 提效。
阅读完整篇文章,大家会发现,设计思路、实现方案与专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 基础设计的方法是一致的,一定是因地制宜,结合公司实际情况进行考量和落地,没有一种方案可以适配所有场景,这篇文章的目的在于分享案例,一个在我司是怎么依据实际情况设计并落地AI 测试用例以及指标评估的案例。
那么废话不多说,开始切入正文。
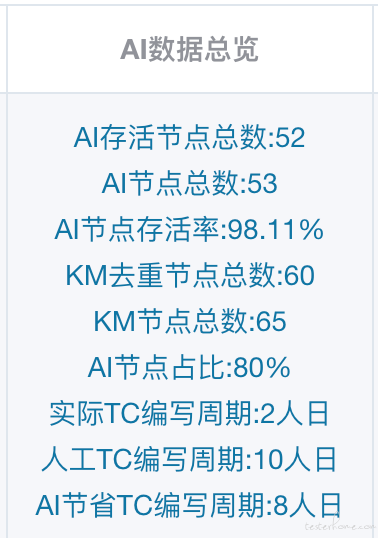
成果展示
贴一张最终指标结果:
哪个阶段使用 AI
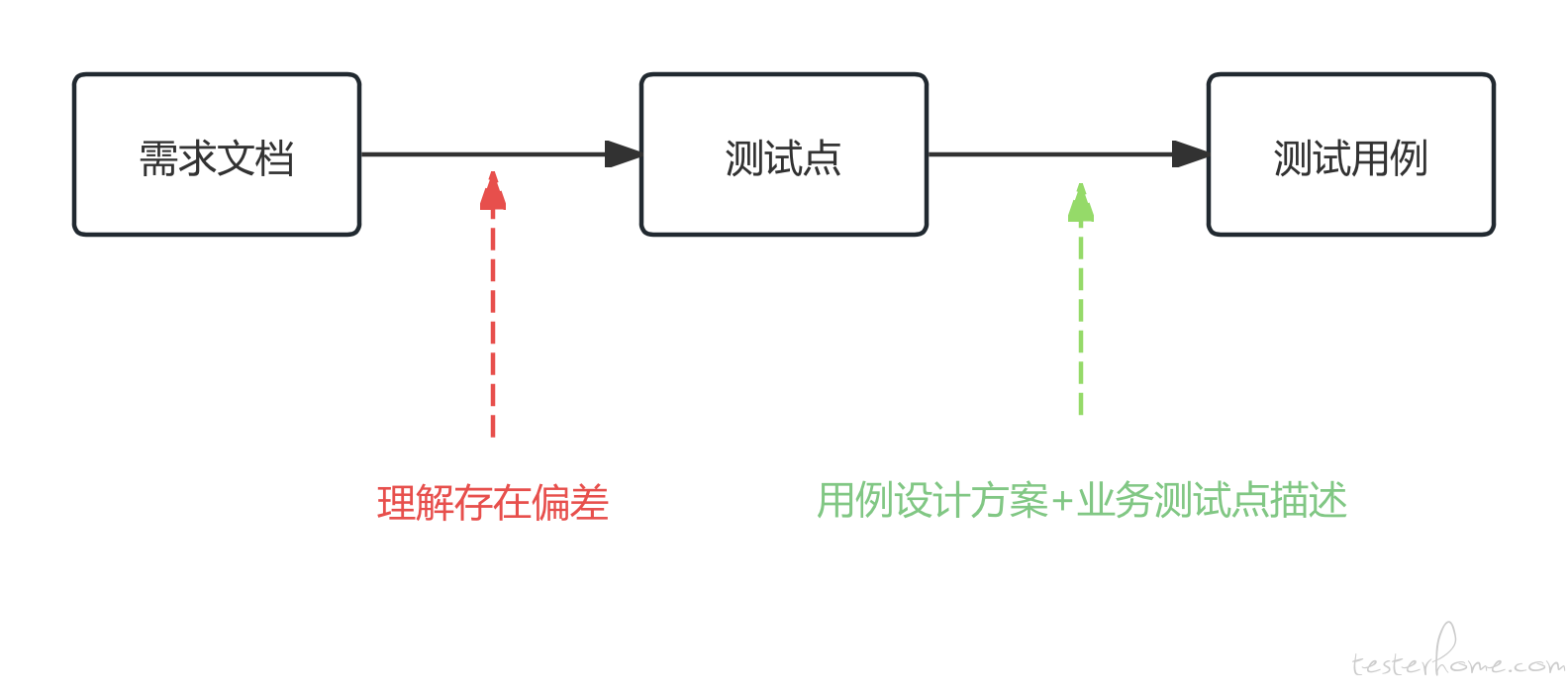
大家入行后,无可避免的工作环节就是编写测试用例,这篇文章就以这个环节作为切入点。
编写测试用例的流程一般是:将产品需求文档描述的场景需求,翻译为测试点,基于测试点构建测试用例。那么 AI 在哪个环节介入比较合适?
最理想的情况是 AI 直接做完整个流程,这样对测试的提效是最高的,测试只需要关注最终产出的测试用例,在 AI 生成的基础上进行修改即可。
实际上,这样的交付是不合适的。由于 AI 并不了解业务上下文 (或者说培训 AI 正确了解业务的上下文并不容易),导致 AI 翻译需求文档,得出测试点的过程,往往与测试的期望会产生偏差,那么基于这份偏差之上产出的测试用例对于测试来说,其可用性是较差的。
目前阶段,AI 介入比较合适的环节是测试点生成测试用例的过程。
比起分析需求文档得出测试点,由测试点派生出测试用例的过程,则相对容易,AI 可以套用测试用例设计方案生成通用测试用例;也可以依据测试点内标注的业务逻辑,生成对应的业务测试用例。
若是 AI 培训得当,需求完档产出测试点的过程,或早或晚的也能交付给 AI 产出。而就本篇文章需要落地的功能来说,测试点生成测试用例、需求文档生成测试用例以上两种方案均能支持。
可行性分析
人工编写或者 AI 提效,根本目的是为了得到一份测试用例,更重要的是一份符合测试组维护格式的用例,大白话就是拿来就可用。比如,公司使用的是 excel 维护测试用例,那么 AI 产出的测试用例就需要是 excel 格式,或者说接近 excel 便于转换成 excel 格式的数据结构;又比如,公司使用的是脑图,那么 AI 产出的测试用例就需要是脑图格式,或者说接近脑图便于转换成脑图格式的数据结构。
那么问题来了,目前主流使用 AI 的方式是交互式界面沟通:

如果直接描述测试点,让 AI 产出测试用例,AI 的输出结果往往是这样的:

内容以文本形式产出,这样的文本内容,是无法称为一份符合测试组维护格式的用例的。
那么,优化一下描述,让 AI 按照指定格式输出:
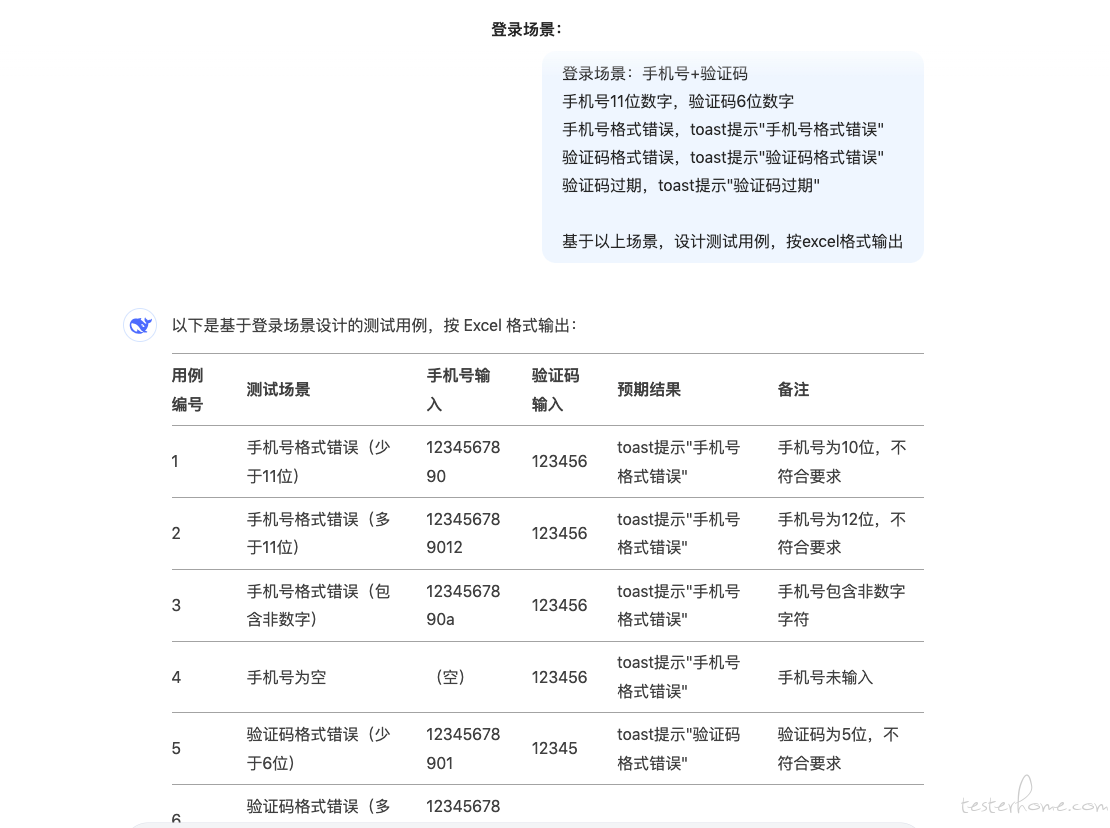

从上面的结果来看,只需要让 AI 输出指定格式的内容,那么就可以得到一份符合测试组维护格式的用例。最为关键的一个环节就打通了,那么这个功能的可行性就具备了。
功能拆解
通过可行性章节的分析,可以得到一个满足格式要求的测试用例结果,剩下的部分就是怎么将功能测试点组装成 prompt 的描述语句交付给 AI 了。
这个环节也可以用比较朴素的方式解决:平铺,即测试点 1:测试点描述 1、测试点 2:测试点描述 2。
这个环节就需要质量保障平台来做了,给予组内测试人员一个交互友好的界面,让测试人员专注录入测试点以及测试点描述:
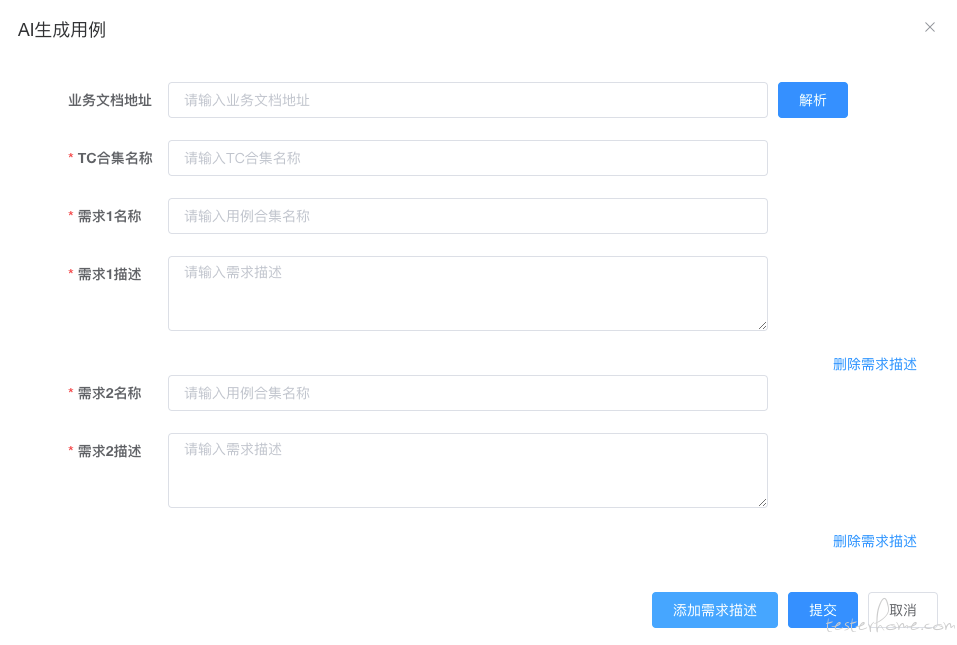
由于交付 AI 生成测试用例,有一个等待过程。从体系功能的完善性上考虑,需要加上通知类的能力,告知测试用例已生成,并提供查看路径,以钉钉通知为例:
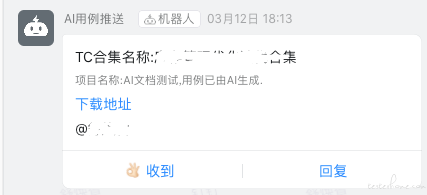
至此,就设计出了 AI 编写测试用例的功能框架:

举个栗子
我司的测试用例情况如下,是基于脑图二次开发后的数据结构,本质是树状 json 结构:
{
"root": {
"data": {
"id": "d8et0ojfdxc0",
"created": 1741835122468,
"text": "AI用例"
},
"children": [
{
"data": {
"id": "d8et6t6iclc0",
"created": 1741835602755,
"text": "测试点"
},
"children": [
{
"data": {
"id": "d8et6ts10940",
"created": 1741835604057,
"text": "用例1",
"usecase": 2
},
"children": [
{
"data": {
"id": "d8et6ug9ex40",
"created": 1741835605522,
"text": "前置条件1",
"usecase": 1
},
"children": [
{
"data": {
"id": "d8et6vld60g0",
"created": 1741835608008,
"text": "操作步骤1",
"usecase": 4
},
"children": [
{
"data": {
"id": "d8et6w4gq9s0",
"created": 1741835609162,
"text": "预期结果1",
"usecase": 3
},
"children": []
}
]
}
]
}
]
},
{
"data": {
"id": "d8et6wqnbbc0",
"created": 1741835610503,
"text": "用例2",
"usecase": 2
},
"children": [
{
"data": {
"id": "d8et73wxtsw0",
"created": 1741835626121,
"text": "前置条件2",
"usecase": 1
},
"children": []
},
{
"data": {
"id": "d8et74eig4g0",
"created": 1741835627184,
"text": "操作步骤2",
"usecase": 4
},
"children": []
},
{
"data": {
"id": "d8et74zcejk0",
"created": 1741835628444,
"text": "预期结果2",
"usecase": 3
},
"children": []
}
]
}
]
}
]
},
"template": "default",
"theme": "fresh-blue-compat",
"version": "1.4.43",
"id": "d8et0ojfdxc0"
}
对应的插件会将这份 json 结构渲染成如下图所示的效果:
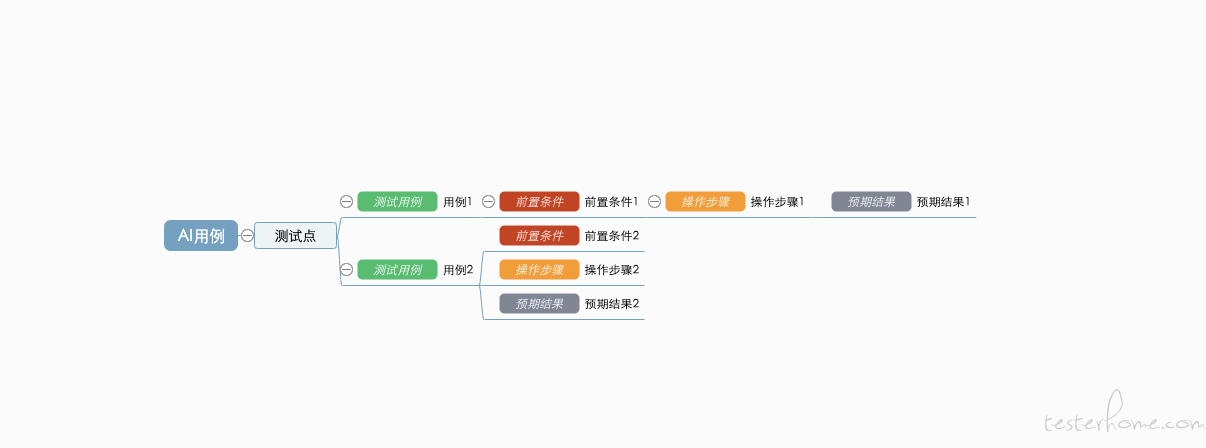
那么,只要最终得到这样结构的 json 数据,就得到了一份符合测试组维护格式的用例。
接下来看怎么描述 prompt,直接上代码:
# 用例整体结构
part1 = {
"root": {
"data": {
"id": "d868fsvqsuw0",
"created": 1740964584421,
"text": f"{root_description}"
},
"children": []
},
"template": "default",
"theme": "fresh-blue-compat",
"version": "1.4.43",
"id": "d868fsvqsuw0"
}
# 测试点结构
part2 = {
"data": {
"id": "d86982ow4yg0",
"created": 1740966799971,
"text": "子需求名称1",
"usecase": 0
},
"children": []
}
# 用例结构
part3 = {
"data": {
"id": "d8698dvdbmg0",
"created": 1740966824307,
"text": "测试用例",
"usecase": 2
},
"children": [
{
"data": {
"id": "d8698efskz40",
"created": 1740966825542,
"text": "前置条件",
"usecase": 1
},
"children": [
{
"data": {
"id": "d8698f7j6u80",
"created": 1740966827219,
"text": "操作步骤",
"usecase": 4
},
"children": [
{
"data": {
"id": "d8698fwp7zc0",
"created": 1740966828741,
"text": "预期结果",
"usecase": 3
},
"children": []
}
]
}
]
}
]
}
# 封装完整prompt
prompt = f"""
"整体输出结构":\n{json.dumps(part1, ensure_ascii=False)}\n
"子需求结构":\n{json.dumps(part2, ensure_ascii=False)}\n
子需求名称替换usecase=0的单元的text字段.\n
最终生成的多个"子需求结构",append至"整体输出结构"["root"]["children"]内.\n
"用例结构":{json.dumps(part3, ensure_ascii=False)}\n
前置条件替换"用例结构"中usecase=1的单元的text字段,\n
用例名称替换"用例结构"中usecase=2的单元的text字段,\n
预期结果替换"用例结构"中usecase=3的单元的text字段,\n
操作步骤替换"用例结构"中usecase=4的单元的text字段.\n
最终生成的多个"用例结构",append至"子需求结构"["children"]内.\n
以上所有数据结构内,若存在created字段,则取生成结构时的时间戳填充.\n
若存在id字段,则随机生成位数相同且唯一的字符串填充.\n
"根需求名称":{root_description},\n
以下为多个子需求描述:\n{child_description_str},\n
根据上文分析出来的所有测试点,生成符合上述格式要求的测试用例.\n
特别注意,确保最终输出结果为json格式,内部不要有注释,不要省略内容.\n
最后只需要返回"整体输出结构"即可,请按照json格式输出。.
"""
# 剔除无关空格
prompt = re.sub(r'\s+', ' ', prompt).strip()
实现思路比较直白,将几个元素全部剥离:1、用例整体结构;2、测试点结构;3、用例结构。(这里多说一嘴,用例的结构,由于每个人编写的习惯不同,所以格式五花八门,既然设计系统功能,就不要考虑那么多种格式的情况。以固定格式产出后,由测试自行调整即可。),然后让 AI 构建出用例结构,按层级依次添加至测试点结构,测试点结构依次添加至用例整体结构中,最终返回用例整体结构,按 json 格式即可。
指标评估
以上部分已经完成了功能搭建,接下来该考虑指标的问题了。大家在工作中都会面临这个问题:你做的功能也好,设计的系统也好,能带来什么价值?这个价值,如何被量化?
落地之前,务必先想好数据量化,有了数据,才能做后续的评估,才有后续的改进,形成一个正反馈的闭环。
划重点了,数据,数据,还是 (国粹和谐)数据

那么就这个 AI 用例功能来说,数据该怎么沉淀呢?指标该怎么设计呢?
回答这个问题之前,先回到原点,测试用例原本是由测试手工完成的,为什么要引入 AI?除了当前万物 all in AI 的理由外,更重要的是为测试人员提效,省去部分甚至全部编写测试用例的工作量。那么最好的指标就是计算出:AI 编写测试用例的方式到底比全手动编写测试用例的方式能效提高了多少?
比如说,在引入了 AI 用例编写的功能后,测试产出测试用例需要 8 个人日。而 AI 产出的测试用例占比有 30%,那么人工比例就占了 70%,而由于 AI 生成是不占用时间的,所以可以认为这 70% 的人工比例是 8 个人日。那么如果纯人工编写就需要:8 / 0.7 = 11.43 人日,AI 提效的人日就为 8 / 0.7 * 0.3 = 3.43 人日。(看到这篇文章的你未必就会认同这种算法,此处只是举个例子,你完全可以按照你的实际情况设计量化指标。)
顺着这个逻辑下来,现在问题就到了怎么计算 AI 产出的测试用例占比的问题了。要知道占比,首先得知道哪些测试用例是由 AI 产生的,很自然的想到用打标的方式。而往往我们编写测试用例的软件所生成的数据结构是外部很难直接修改的,例如:
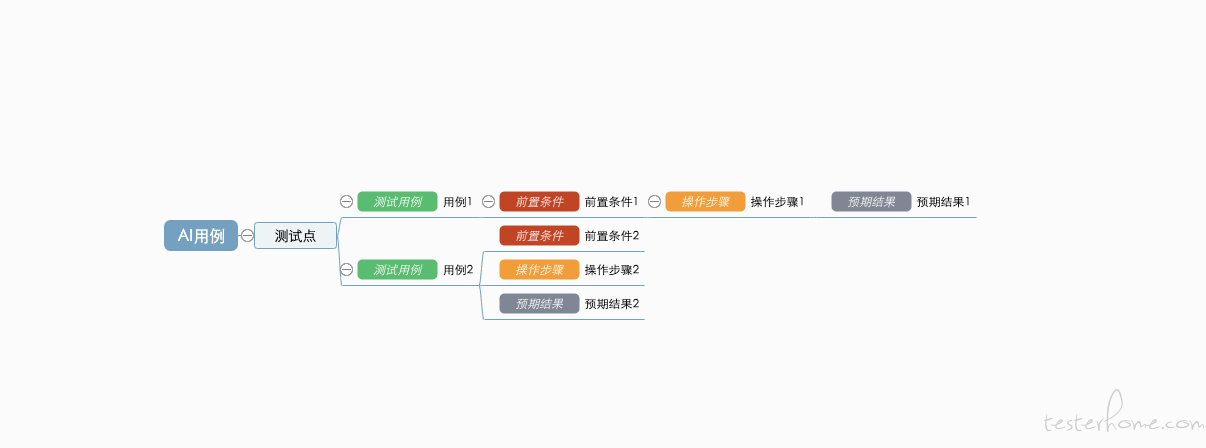
如上图,我司编写测试用例的软件,打开后已经被渲染,并且在这个软件基础上所有的操作都已经被二次开发后固定下来了,如以下结构,是没有办法外部干预的 (除非你能让开发这个软件的人支持你修改):
{
"data": {
"id": "d8et6vld60g0",
"created": 1741835608008,
"text": "操作步骤1",
"usecase": 4
},
"children": [
{
"data": {
"id": "d8et6w4gq9s0",
"created": 1741835609162,
"text": "预期结果1",
"usecase": 3
},
"children": []
}
]
}
所以基本上不考虑在这一侧做数据打标的工作,那就只能在 AI 测想办法了。看到这里,聪明的你大概率反应过来了,其实只需要在给 AI 的数据结构上直接加上参数就可以了,因为这个数据结构是我们自己设计的,问题解决:
{
"data": {
"id": "d8et6vld60g0",
"created": 1741835608008,
"text": "操作步骤1",
"usecase": 4,
"is_ai": true # 直接打标签
},
"children": [
{
"data": {
"id": "d8et6w4gq9s0",
"created": 1741835609162,
"text": "预期结果1",
"usecase": 3,
"is_ai": true # 直接打标签
},
"children": []
}
]
}
数据打标的问题也解决之后,AI 产出的所有测试用例部分全部标记了 is_ai=true,而测试人员拿到了这份测试用例后,可能会发生新增、编辑、删除等操作得到一份系统测试用例,最终上传回质量保障平台。要做的就是设计一种方法,穷尽每个测试用例的节点,分别统计出 AI 产生的节点集合 setA,系统测试用例的节点集合 setB,两者取交集,得到存活的 AI 节点 setC,那么 AI 产出的占比就可以计算:len(setC) / len(setB)。
得到占比之后,后续统计 AI 提效的人日也好,其他指标也罢,就都方便了。
结尾
这篇文章到这里就结束了,感谢阅读这篇文章的你,如果觉得对你有一些启发的话,辛苦点赞收藏,不胜感激。
收到过私信评论,写到现在的专栏文档,很多功能比如 CI,又比如造数,都是基于 RF 实现,很多阅读文章的测试同学,他们日常并不使用 RF,那这些功能设计对他们还有用吗?
这里我想说一句,虽然功能不能直接照搬,但是不妨看看思路,用这些文章内的设计思路去举一反三,去设计出一套适配于自己当前环境的功能。实践是检验真理的唯一标准,所谓的测试开发,质量保障,他们做的事也是在这一件件日常工作的思考和实践中逐渐完善自己的能力,适配自己的岗位。
多思考,多实践,与君共勉。